
目录
集合中的交集、并集与差集特性
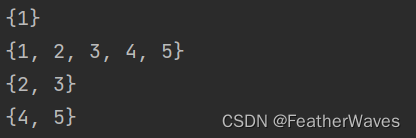
s1 ={1,2,3}
s2 ={1,4,5}print(s1 & s2)print(s1 | s2)print(s1 - s2)print(s2 - s1)
数据序列中的公共方法
所谓的公共方法就是支持大部分数据序列。
第一部分
运算符描述支持的容器类型+合并字符串、列表、元组*复制字符串、列表、元组in元素是否存在字符串、列表、元组、字典not in元素是否不存在字符串、列表、元组、字典
演示:
l1 =[1,2,3]
l2 =[4,5,3]print(l1 + l2)
s1 ="123"
s2 ="456"print(s1 + s2)
t1 =(1,2,3)
t2 =(4,5,6)print(t1 + t2)

print('-'*10)print([1]*10)print((10,)*10)

第二部分
编号函数描述1len()计算容器中元素个数2del或del()根据索引下标删除指定元素3max()返回容器中元素最大值4min()返回容器中元素最小值5range(start, end, step)生成从start到end(不包含)的数字,步长为 step,供for循环使用6enumerate()函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
演示:
d1 ={"1":1,"2":2,"3":3}del d1["1"]print(d1)
l1 =[1,2,3]del l1[1]print(l1)

序列类型之间的相互转换
list():把某个序列类型的数据转化为列表
t =(1,2,3)print(list(t))
s ={1,2,3}print(list(s))
d ={"3":1,"2":2,"1":3}print(list(d))

tuple():把某个序列类型的数据转化为元组
l =[1,2,3]print(tuple(l))
s ={1,2,3}print(tuple(s))

set():将某个序列转换成集合(集合可以快速完成列表去重并且不支持下标)
l =[1,2,3,3]print(set(l))
t =(1,2,3,3)print(set(t))

列表集合字典推导式
推导式comprehensions(又称解析式),是Python的一种独有特性。推导式是可以从一个数据序列构建另一个新的数据序列(一个有规律的列表或控制一个有规律列表)的结构体。 共有三种推导:
列表推导式
、
集合推导式
、
字典推导式
。
列表推导式
变量名 =[表达式 for 变量 in 列表 for 变量 in 列表]
变量名 =[表达式 for 变量 in 列表 if 条件]
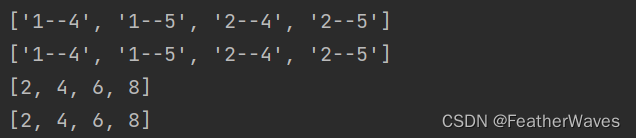
l1 =[f"{i}--{j}"for i inrange(1,3)for j inrange(4,6)]print(l1)
l1_ =[]for i inrange(1,3):for j inrange(4,6):
l1_.append(f"{i}--{j}")print(l1_)
l2 =[i for i inrange(1,10)if i %2==0]print(l2)
l2_ =[]for i inrange(1,10):if i %2==0:
l2_.append(i)print(l2_)
字典推导式
案例1:创建一个字典:字典key是1-5数字,value是这个数字的2次方。
dict1 ={i:i**2for i inrange(1,6)}print(dict1)

案例2:把两个列表合并为一个字典
list1 =['name','age','gender']
list2 =['Tom',20,'male']
person ={list1[i]:list2[i]for i inrange(len(list1))}print(person)

案例3:提取字典中目标数据
counts ={'MBP':268,'HP':125,'DELL':201,'Lenovo':199,'ACER':99}# 需求:提取上述电脑数量大于等于200的字典数据
counts ={key:value for key, value in counts.items()if value >=200}print(counts)

集合推导式
因为列表推导式的原因,可能大家觉得集合推导式很没有必要。
其实不然。集合推导式的最大的优点就是去重。
l1 =[1,1,2]
l =[i **2for i in l1]print(l)
s ={i **2for i in l1}print(s)

本文转载自: https://blog.csdn.net/Uperrr/article/details/125035210
版权归原作者 FeatherWaves 所有, 如有侵权,请联系我们删除。
版权归原作者 FeatherWaves 所有, 如有侵权,请联系我们删除。