
前言
千呼万唤始出来啊家人们,真的是累死我了兄弟们,我昨天上了一天的班,晚上还整这个国赛敲代码敲到晚上2点才睡觉,搞得我也像是在比赛一样,麻了。不过一直写到现在也答应了很多小伙伴今天上午一定要写完E题第一问的思路和解析的,现在终于是把全部第一问的问题都梳理清楚,思路也理明白了。周预测模型其实小伙伴们不用限制的那么死,无非就是时序预测模型,周数简化甚至一般的机器学习模型都能直接预测,只不过效果不会有时序预测模型做的那么好,会产生数据波动。不懂什么时序预测模型的小伙伴可以去看我的个人专栏哈:
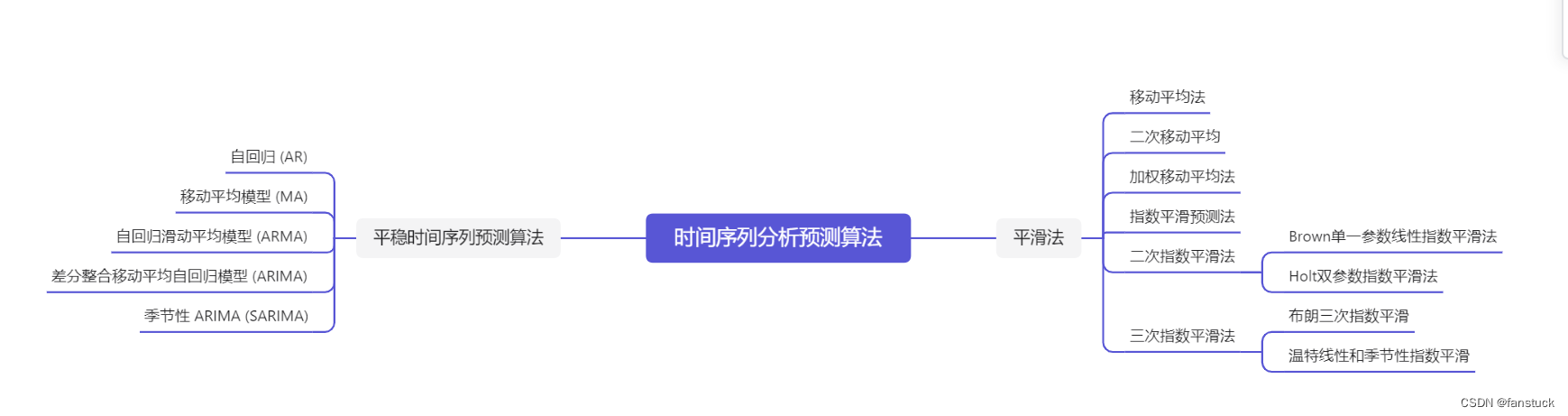
基于大多数模都是小白新手上路我采用了一种可以说得上是十分亲民的时序预测方法也能很好的达到时序预测模型的效果。粉丝内部可以得到更多的思路和代码,期待各位的关注。好了废话不多说我们开始继续解答吧!
博主会长期维护博文,有错误或者疑惑可以在评论区指出,感谢大家的支持。
一、六种物料挑选
六种物料挑选我在上篇文章:
2022年全国大学生数学建模竞赛E题目-小批量物料生产安排详解+思路+Python代码时序预测模型(二)_fanstuck的博客-CSDN博客
可以说的上是很明确了,大家只要按照这个思路走肯定是不会有问题挑选出明确的六种物料的。
但是还是有很多小伙伴不是很明白这里我再多嘴几句话:
秩和比的值能够包含所有评价指标的信息,显示出这些评价指标的综合水平,RSR值越大表明综合评价越优。
但有时还需实事求是地加以限定.例如病床利用率、平均病床周转次数一般可作高优指标理解,但过高也不见得是好事。
除区分高优指标与低优指标外,有时还要运用不分高优与低优及其种种组合形式,例如在疗效评价中,微效率可视为偏高优(高优与不分的均数),不变率可视为稍低优(偏低优与“不分”的均数)。总之,编秩的技巧问题要从业务出发来合理地解决。综合评价的方法一般是主客观结合的,方法的选择需基于实际指标数据情况选定,最为关键的是指标的选取,以及指标权重的设置,这些需要基于广泛的调研和扎实的业务知识,不能说单纯的从数学上解决的。
主要的是权重问题。
二、周数处理
第一问的难点可以说有三个:
- 数据处理获取特征数据集,挑选出六种最高权重的物料
- 周数处理获得时序数据集
- 建立周预测模型评价数据集
目前我的文章思路一和二已经完美解答了第一个难点,现在这篇文章来处理接下来这两个难点。
我们根据挑选的六种物料的数据可以发现,每个物料的周数都不是连续的,
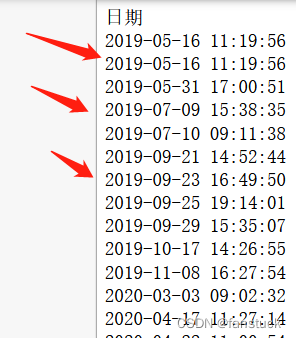
每个物料需求都是有时间断层的,这里我们需要拥有一定的时序数据处理能力,我这里全部都是使用的Pandas处理,对Pandas时间序列数据处理不是很熟练的小伙伴可以去追更我的Pandas专栏,里面有非常详细的处理Pandas时间序列数据的文章,对付这个问题十分够用了。但是得到了周数还是会存在一些小问题:
- 如相同周数的需求量如何处理?
- 2020、2021、2022的年份周数又得如何计算呢?
- 年度首周和尾周应该如何得到正确周数呢?
这些都是需要考虑的点。我们需要将周数和年份一起结合起来判断,得到正确每年周数,从而获得真实周数。这里给大家展示一下我的处理结果:
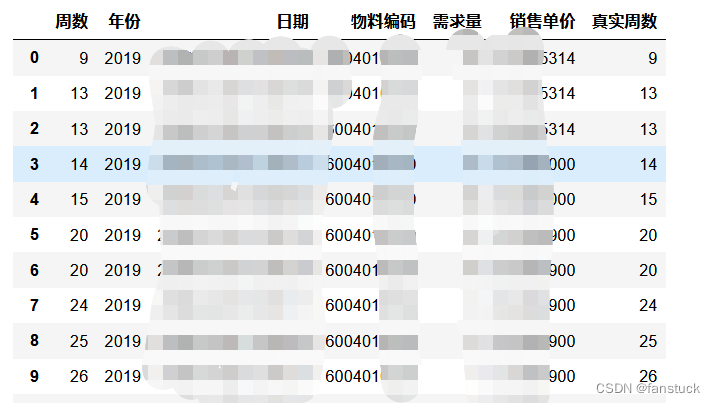
我们可以根据Pandas的强大功能提取出周数和年份结合判断得到真实周数。
这里还需要处理一下真实周数相同的问题,大家一直对这个处理完全没有头绪,昨天晚上微信都被打爆了就是这个问题。Pandas如何处理两列的关系呢?这里我直接给出源码好吧:
pre_1=df_get_re1[['需求量','真实周数']]
def get_pre(df):
list_q=[]
m=1
for i in range(pre_1.shape[0]):
sum=df['需求量'][i]
for j in range(i+m,pre_1.shape[0]):
if df['真实周数'][i]==df['真实周数'][j]:
sum=sum+df['需求量'][j]
list_q.append(sum)
return list_q
当然这是我早期测试代码,现在已经优化不需要这么复杂,大家可以参考这个思路。得到最终的时序预测数据集了:
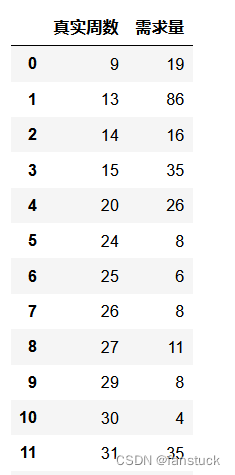
我已经写到这么细化的份上了,求个大家的关注和点赞不过分吧!以后的数模比赛只要我还有时间肯定会第一时间写出免费开源思路,你们的关注和点赞就是我写作的动力!!!
三、时序预测模型
既然得到了最终预测数据,那么时间预测模型也是呼之欲出了。
这里有相当多的时序预测模型可以供给大家选择:
简单套用一下即可,但是选择模型之前我们仍然需要观测一下数据集,是否符合我们使用时序预测模型的类型,可以绘制散点图来更加直观的观看:
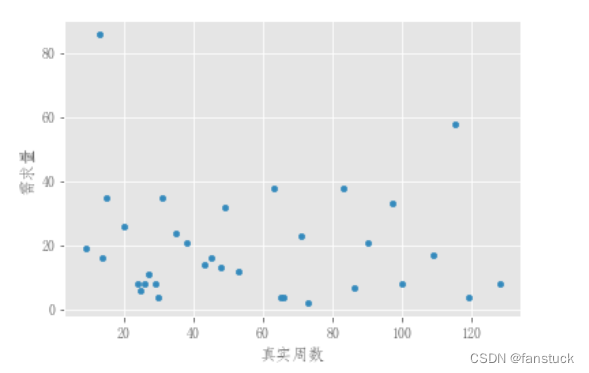
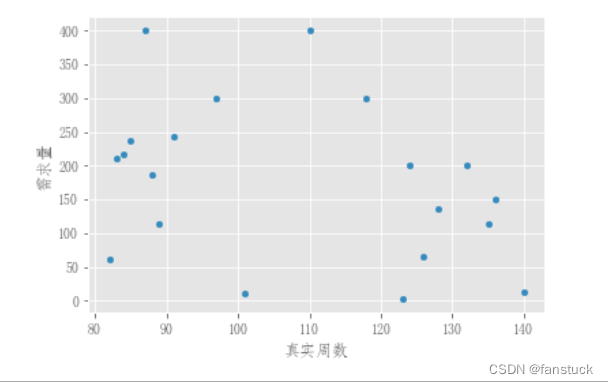
我们会发现这些数据都十分的离散,随着周数波动的十分跳跃,这里我们要根据实际情况选择更加贴切实际的时序预测模型,数据决定了模型的好坏。
模型预测结果
模型挑选这里需要考虑的点比较多,一般都是由经验和数据集主导,这里直接跳过了,直接呈上结果:
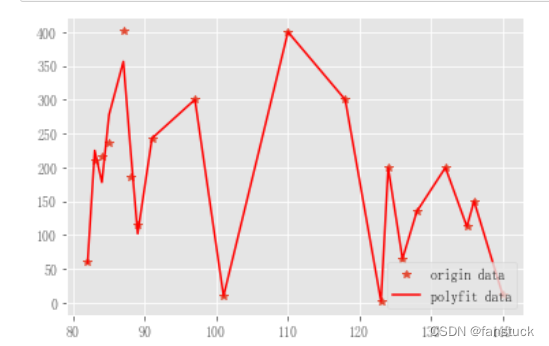
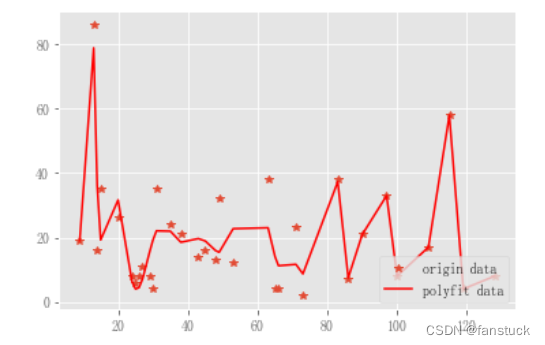
效果还是十分不错的。
这里有很多评价模型效果的指标,比如残差值和残差率都可以考虑。
好了第一问已经完全结束了,马上开始大家万众期待的第二问解析!!!
建模的部分后续将会写出,想要了解更多的欢迎加博主微信,免费获取更多细化思路+模型!
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。
版权归原作者 fanstuck 所有, 如有侵权,请联系我们删除。