机器学习和人工智能之间的区别
人工智能和机器学习都是计算机科学的术语。本文讨论了一些要点,我们可以根据这些要点区分这两个术语。概述AI(人工智能):人工智能一词由“人工”和“智能”两个词组成。人工是指由人类或非自然事物制造的东西,智能是指有理解或思考的能力。有一种误解认为人工智能是一个系统
PyTorch----实现手写数字的识别
加载手写数字的数据组成训练集和测试集,这里已经下载好了,所以download为Falseimport torchvision# 是否支持gpu运算# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# prin
Python最全学习路线
Python学习路线
项目实战解析:基于深度学习搭建卷积神经网络模型算法,实现图像识别分类
项目交流群(源码获取,问题解答):617172764文章目录前言一、基础知识介绍二、数据集收集三.模型训练四.图像识别分类总结前言随着人工智能的不断发展,深度学习这门技术也越来越重要,很多人都开启了学习机器学习,本文将通过项目开发实例,带领大家从零开始设计实现一款基于深度学习的图像识别算法。学习本章
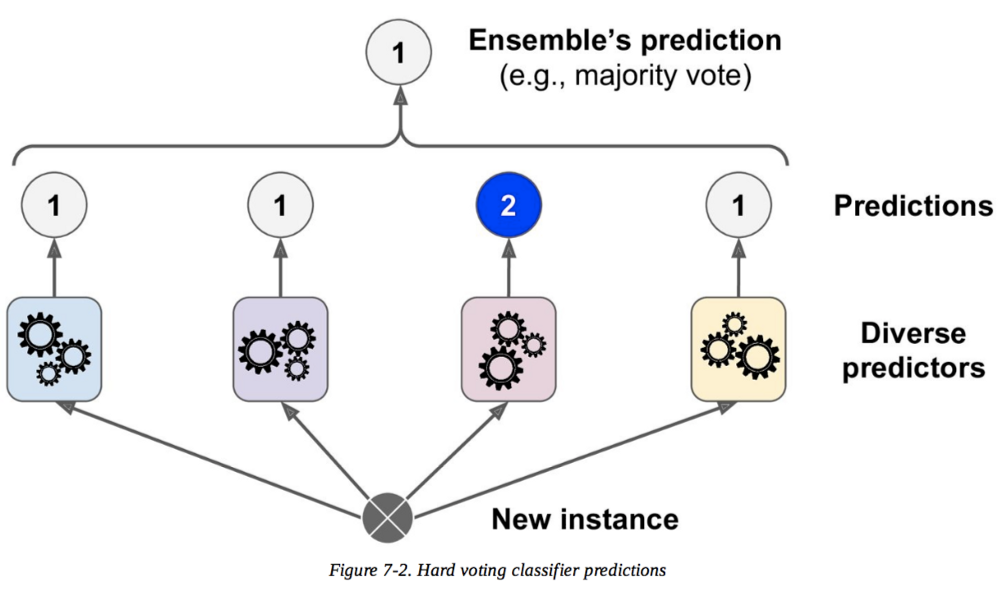
基于神经网络集成学习的研究论文推荐
集成 的概念在机器学习中很常见。集成可以被认为是一种学习技术,可以将许多模型连接起来解决一个问题
深度学习中的优化算法之AdaMax
之前在https://blog.csdn.net/fengbingchun/article/details/125018001 介绍过深度学习中的优化算法Adam,这里介绍下深度学习的另一种优化算法AdaMax。AdaMax与Adam来自于同一篇论文。论文名字为《ADAM: A METHOD FOR
一文读懂机器学习分类全流程
🏆在本文中,作者将带你了解机器学习分类的全流程,从问题分析>数据预处理>分类器选择>模型构建>精度评价>模型发布为Web应用。从0带读者入门机器学习分类。
【关于递归算法的讲解】
关于递归算法的一些知识
零基础入门YOLOv5——从制作数据集到最终训练与测试
零基础入门YOLOv5——从制作数据集到最终训练与测试 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加例如:第一章 Python 机器学习入门之pandas的使用提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录零基础入门YOLOv5——从制作数据集到最终训练
【一起入门DeepLearning】中科院深度学习_期末总复习
考试题目主要是计算题(涉及卷积操作,反向传播计算等)和简答题(概念理解),由7道大题组成,比较简单。
过去两年:20 21九死一生、22年20本书(含书单/笔记),继续百年征程
前言大家都知道九死一生这个词,但基本上除非真正经历过九死一生,不然每个人都很难真正体会。两年的5月份,写了一篇十年总结,名为《我的十年青春(10至20):写博10年1700万PV、创业5年30万学员》,如今刚好过去两年,这两年发生的每一件事都令我印象太深刻了,实在是有必要记录下。20上半年在之前那篇
学习 Python 之 Pandas库
学习 Python 之 Pandas库Pandas库什么是Pandas库?DataFrame 创建和存储1. 使用DataFrame构造函数(1). 使用列表创建(2). 使用字典创建(3). 从另一个DataFrame对象创建2. 从文件读取(1). 从.csv文件读取(2). 从excel文件读
Python模糊基础点--集合中的交集、并集与差集特性、数据序列中的公共方法、列表集合字典推导式
目录集合中的交集、并集与差集特性数据序列中的公共方法第一部分第二部分序列类型之间的相互转换list():把某个序列类型的数据转化为列表tuple():把某个序列类型的数据转化为元组set():将某个序列转换成集合(集合可以快速完成列表去重并且不支持下标)列表集合字典推导式列表推导式字典推导式集合推导
一文搞懂如何使用饱和预测
本文采用Prophet模型对时间序列进行饱和预测,饱和预测通俗一点理解就是在对一系列参数进行预测时会达到一个顶点,我们需要研究的就是预测这个饱和点。
PyTorch 全连接层权值共享的手势识别网络
机器人学实验课的考核是,利用机械臂做一下拓展应用,所以花了很多时间来设计了这个神经网络因为这个神经网络的思路比较新颖,而且尝试了一些防止过拟合、性能优化的手段,所以决定记录一下模型性能time FPS FLOTs Params (float16) 4.195 ms 238 9,
OPENCV图像直方图以及均值化
直方图是我们在照片中使用来查看图像中每个值有多少像素,照片中的每个像素的值都从0(黑色)到255(白色),图的左侧代表音阶的暗色调,右侧代表较亮的色调。在彩色摄影中,每个像素对于每种颜色都有其自己的值(0-255)。图片中的直方图显示了每种颜色(红色,蓝色和绿色)的像素值分布.图像直方图,也叫灰度直
手把手带你玩转Spark机器学习-使用Spark构建回归模型
系列文章目录手把手带你玩转Spark机器学习-专栏介绍手把手带你玩转Spark机器学习-问题汇总[持续更新]手把手带你玩转Spark机器学习-Spark的安装及使用手把手带你玩转Spark机器学习-使用Spark进行数据处理和数据转换手把手带你玩转Spark机器学习-使用Spark构建分类模型文章目
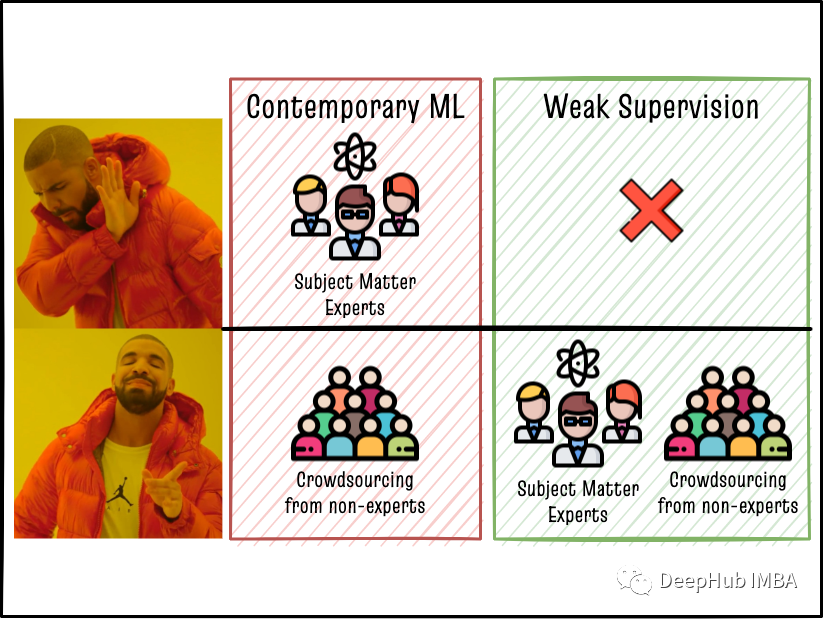
在没有训练数据的情况下通过领域知识利用弱监督方法生成NLP大型标记数据集
介绍了弱监督的概念,以及如何使用它来将专家的领域知识编码到机器学习模型中。我还讨论了一些标记模型。在两步弱监督方法中结合这些框架,可以在不收集大量手动标记训练数据集的情况下实现与全监督ML模型相媲美的准确性!
(详细步骤和代码)利用A100 GPU加速Tensorflow
利用A100 GPU加速TensorflowNVIDIA A100 基于 NVIDIA Ampere GPU 架构,提供一系列令人兴奋的新功能:第三代张量核心、多实例 GPU (MIG) 和第三代 NVLink。Ampere Tensor Cores 引入了一种专门用于 AI 训练的新型数学模式:T
机器学习3-特征工程个人笔记
特征缩放和特征降维操作,sklearn的preprocessing标准化、归一化、二值化、独热编码的使用,sklearn的decomposition中pca、ica降维和discriminant_analysis中lda降维操作。



