
✨前言
在数学建模比赛中,分类也是我们最常见的问题之一,关于分类这块,现在最火热的**垃圾分类**其实也是属于我们**分类模型**中的一种,我们可以根据每个垃圾的一系列指标将其进行分成不同的类别,接下来就详细讲一下如何利用**SVM**和**随机森林**去解决该类问题,并对两种智能算法的用法进行区分和总结!
数学建模专栏:数学建模从0到1
👉🏻历史回顾👈🏻
数学建模入门篇零基础如何入门数学建模?_小羊不会飞的博客长三角实战篇长三角数学建模------赛后总结_小羊不会飞的博客数学建模(一):插值数学建模(一):插值_小羊不会飞的博客-CSDN博客数学建模(二):优化数学建模(二):优化_小羊不会飞的博客-CSDN博客数学建模(三):预测数学建模(三):预测_小羊不会飞的博客-CSDN博客
🔍1、什么是分类 ?
分类在**百度百科**上的定义:“**分类**就是通过比较事物之间的相似性,把具有某些共同点或相似特征的事物归属于一个不确定集合的**逻辑方法**”。
应用到现实生活中就是我们日常的垃圾分类
📑2、SVM(支持向量机)算法
✏️2.1代码
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
res = xlsread('数据集.xlsx');
temp = randperm(357);
P_train = res(temp(1: 240), 1: 12)';
T_train = res(temp(1: 240), 13)';
M = size(P_train, 2);
P_test = res(temp(241: end), 1: 12)';
T_test = res(temp(241: end), 13)';
N = size(P_test, 2);
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input );
t_train = T_train;
t_test = T_test ;
p_train = p_train'; p_test = p_test';
t_train = t_train'; t_test = t_test';
c = 10.0;
g = 0.01;
cmd = ['-t 2', '-c', num2str(c), '-g', num2str(g)];
model = svmtrain(t_train, p_train, cmd);
T_sim1 = svmpredict(t_train, p_train, model);
T_sim2 = svmpredict(t_test , p_test , model);
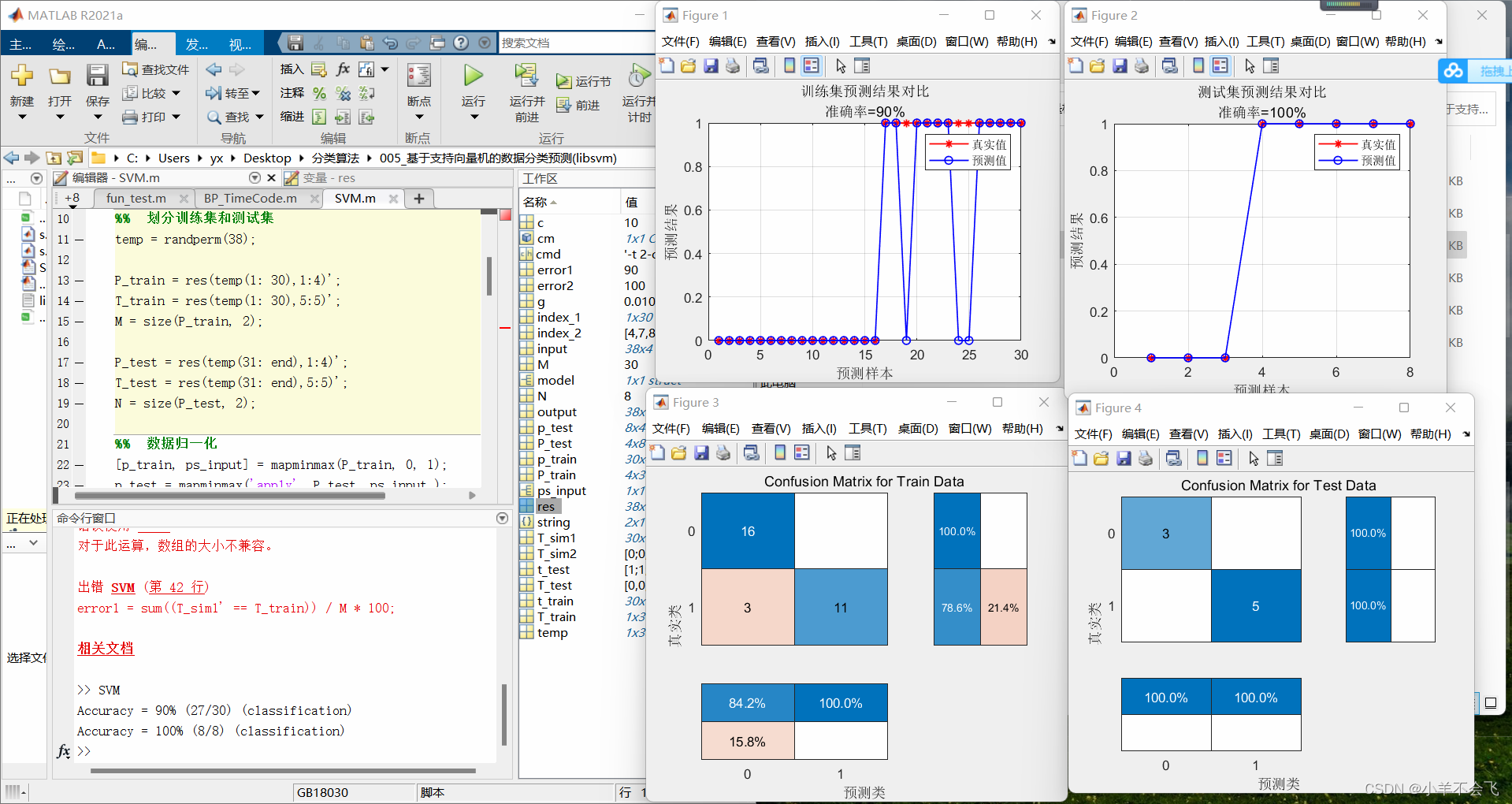
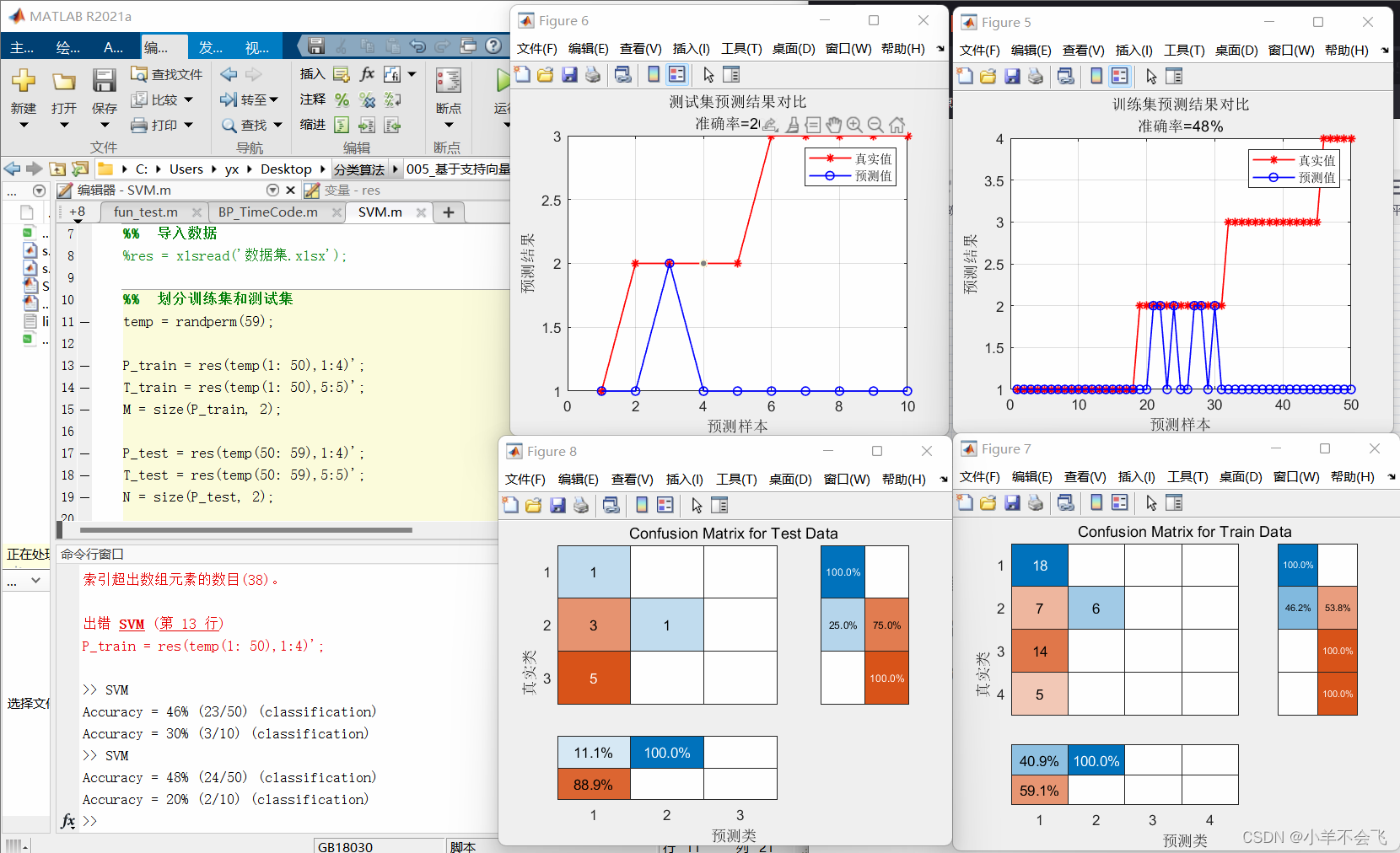
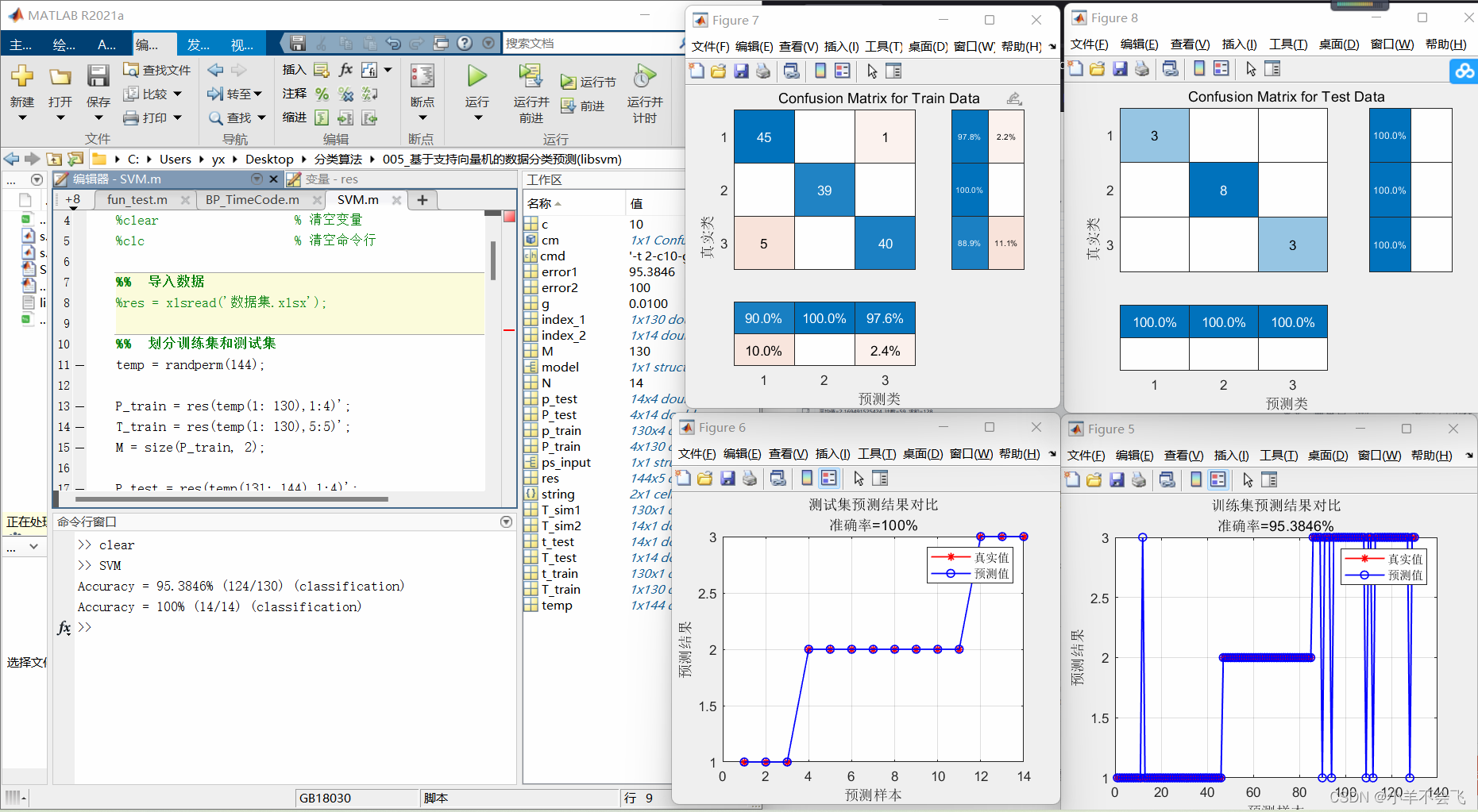
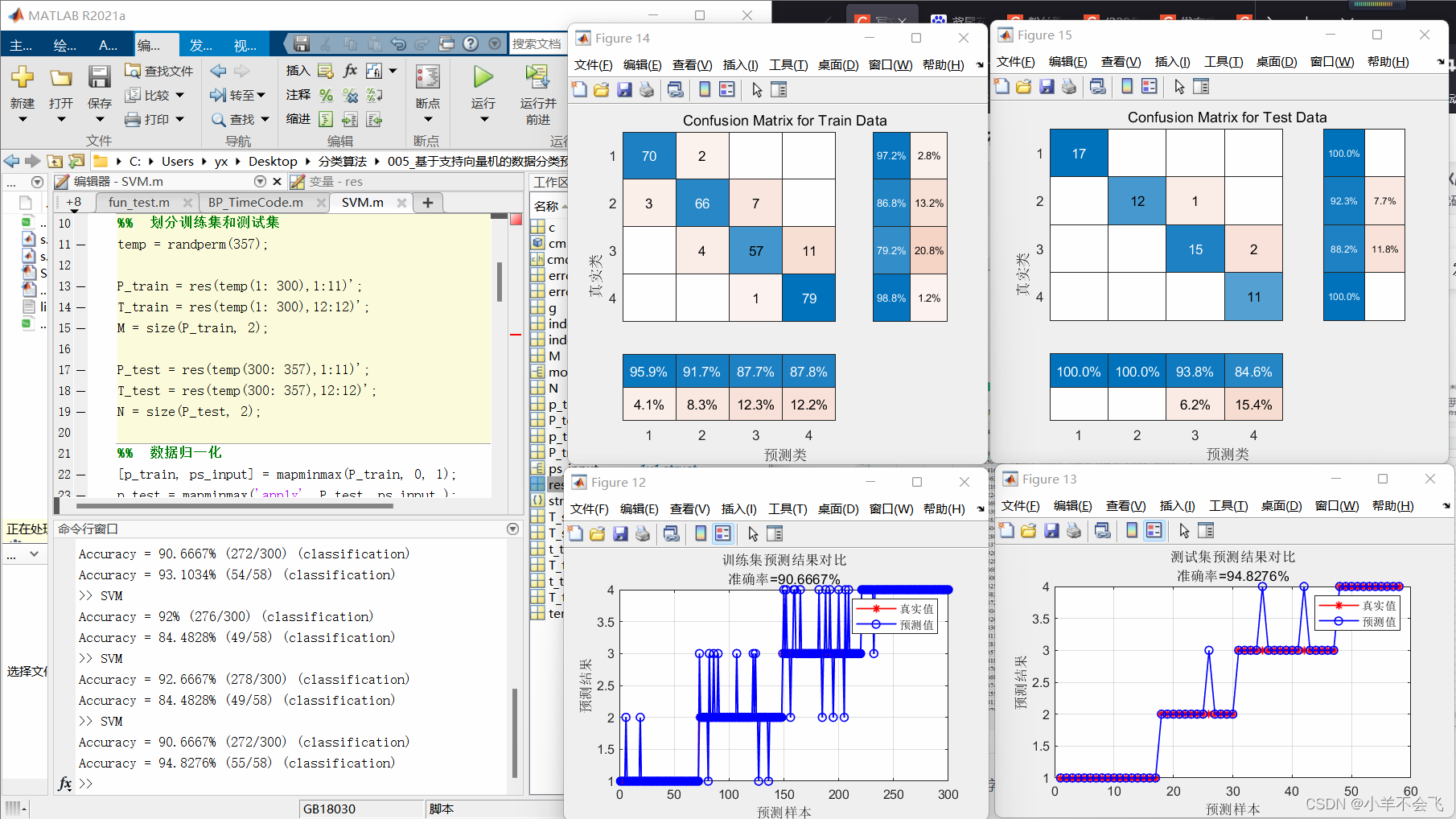
error1 = sum((T_sim1' == T_train)) / M * 100;
error2 = sum((T_sim2' == T_test )) / N * 100;
[T_train, index_1] = sort(T_train);
[T_test , index_2] = sort(T_test );
T_sim1 = T_sim1(index_1);
T_sim2 = T_sim2(index_2);
...........
✏️2.2代码和原理的讲解
这块内容,博主我讲的可能不太明白,参考一下其它优秀博主的文章:
SVM算法—原理讲解_测试狗一枚的博客-CSDN博客_svm算法原理
🗝️2.3二分类水果
🗝️2.4多分类水果
🗝️2.5多分类鸢尾花
🗝️2.6其它数据分类
📑3、随机森林算法
✏️3.1代码
%% 清空环境变量
%warning off % 关闭报警信息
%close all % 关闭开启的图窗
%clear % 清空变量
%clc % 清空命令行
%% 导入数据
%res = xlsread('数据集.xlsx');
P_train = res(temp(1: 50), 1: 4)';
T_train = res(temp(1: 50), 5)';
M = size(P_train, 2);
P_test = res(temp(51: end), 1: 4)';
T_test = res(temp(51: end), 5)';
N = size(P_test, 2);
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input );
t_train = T_train;
t_test = T_test ;
p_train = p_train'; p_test = p_test';
t_train = t_train'; t_test = t_test';
trees = 50;
leaf = 1;
OOBPrediction = 'on';
OOBPredictorImportance = 'on';
Method = 'classification';
net = TreeBagger(trees, p_train, t_train, 'OOBPredictorImportance', OOBPredictorImportance, ...
'Method', Method, 'OOBPrediction', OOBPrediction, 'minleaf', leaf);
importance = net.OOBPermutedPredictorDeltaError; % 重要性
t_sim1 = predict(net, p_train);
t_sim2 = predict(net, p_test );
T_sim1 = str2num(cell2mat(t_sim1)); %训练集的预测值
T_sim2 = str2num(cell2mat(t_sim2)); %测试集的预测值
error1 = sum((T_sim1' == T_train)) / M * 100 ;
error2 = sum((T_sim2' == T_test )) / N * 100 ;
figure
plot(1 : trees, oobError(net), 'b-', 'LineWidth', 1)
legend('误差曲线')
xlabel('决策树数目')
ylabel('误差')
xlim([1, trees])
grid
figure
bar(importance)
legend('重要性')
xlabel('特征')
ylabel('重要性')
[T_train, index_1] = sort(T_train);
[T_test , index_2] = sort(T_test );
T_sim1 = T_sim1(index_1);
T_sim2 = T_sim2(index_2);
................
✏️3.2算法简介
随机森林顾名思义,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类(对于分类算法),然后看看哪一类被选择最多,就预测这个样本为那一类。
✏️3.3实现过程
随机森林中的每一棵分类树为二叉树,其生成遵循自顶向下的递归分裂原则,即从根节点开始依次对训练集进行划分;在二叉树中,根节点包含全部训练数据, 按照节点纯度最小原则,分裂为左节点和右节点,它们分别包含训练数据的一个子集,按照同样的规则节点继续分裂,直到满足分支停止规则而停止生长。若节点n上的分类数据全部来自于同一类别,则此节点的纯度I(n)=0,纯度度量方法是Gini准则,即假设P(Xj)是节点n上属于Xj 类样本个数占训练。
📑具体实现过程如下:
(1)原始训练集为N,应用bootstrap法有放回地随机抽取k个新的自助样本集,并由此构建k棵分类树,每次未被抽到的样本组成了k个袋外数据;
(2)设有mall个变量,则在每一棵树的每个节点处随机抽取mtry个变量(mtry n mall),然后在mtry中选择一个最具有分类能力的变量,变量分类的阈值通过检查每一个分类点确定;
(3)每棵树最大限度地生长, 不做任何修剪;
(4)将生成的多棵分类树组成随机森林,用随机森林分类器对新的数据进行判别与分类,分类结果按树分类器的投票多少而定。
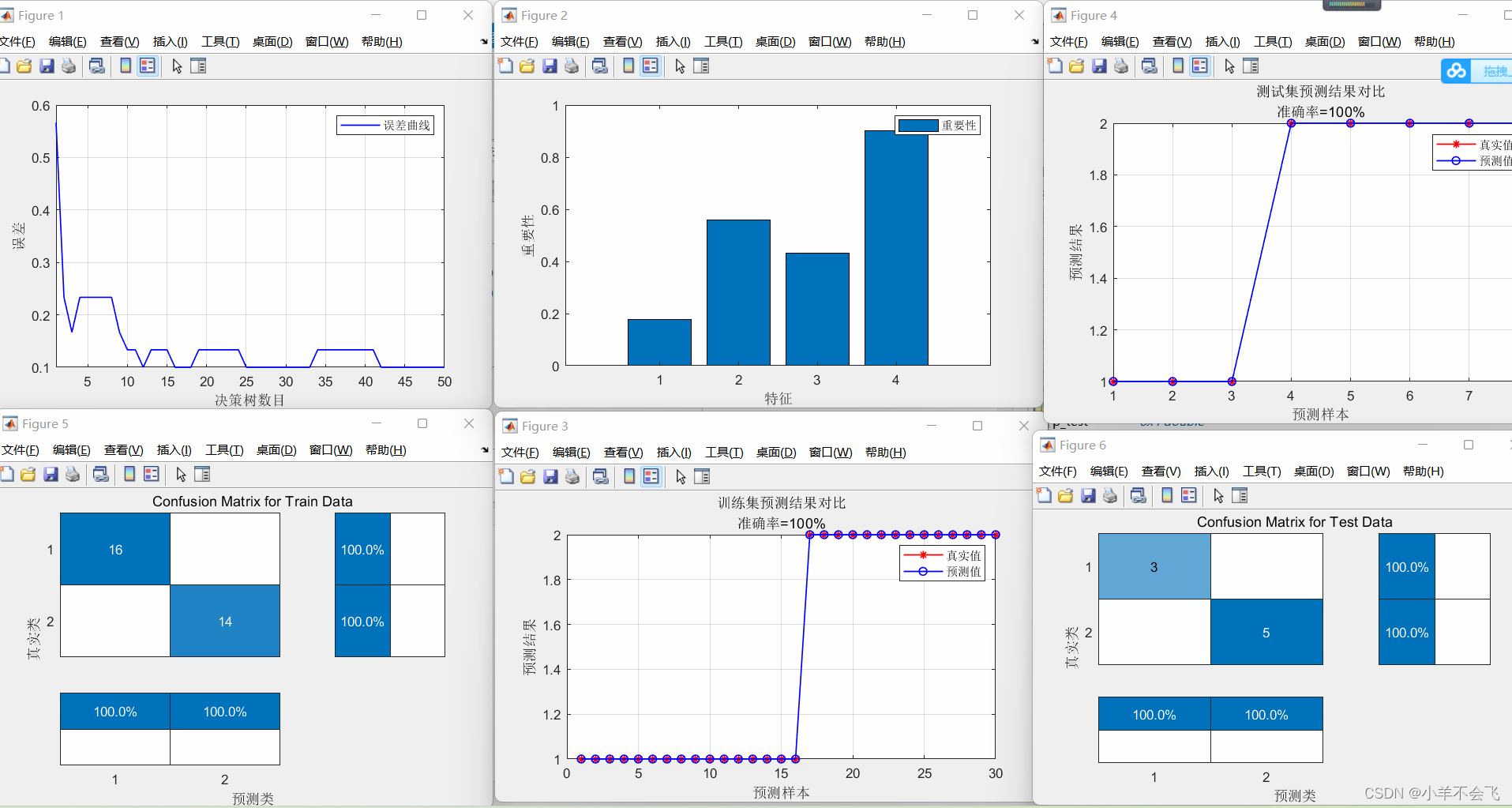
🗝️3.3二分类水果
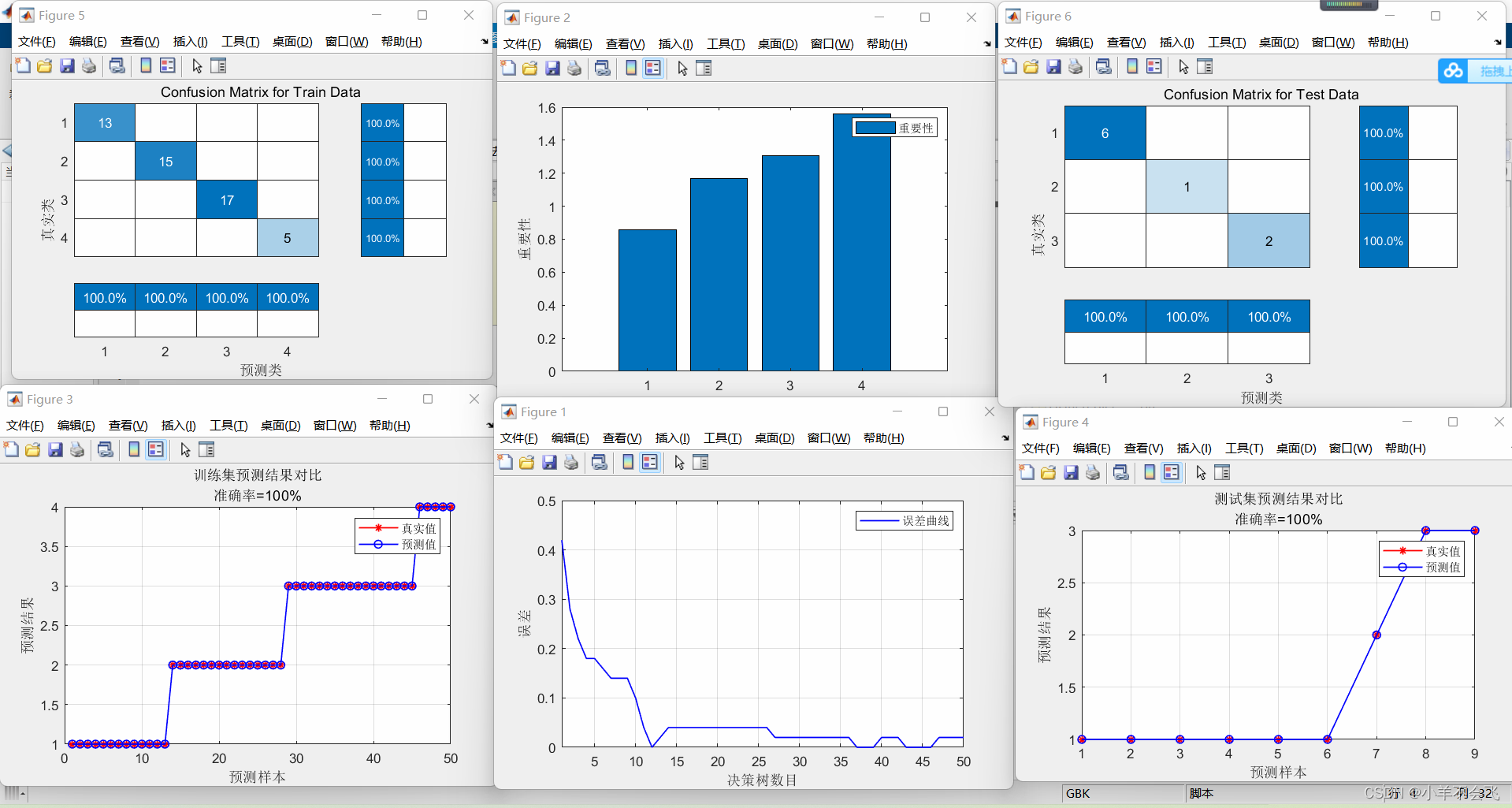
🗝️3.4多分类水果
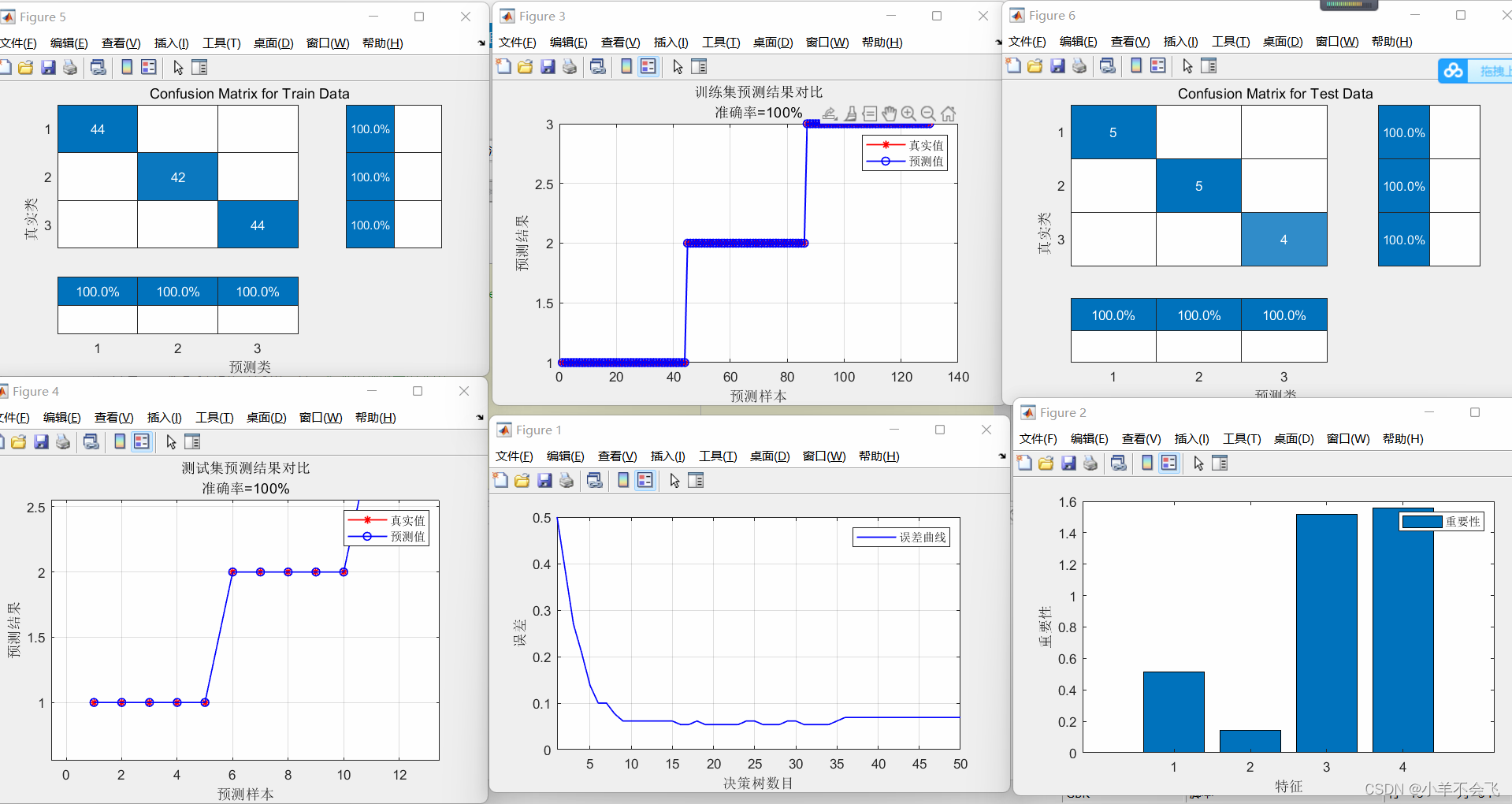
🗝️3.5多分类鸢尾花
🗝️3.6其它数据分类

🀄结果分析:
随机森林分类的效果明显优于SVM(支持向量机)
📖4、总结
📝1、在处理多指标分类模型的问题中,SVM(支持向量机)和随机森林都可以去解决这一系列问题,btw从上述实战中我们不难发现,随机森林的准确率达到了95%+,在跟前辈的交流中也了解到,随机森林确实比SVM更适合做多指标分类!
上述结果出现的概念:
1.混淆矩阵:[机器学习笔记] 混淆矩阵(Confusion Matrix)
版权归原作者 小羊不会飞 所有, 如有侵权,请联系我们删除。