使用Pandas也可以进行数据可视化
在本文中,我们介绍使用 Pandas 进行数据可视化的基础知识,包括创建简单图、自定义图以及使用多个DF进行绘图。

Numpy中数组和矩阵操作的数学函数
Numpy 是一个强大的 Python 计算库。它提供了广泛的数学函数,可以对数组和矩阵执行各种操作。本文中将整理一些基本和常用的数学操作。
R实战 | Nomogram(诺莫图/列线图)及其Calibration校准曲线绘制
R实战|Nomogram(诺莫图/列线图)及其Calibration校准曲线绘制Nomogram,中文常称为诺莫图或者列线图。简单的说是将Logistic回归或Cox回归的结果进行可视化呈...
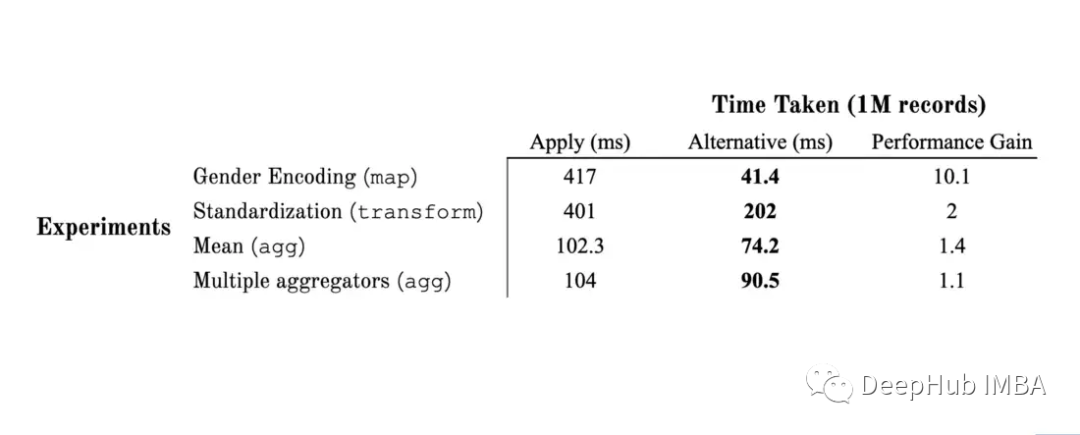
Pandas的apply, map, transform介绍和性能测试
在这篇文章中,我们将通过一些示例讨论apply、agg、map和transform的预期用途。
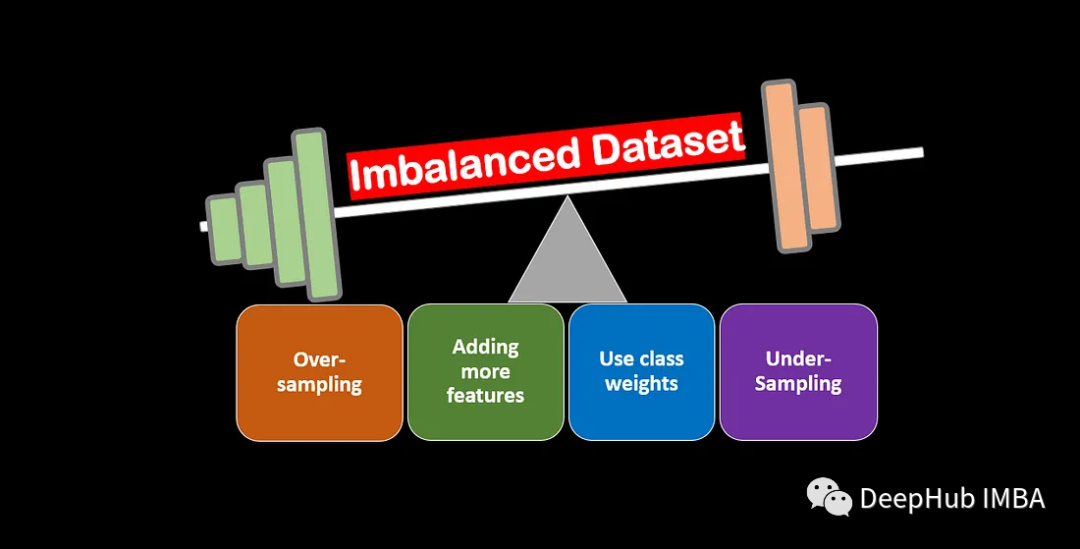
不平衡数据集的建模的技巧和策略
在本文中,我们将讨论处理不平衡数据集和提高机器学习模型性能的各种技巧和策略
监控Python 内存使用情况和代码执行时间
我的代码的哪些部分运行时间最长、内存最多?我怎样才能找到需要改进的地方?”在本文中总结了一些方法来监控 Python 代码的时间和内存使用情况。

这20个Pandas函数可以完成80%的数据科学工作
Pandas 是数据科学社区中使用最广泛的库之一,本文将提供最常用的 Pandas 函数以及如何实际使用它们的样例。
机器学习(二):人工智能发展历程
如何描述人工智能自1956年以来60余年的发展历程,学术界可谓仁者见仁、智者见智。测试者与被测试者(一个人和一台机器)隔开的情况下,通过一些装置(如键盘)向被测试者随意提问。的测试者不能确定被测试者是人还是机器,那么这台机器就通过了测试,并被认为具有。马文·闵斯基(Marvin Minsky,人工智
数据挖掘-数据的预处理(三)
准备数据:如何处理出完整、干净的数据?原始的数据本身也存在着各种各样的问题:如不够准确、格式多样、部分特征缺失、标准不统一、特殊数据、错误数据等。
数据挖掘-模型怎么解决业务需求(五)
从项目的需求发起,到数据准备,再到模型训练、评估、上线,这些环节都遇到了什么样的问题,我们解决了什么问题,又有哪些问题尚未解决,在时间等条件充裕的情况下还可以做哪些尝试。介绍了一些关于模型保存、模型优化、模型部署的思路。讲解了关于项目总结,乃至模型监控等内容。
【通信原理】揭开傅里叶级数与傅里叶变换的神秘面纱
傅里叶变换和傅里叶级数是有史以来最伟大的数学发现之一。它们可以帮助我们将函数分解成其基本成分。它们揭示了任何数学函数的基本模块,但是傅里叶分析的公式对于连高数中sin2x的积分都不熟悉的工科白菜来说简直就是连多看它一样的勇气都没有,我想这就是为什么复杂的傅里叶分析成为大学中通信专业的疑难杂症的主要原
数据挖掘-模型的评估(四)
模型的各种评估指标,从一个混淆矩阵出发,衍生出一系列的准确度评测对模型泛化能力进行评估介绍了如何在数据上进行一些优化从而减少评估时产生误差。

Pandas处理大数据的性能优化技巧
Pandas是Python中最著名的数据分析工具。本文将介绍一些使用Pandas处理大数据时的技巧,希望对你有所帮助
数据挖掘-KNN算法+sklearn代码实现(六)
KNN最邻近分类算法的实现原理:为了判断未知样本的类别,以所有已知类别的样本作为参照,计算未知样本与所有已知样本的距离,从中选取与未知样本距离最近的K个已知样本,根据少数服从多数的投票法则(majority-voting),将未知样本与K个最邻近样本中所属类别占比较多的归为一类。
1000个大数据/人工智能毕设选题推荐
正值毕业季我看到很多同学都在为自己的毕业设计发愁Maynor在网上搜集了1000个大数据的毕设选题,希望对大家有帮助~适合大数据毕业设计的项目,完全可以作为本科生当前较新的毕业设计题目选择方向。
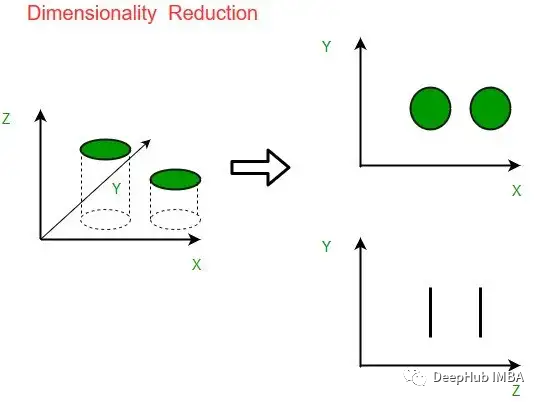
降维和特征选择的对比介绍
在machine learning中,特征降维和特征选择是两个常见的概念,在应用machine learning来解决问题的论文中经常会出现。特征降维和特征选择的目的都是使数据的维数降低,使数据维度降小。但实际上两者的区别是很大,他们的本质是完全不同的。
【通信原理】确知信号的性质分析与研究
在前面一文中已经详细且生动的解释了傅里叶变换和傅里叶级数的内容,【通信原理】揭开傅里叶级数与傅里叶变换的神秘面纱,而在今天这篇中有些公式你可能会产生疑惑,基本上需要用到傅氏变化的知识,可能需要你自行了解一下过程或参考一下上一篇文章的内容并加以理解。本文从通信系统中确知信号出发,分析了能量信号、功率信
PIE Engine机器学习遥感影像监督分类全流程(附源码)
本文中,作者基于PIE Engine遥感云计算平台进行遥感影像监督分类,详细介绍了遥感影像分类的数据预处理、模型训练及结果可视化。
spss分析方法-聚类分析
聚类分析是根据研究对象的特征,按照一定标准对研究对象进行分类的一种分析方法。下面我们主要从下面四个方面来解说: 一、实际应用 聚类分析的目标就是在相似的基础上收集数据来分类。聚类源于很多领域,包括数学,计算机科学,统计学,生物学和经济学。在不同的应用领域,很多聚类技术都得到了发展,这些技术方法被用
ROC曲线绘制(Python)
我看谁还不会用Python画出ROC曲线!!!



