一文速学-XGBoost模型算法原理以及实现+Python项目实战
集成模型Boosting补完计划第三期了,之前我们已经详细描述了AdaBoost算法模型和GBDT原理以及实践。通过这两类算法就可以明白Boosting算法的核心思想以及基本的运行计算框架,余下几种Boosting算法都是在前者的算法之上改良得到,尤其是以GBDT算法为基础改进衍生出的三种Boost
第十一届泰迪杯数据挖掘挑战赛-产品订单数据分析B题(完整代码)--数据处理--第一部分(下一部分请看下一博客)
第十一届泰迪杯数据挖掘挑战赛-B题,数据处理以及特征序列增加
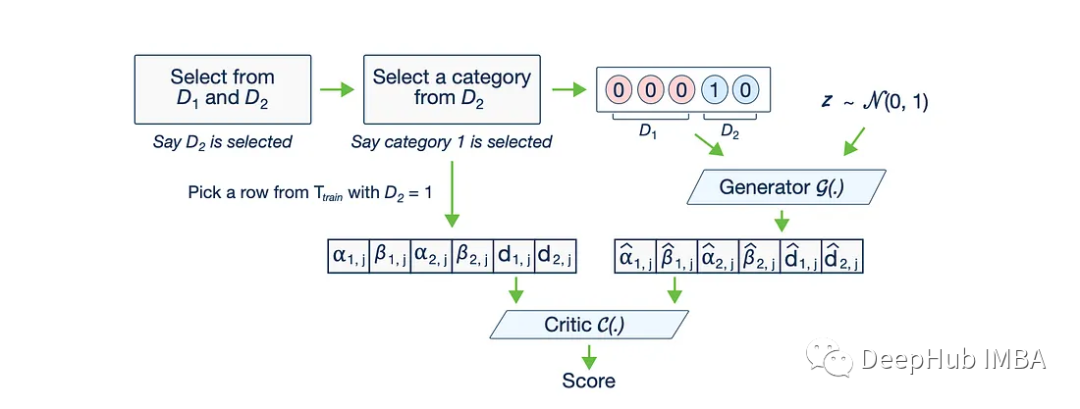
用CTGAN生成真实世界的表格数据
随着CLIP和稳定模型的快速发展,图像生成领域中GAN已经不常见了,但是在表格数据中GAN还是可以看到它的身影。
时间序列—显著相关性和滞后性分析_python
本文讲述了两个时间序列(信号)的相关性分析,可以利用相关性分析进行特征筛选。此外本文还讲了怎么判断时间序列的滞后性的方法。
SPSS:主成分分析确定不同指标权重
SPSS实现主成分分析确定指标权重
AI模型大杀器----Amazon SageMaker 实现高精度猫狗分类
Hello大家好,我是Dream。 最近受邀参与了 亚马逊云科技【云上探索实验室】 活动,基于他们的sagemaker实现了机器学习中一个非常经典的案例:猫狗分类。最让我惊喜的是的模型训速度比想象中 效果要好得多,而且速度十分迅速,而且总体感觉下来整个过程十分便利,使用起来也是得心应手。 那接下来跟
Python【二手车价格预测案例】数据挖掘
Python二手车价格预测案例数据挖掘
Python统计学11——分位数回归
Python实现分位数回归
【数据挖掘实战】——基于水色图像的水质评价(LM神经网络和决策树)
背景和挖掘目标1、问题背景从事渔业生产有经验的从业者可通过观察水色变化调控水质,用来维持养殖水体生态系统中浮游植物、微生物类、浮游动物等合理的动态平衡。由于这些多是通过经验和肉眼观察进行判断,存在主观性引起的观察性偏倚,使观察结果的可比性、可重复性降低,不易推广应用。当前,数字图像处理技术为计算机监
K210项目实战(口罩检测系统和垃圾分类系统)
在前面我学习了使用K210训练模型做目标检测,然后也学会了使用K210做串口通信,学完之后我就把K210丢在箱子里吃灰了,因为学校疫情原因,两年一届的电赛很遗憾不能参加了,然后我就想拿他做个口罩检测系统(检测到没戴口罩可以语言提醒),这个真的好简单,哈哈哈,接下来加点难度,做个垃圾分类系统,半天就做
seaborn库学习----分布图displot、histplot、kdeplot、ecdfplot
提供的api说明displotFigure-level interface for drawing distribution plots onto a FacetGrid. 图形级界面,用于在FacetGrid上绘制分布图。histplotPlot univariate or bivariate h
数据挖掘(全书的知识点都包括了)
数据挖掘第一章1.什么是数据挖掘数据挖掘是从数据中,发现其有用的信息,从而帮助我们做出决策(广义角度)数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识,寻找其规律的技术,结合统计学、机器学习和人工智能技术的综合的过程
R数据分析:临床预测模型中校准曲线和DCA曲线的意义与做法
之前给大家写过一个临床预测模型:R数据分析:跟随top期刊手把手教你做一个临床预测模型,里面其实都是比较基础的模型判别能力discrimination的一些指标,那么今天就再进一步,给大家分享一些和临床决策实际相关的指标,主要是校准calibration和决策曲线Decision curve ana
stata基础--回归,画散点图,异质性分析
利用stata的内部数据来进行回归代码:sysuse autosysuse dir /*可以看到所有的数据*/su price mpg foreignreg price mpgpredict u,residual /*新变量u=每一个观测的残差*/ /*生成残差u需要紧接着回归*/mpg和pric
数学建模-回归分析(Stata)
X是自变量,Y是因变量。目的是通过X去预测Y。一般处理模型像:期末成绩分析,Y是成绩,X是性别、是否是班干部、平时作业完成度等自变量。银行借贷成功率分析等问题。
机器学习中的数学原理——F值与交叉验证
通过这篇博客,你将清晰的明白什么是F值、交叉验证。这个专栏名为白话机器学习中数学学习笔记,主要是用来分享一下我在 机器学习中的学习笔记及一些感悟,也希望对你的学习有帮助哦!感兴趣的小伙伴欢迎私信或者评论区留言!这一篇就更新一下《 白话机器学习中的数学——F值与交叉验证》
【线性回归类算法的建模与评估】
讲解线性回归类算法的建模与评估
机器学习篇-指标:AUC
AUC是什么东西?AUC是一个模型评价指标,只能够用于二分类模型的评价,对于二分类模型来说还有很多其他的评价指标:比如:logloss,accuracy,precision在上述的评价指标当中,数据挖掘类比赛中,AUC和logloss是比较常见的模型评价指标那么问题来了||ヽ( ̄▽ ̄)ノミ|Ю为啥是
【人工智能大作业】A*和IDA*搜索算法解决十五数码(15-puzzle)问题 (Python实现)(启发式搜索)
【人工智能】启发式搜索算法,A*和IDA*搜索算法解决十五数码(15-puzzle)问题Python实现,理论算法分析与实验证明
GAN(生成对抗网络)Matlab代码详解
这篇博客主要是对GAN网络的代码进行一个详细的讲解:首先是预定义:clear; clc; %%%clc是清除当前command区域的命令,表示清空,看着舒服些 。而clear用于清空环境变量。两者是不同的。%%%装载数据集train_x=load('Normalization_wbc.txt');%



