【车牌识别】基于GRNN广义回归神经网络的车牌识别matlab仿真
matlab2013bGRNN广义回归神经网络的理论基础是非线性核回归分析,非独立变量y相对于独立变量x的回归分析实际上是计算具有最大概率值的y。设随机变量x和y的联合概率密度函数为f (x ,y),已知x的观测值为X,则y相对于X的回归,即条件均值为:对于未知的概率密度函数f (x, y),可由x
独孤九剑第七式-物以类聚 人以群分(K-means模型)
🐱文章适合于所有的相关人士进行学习🐱🐶各位看官看完了之后不要立刻转身呀🐶🐹期待三连关注小小博主加收藏🐹🐴小小博主回关快 会给你意想不到的惊喜呀🐴各位老板动动小手给小弟点赞收藏一下,多多支持是我更新得动力!!!文章目录🌀前言🌀K-means模型讲解⚡️K-means模型思想⚡️K-
Python最全学习路线
Python学习路线
2022电工杯AB题思路分析
将在本文更新电工杯AB题思路我们还有全部的解题思路讲解视频以及代码!竞赛题目一般来源于电工、近代数学及经济管理等方面,经过适当的简化、加工的实际问题,主要包括:1.信息处理问题;2.控制理论及应用问题;3.运筹与决策问题;4.电路与电磁场理论相关问题。参赛学生应学过普通高校的工科数学课程及相关专业的
独孤九剑第五式-朴素贝叶斯模型
💐文章适合于所有的相关人士进行学习💐🍀各位看官看完了之后不要立刻转身呀🍀🌿期待三连关注小小博主加收藏🌿🍃小小博主回关快 会给你意想不到的惊喜呀🍃各位老板动动小手给小弟点赞收藏一下,多多支持是我更新得动力!!!文章目录🏰前言🏰朴素贝叶斯模型理论讲解⛺️模型思想⛺️贝叶斯理论讲解⛺️
四大名著知识图谱可视化
四大名著人物关系分析实践,通过知识图谱可视化,从二维视觉突破到2.5维视觉,整体提升数据关系感知能力。
机器学习入门-一元线性回归模型的骚操作
🐸文章适合于所有的相关人士进行学习🐸🐶各位看官看完了之后不要立刻转身呀🐶🐼期待三连关注小小博主加收藏🐼🐤小小博主回关快 会给你意想不到的惊喜呀🐤文章目录🚩前言🚩一元线性回归模型讲解☁️我们可能会遭遇的问题☁️线性回归模型🚩数学公式推导☁️公式推导☁️代码介绍及实现🌊jupyt
520还不知道选啥礼物?让AHP帮你选一个最符合你的吧~(附Python代码
520了,不管是男码,女码友,都应该收到一份示爱,也希望各位单身码友今年脱单,不单身的码友和另一半感情越来越好,不管在什么地方都有人爱你,我爱你们~
KNN算法数字识别完整代码——打开就可以跑
目录1、原理2、数据集3、代码以及注释1. 数据准备:2. 构建训练数据集:3. 测试集数据测试:4、运行结果5、总结6、致谢1、原理邻近算法,或者说K最近邻(KNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是K个最近的邻居的意思,说的是每个
基于聚类算法的城市餐饮数据分析与店铺选址
餐饮业生意好坏的影响因素通常有很多,包括店铺菜系、口味、服务态度、周边环境、人口密度、所在区域、人均消费等等方面。本项目以上海城市为例,对其餐饮业消费数据进行统计分析,从三个维度“口味”、“人均消费”、“性价比”对不同菜系进行横向比较。针对某一商铺类型,将上海划分成格网空间,做空间指标评价,基于聚类
轻松学习学 Pandas:17个函数操作可以这样学起来
Pandas是数据挖掘常见的工具,掌握使用过程中的函数是非常重要的。本文将借助可视化的过程,讲解Pandas的各种操作。喜欢记得收藏、点赞、关注。sort_values(dogs[dogs['size'] == 'medium'] .sort_values('type') .groupby('typ
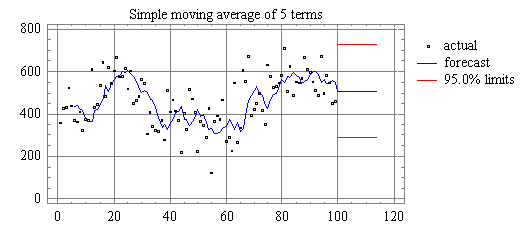
一个简单实例解析移动平均模型 Moving-Average Models
本文将使用简单的说明性示例来解释移动平均模型(Arima [p,q]中的MA [Q])。
秩和比综合评价法(RSR)详解及Python实现和应用
秩和比综合评价法是量化分析数学建模最常用的评价模型之一,在参与数学建模的一些比赛中出现过频数较多的评价系统或是政策影响因素等级排序等相关主题,该模型很够很好的建立评价系统,在多篇国赛美赛优秀论文中都出现过其身影。本篇博客的愿景是希望我或者读者通过阅读这篇博客能够学会RSR方法并能实际运用,而且能够记
R语言使用tidyr包的pivot_longer函数将dataframe数据从宽表变换为长表
R语言使用tidyr包的pivot_longer函数将dataframe数据从宽表变换为长表
R语言使用dplyr包的select函数和filter函数进行行数据筛选(row selection)
R语言使用dplyr包的select函数和filter函数进行行数据筛选(row selection)
机器学习入门-01快速学会使用Matplotlib绘图
快速学会使用Matplotlib绘图使用Matplotlib的基本功能实现图形显示使用Matplotlib实现多图显示使用Matplotlib实现不同画图种类1. Matplotlib之HelloWorld1.1 什么是MatplotlibMatplotlib 是 Python 的绘图库,它能让使用
R语言使用names函数为列表list中的所有数据对象设置名称、使用names函数查看列表中所有数据的名称
R语言使用names函数为列表list中的所有数据对象设置名称、使用names函数查看列表中所有数据的名称
pandas将多个Series对象合并起来形成dataframe、当索引不一致时会产生缺失值NaN
pandas将多个Series对象合并起来形成dataframe、当索引不一致时会产生缺失值NaN
第十届“泰迪杯”数据挖掘挑战赛B题python实现
第十届“泰迪杯”数据挖掘挑战赛B题python实现

常见的8个概率分布公式和可视化
在本文中,我们将介绍一些常见的分布并通过Python 代码进行可视化以直观地显示它们。



