
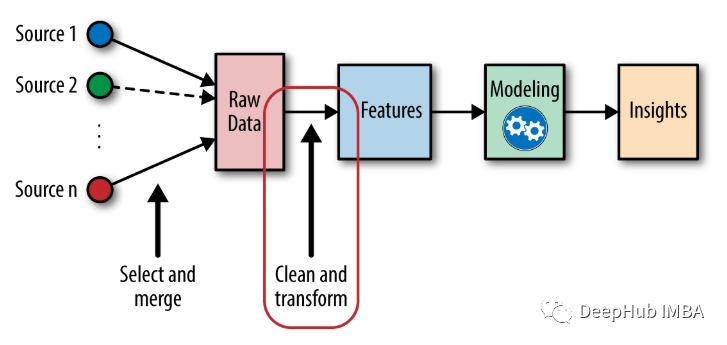
使用Dask,SBERT SPECTRE和Milvus构建自己的ARXIV论文相似性搜索引擎
通过矢量相似性搜索,可以在〜50ms内响应〜640K论文上的语义搜索查询
【机器学习算法】关联规则2 FPgrowth法算法
Apriori算法的提升,Fpgrowth
【机器学习算法】关联规则-1 关联规则的概念,Apriori算法,实例和优缺点
关联规则的概念,关联规则的两个指标,支持度和置信度,apriori的算法
机器学习_LGB调参汇总(开箱即食)
在数据层面的一些正负采样,业务层面一些数据筛选,以及异常值的处理后。我们进行模型训练,同时需要对模型进行参数的调整,以提升模型的精度。笔者就一些现有的调参框架进行汇总。

10快速入门Query函数使用的Pandas的查询示例
pandas.的query函数为我们提供了一种编写查询过滤条件更简单的方法,特别是在的查询条件很多的时候,在本文中整理了10个示例,掌握着10个实例你就可以轻松的使用query函数来解决任何查询的问题。
【机器学习算法】集成学习-1 强学习器的融合学习
集成学习认为多个决策者比一个决策者可能会做出更好的决策,各种模型的整合也是如此,机器学习这种多样化就是通过集成学习的技术实现的。
【4天快速入门Python数据挖掘之第1天】Matplotlib的使用
matplotlib —— 一个画二维图表的 Python 库,专门用于开发 2D 图表(包括 3D 图表),使用起来及其方便,以渐进、交互方式实现数据可视化

30 个数据工程必备的Python 包
在本文中,将介绍一些非常独特的并且好用的 Python 包,它们可以在许多方面帮助你构建数据的工作流。
特征工程中的缩放和编码的方法总结
数据预处理是机器学习生命周期的非常重要的一个部分。特征工程又是数据预处理的一个重要组成,在本文中主要介绍特征缩放和特征编码的主要方法。
100天精通Python(数据分析篇)——第48天:数据分析入门知识
数据分析入门知识:1. 为什么要学数据分析?2. 数据分析的概念3. 数据分析涉及哪些能力4. 数据分析的流程5. Python做数据分析学什么?
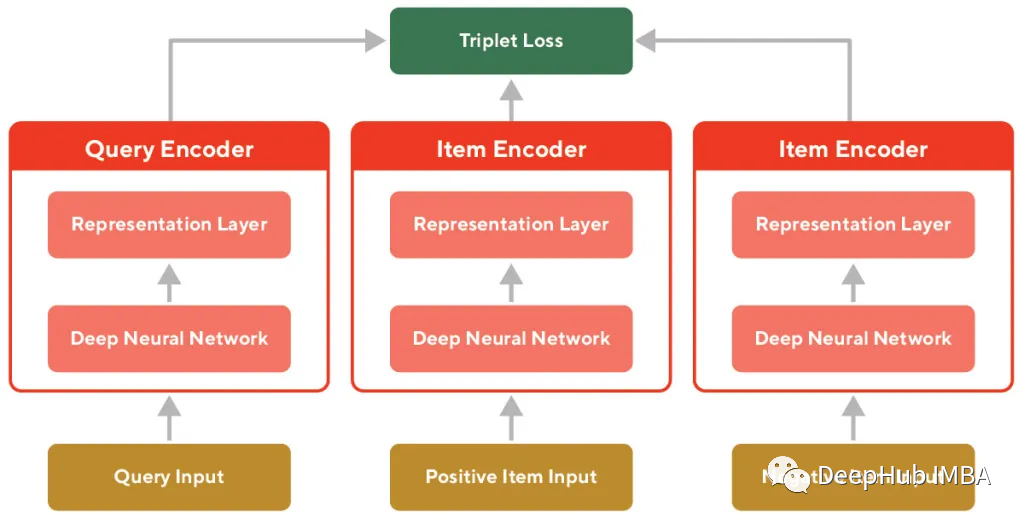
使用三重损失和孪生神经网络训练大型类目的嵌入表示
在这篇文章中,描述了一种通过在网站内部的用户搜索数据上使用自监督学习技术来训练高质量的可推广嵌入的方法。
【机器学习算法】决策树-5 CART回归树法,M5回归树算法对CART算法改进了什么
数据挖掘十大必学算法之一:决策树CART的回归树内容,已经CART加强版的M5算法内容
两个简单的代码片段让你的图表动起来
使用 plotly 和 gif库 在 Python 中创建动画图
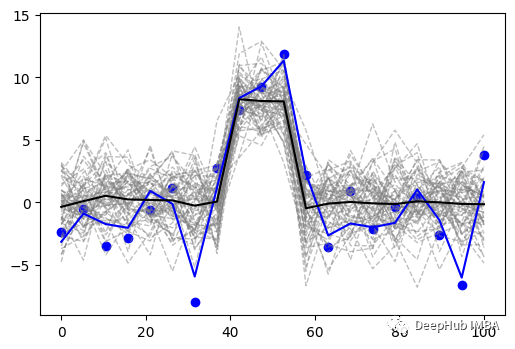
通过哈密顿蒙特卡罗(HMC)拟合深度高斯过程,量化信号中的不确定性
本文将介绍如何使用深度高斯过程建模量化信号中的不确定性
图灵奖得主LeCun指明AI未来的出路在于自主学习,这家公司已踏上征途
通用人工智能的困境:举一不能反三“通用人工智能”(AGI,也即强人工智能)的出现尚显遥远。究其原因,在于当前AI仍高强度依赖于海量的训练数据,与千万乃至上亿级数的被动式监督学习训练,才可实现一点点人类认知能力的复用。当前AI可使用强大算力处理人类无法顾及的千亿级数据,但在主动的领悟能力方面,可能连2
100天精通Python(爬虫篇)——第43天:爬虫入门知识
一、爬虫概述 1. 为什么要学习爬虫? 2. 爬虫与Python 3. 爬虫合法吗? 4. 爬虫的矛与盾 5. 爬虫原理图 and 流程图二、相关技术介绍 1. HTML 与 CSS 2. URL网址解释 3. HTTP 与 HTTРS
快速上手数据挖掘
数据挖掘是一项应用十分广泛的技术,它能够从历史数据中发掘出有用的规律,然后运用规律去做预测。比如在金融机构中通过挖掘历史用户信息和违约之间的规律进行风险预测,防止坏帐;在营销场景中可以通过挖掘客户消费行为规律寻找潜在客户,进行精准营销;在企业生产中,可以根据历史生产数据来预测良品情况,从而改进工艺降
Machine Learning with Matminer(附代码)
Machine Learning with Matminer(附代码),Matminer是一个开源的、基于python的软件平台,以促进数据驱动的方法来分析和预测材料的属性。
时间序列—相关性和滞后性分析_python
本文讲述了两个时间序列(信号)的相关性分析,可以利用相关性分析进行特征筛选。此外本文还讲了怎么判断时间序列的滞后性的方法。
PIE Engine机器学习遥感影像监督分类全流程(附源码)
本文中,作者基于PIE Engine遥感云计算平台进行遥感影像监督分类,详细介绍了遥感影像分类的数据预处理、模型训练及结果可视化。



