
零基础入门YOLOv5——从制作数据集到最终训练与测试
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:第一章 Python 机器学习入门之pandas的使用
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
学习YOLOv5已经有两个月的时间了,这段时间走了不少的弯路,也看了很多文章,今天来简单整理一下,也算是帮助小白快速入门一下。因为我的学习时间也不长,所以如有错误请在评论区指出,大家多多包涵
提示:以下是本篇文章正文内容,下面案例可供参考
一、什么是YOLOv5
在开始之前,先简单介绍一下什么是YOLOv5。YOLOv5是一个one stage目标检测算法,相对于two stage,其检测速度快、易上手、且精度不低。因此是目前最流行的目标检测算法。
二、如何制作数据集
制作数据集的方法有很多种,这里推荐一个最简单的线上数据集制作工具——Make Sense。
网址为:https://www.makesense.ai/
进入网站后,是这样一个界面:
点击中间的小盒子,即可加入你的数据集图片。
添加图片后,即可选择你要制作的数据集类型。左边的是用于目标检测的数据集,右边是用于图像分类的数据集,我们选择左边的目标检测,即可进入下面这样一个界面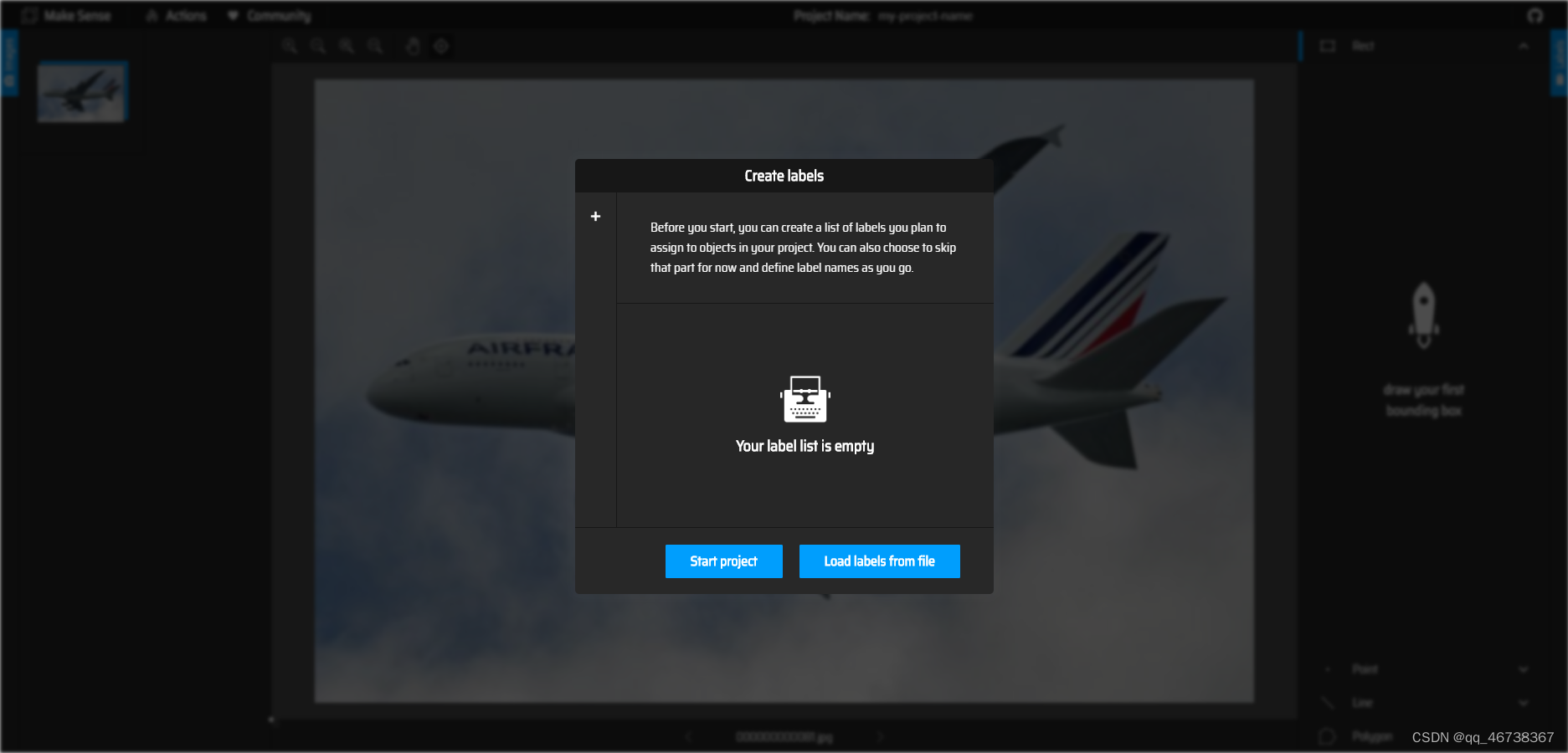
在开始下一步之前,我们需要先创建一个.txt文件,用于存放我们的label。这里我只传入一张飞机的图片,所以只有一个类别。大家可以根据自己的需要写入自己的label
建立完.txt文件后,点击load label from file,然后点击中间的小盒子,插入自己的.txt文件,再点击creat labels list即可创建label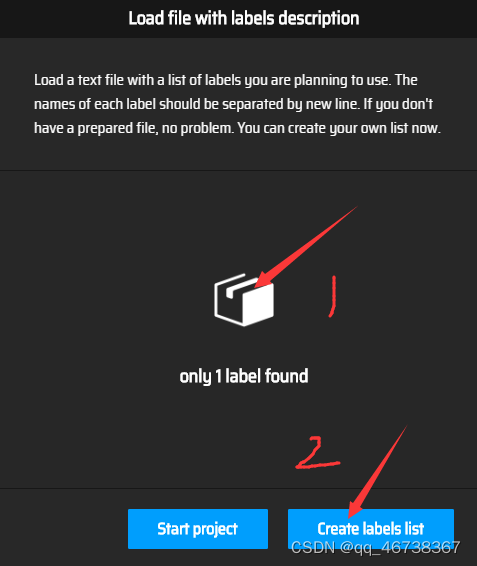
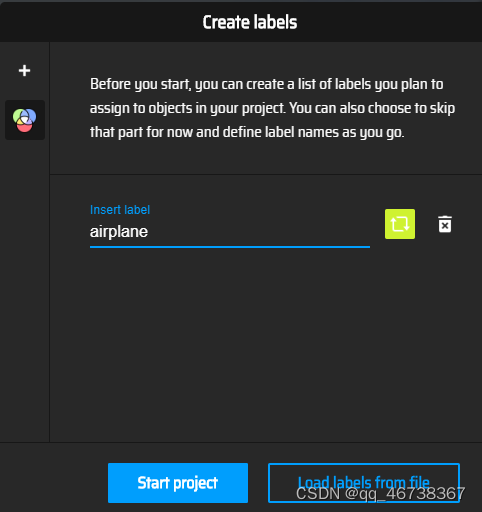
这样做是为了能够高效的创建多个label,当然,如果label较少,也可以直接在界面创建,这里就不详细赘述了。
完成后,点击Start project,就可以开始创建自己的数据集了。
进入绘制界面,选中要检测的对象,在右侧找到对应的标签,就可以完成图片的标定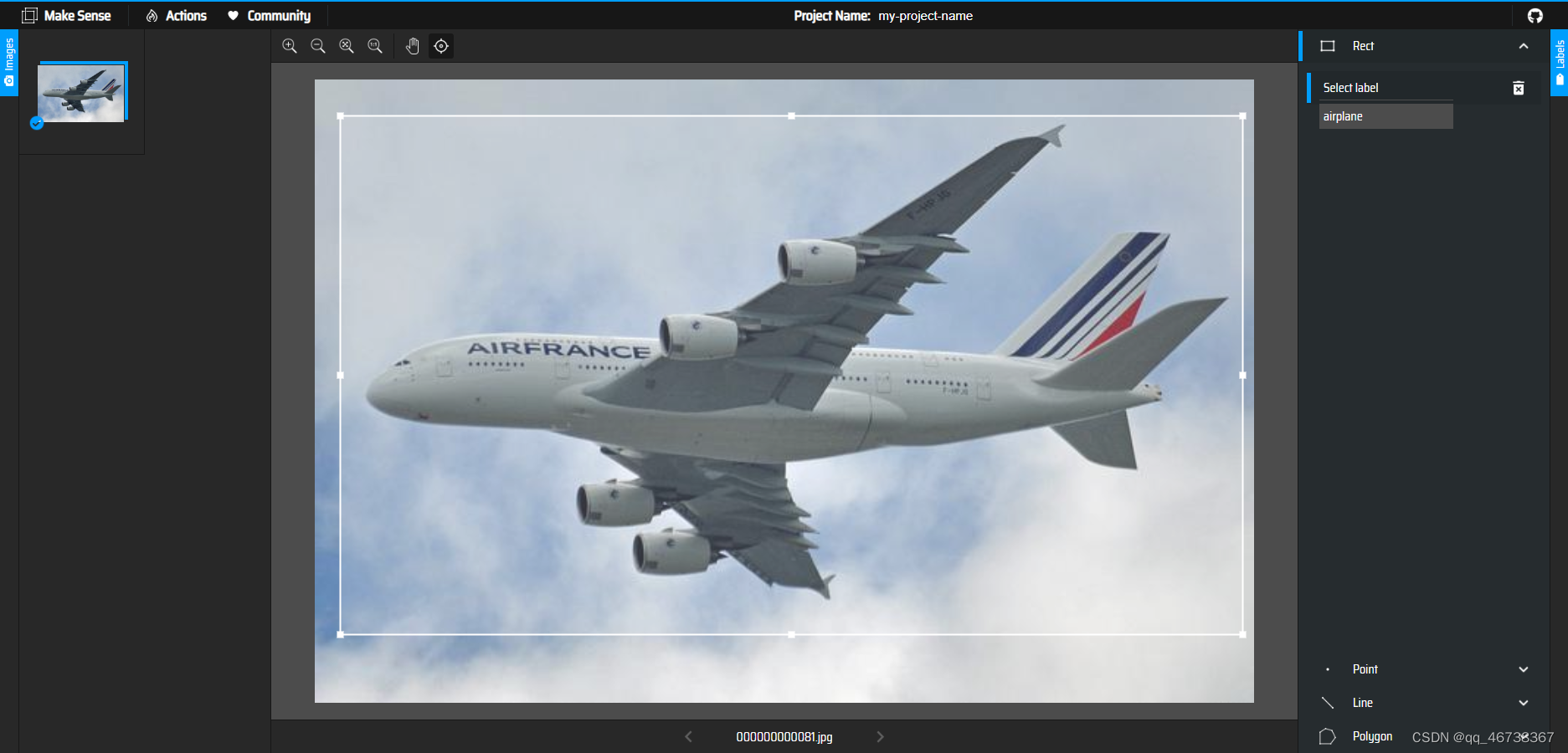
点击左上角的Actions,选择第四个选项,就可以将创建好的数据集下载下来(注意,这里要选择第一个YOLO格式的数据集文件)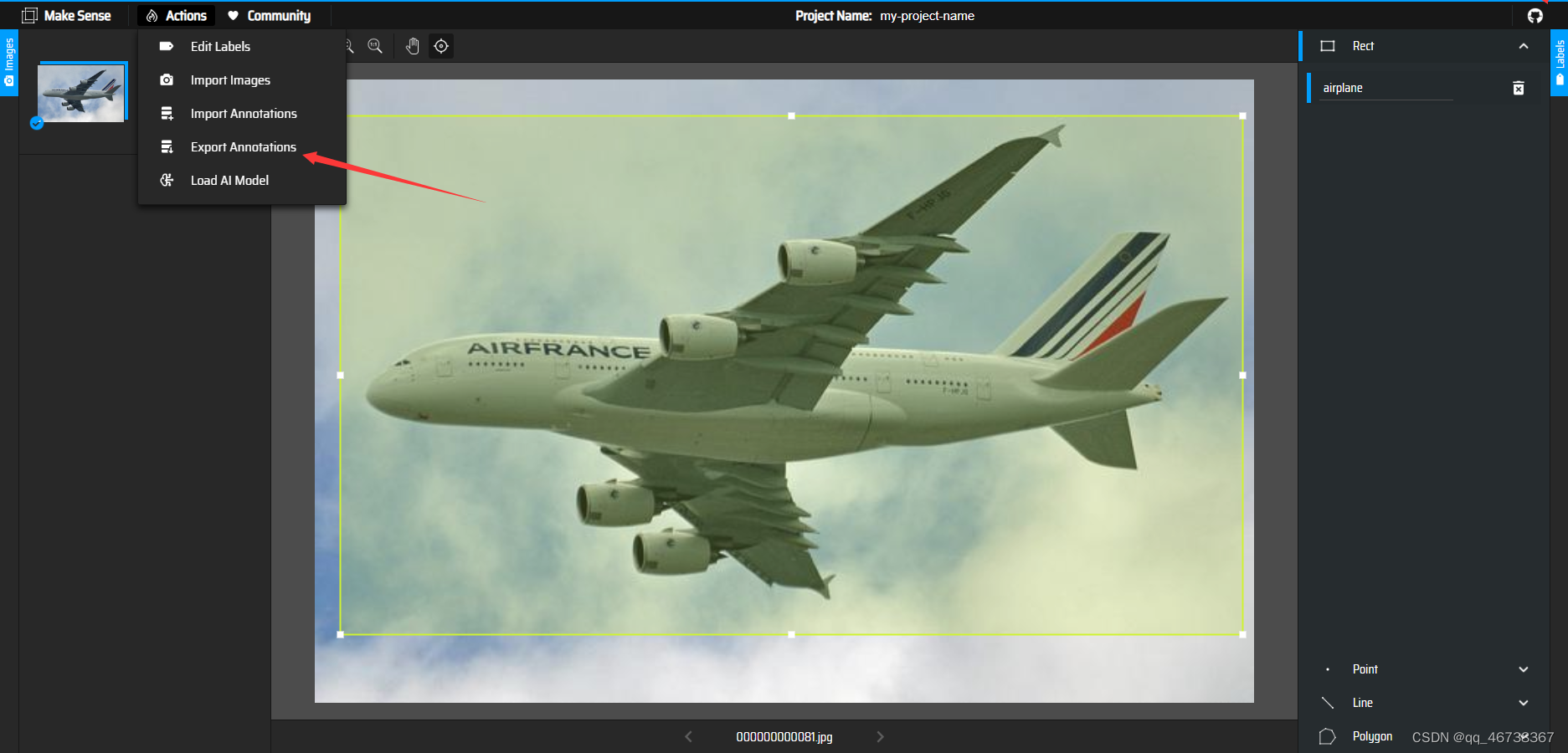
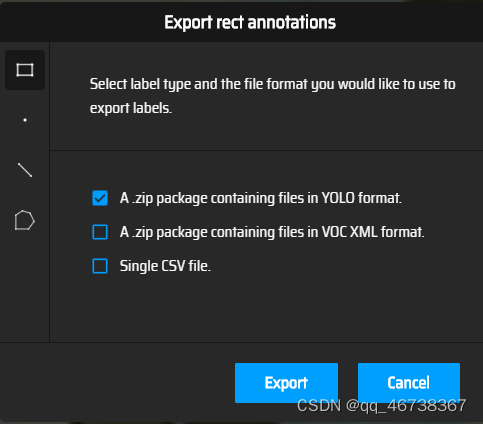

截止到这里,数据集的创建就正式完成了。
二、将数据集导入YOLOv5
在训练之前,我们要先将数据集保存到YOLOv5的文件夹中。具体做法为:
1.创建一个文件夹,这里博主取名为airdata,大家可以自己取名
2.在文件夹里建立两个新文件夹,依次取名为images和labels
3.依次在images和labels文件夹中创建train、test文件夹

4.将训练集和测试集的图片依次导入images文件中的train和test,将训练集和数据集的标签依次导入labels文件夹中的train和test,这里注意顺序不能错,即训练集中的第一张图片一定要对应训练集中的第一个标签。
在完成这一步后,即可打开YOLOv5进行训练了
使用YOLOv5进行训练
因为YOLOv5已经封装好了,所以我们只需要创建几个新的文件,然后调节几个参数就可以了。
首先找到train文件,找到其中的代码块:def parse_opt(known=False):
defparse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights',type=str, default='yolov5s.pt',help='initial weights path')
parser.add_argument('--cfg',type=str, default='models/hub/yolov5_iron_s.yaml',help='model.yaml path')
parser.add_argument('--data',type=str, default=ROOT /'data/mydatatest.yaml',help='dataset.yaml path')
parser.add_argument('--hyp',type=str, default=ROOT /'data/hyps/hyp.scratch-low.yaml',help='hyperparameters path')
parser.add_argument('--epochs',type=int, default=100)
parser.add_argument('--batch-size',type=int, default=4,help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz','--img','--img-size',type=int, default=640,help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true',help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False,help='resume most recent training')
parser.add_argument('--nosave', action='store_true',help='only save final checkpoint')
parser.add_argument('--noval', action='store_true',help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true',help='disable AutoAnchor')
parser.add_argument('--evolve',type=int, nargs='?', const=300,help='evolve hyperparameters for x generations')
parser.add_argument('--bucket',type=str, default='',help='gsutil bucket')
parser.add_argument('--cache',type=str, nargs='?', const='ram',help='--cache images in "ram" (default) or "disk"')
parser.add_argument('--image-weights', action='store_true',help='use weighted image selection for training')
parser.add_argument('--device', default='0',help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true',help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true',help='train multi-class data as single-class')
parser.add_argument('--optimizer',type=str, choices=['SGD','Adam','AdamW'], default='SGD',help='optimizer')
parser.add_argument('--sync-bn', action='store_true',help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers',type=int, default=0,help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default=ROOT /'runs/train',help='save to project/name')
parser.add_argument('--name', default='exp',help='save to project/name')
parser.add_argument('--exist-ok', action='store_true',help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true',help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true',help='cosine LR scheduler')
parser.add_argument('--label-smoothing',type=float, default=0.0,help='Label smoothing epsilon')
parser.add_argument('--patience',type=int, default=100,help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+',type=int, default=[0],help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period',type=int, default=-1,help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--local_rank',type=int, default=-1,help='DDP parameter, do not modify')
我们主要是对weights、cfg和data这三个参数进行修改。其中,weights为初始的权重,可以在GitHub自行下载,这里博主用的是最小的s文件,这个模型所占空间小,但精度相对较低。
接着,我们找到model中的yaml文件,选择其中一个文件进行复制,这里博主依然选择的是最小的yolov5s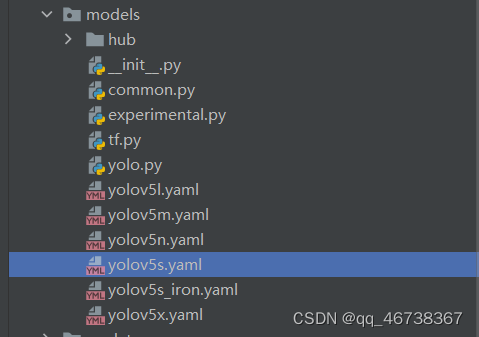
复制一份后,重新命名,因为我之前做的是锻钢瑕疵检测,所以命名为yolov5s_iron。双击打开文件,将这里的nc改为自己的类别数量(如果你的数据集一共有6个类别,那么这里的nc对应的就是6)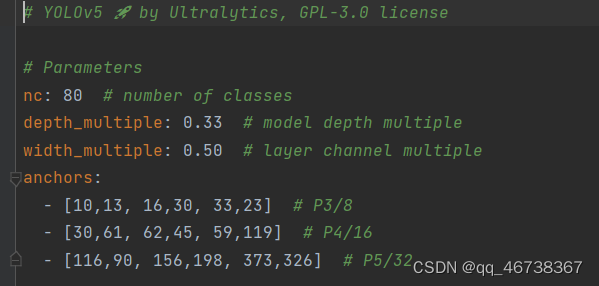
完成这一步后,找到data文件,找到其中的coco128.yaml,依然是复制一份,重新命名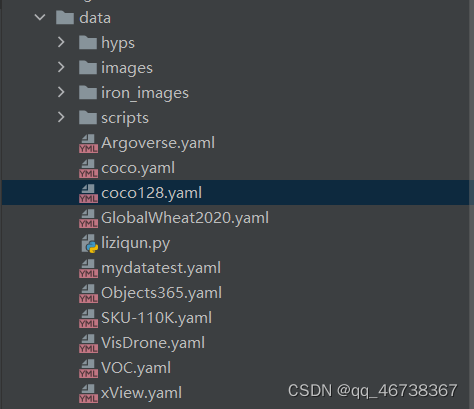
这里我命名的是mydatatest,yaml,双击复制好的文件打开,将下图中的两部分删掉

下面我们要修改的参数主要是以下这部分:
train: images/train2017 # train images (relative to 'path') 128 images
val: images/train2017 # val images (relative to 'path') 128 images
test:# test images (optional)# Classes
nc:80# number of classes
names:['person','bicycle','car','motorcycle','airplane','bus','train','truck','boat','traffic light','fire hydrant','stop sign','parking meter','bench','bird','cat','dog','horse','sheep','cow','elephant','bear','zebra','giraffe','backpack','umbrella','handbag','tie','suitcase','frisbee','skis','snowboard','sports ball','kite','baseball bat','baseball glove','skateboard','surfboard','tennis racket','bottle','wine glass','cup','fork','knife','spoon','bowl','banana','apple','sandwich','orange','broccoli','carrot','hot dog','pizza','donut','cake','chair','couch','potted plant','bed','dining table','toilet','tv','laptop','mouse','remote','keyboard','cell phone','microwave','oven','toaster','sink','refrigerator','book','clock','vase','scissors','teddy bear','hair drier','toothbrush']# class names
将代码中的nc依然改为自己的类别数量,names改为标签名,例如我的图像标签是airplane,那么这里就要写入airplane
最后,要在上面写入自己的训练集和测试集的地址。这里我写入的是相对地址,当然也可以写绝对地址,而且推荐大家写绝对地址。
所有的步骤完成后,我们就可以在train文件中填入这两个个文件的地址,进行训练了
其中,1填入的是model文件夹中的文件地址,2填入的是data文件夹中的地址

在epochs中的default可以编辑自己的训练次数,这里我选择的是训练一百轮
在batch–size的default中可以选择每次训练的图片数量,如果训练过程中显示“文件无法显示”,就需要把这里的参数调小
找到这一个参数,填入default=0,可以使用gpu训练。但是要注意的是,yolov5不支持高版本的pytorch的cuda,如果要使用GPU训练,需要使用低版本的cuda才可以。
开始训练后,在命令控制台输入tensorboard --logdir=runs即可通过tensorboard查看训练过程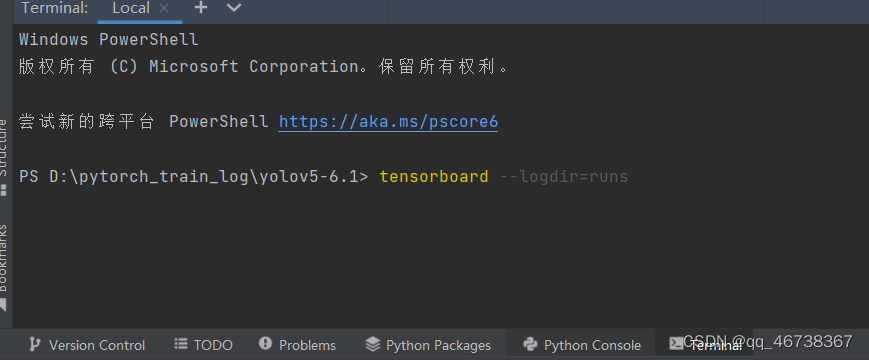
训练完成后的权重文件,可以在runs-train-exp中查看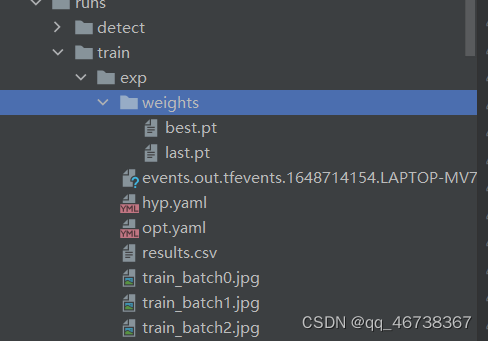
找到detect文件,找到该部分代码块:
parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+',type=str, default=ROOT /'runs/train/exp19/weights/last.pt',help='model path(s)')
parser.add_argument('--source',type=str, default=ROOT /'data/iron_images',help='file/dir/URL/glob, 0 for webcam')
parser.add_argument('--data',type=str, default=ROOT /'data/mydatatest.yaml',help='(optional) dataset.yaml path')
parser.add_argument('--imgsz','--img','--img-size', nargs='+',type=int, default=[640],help='inference size h,w')
parser.add_argument('--conf-thres',type=float, default=0.1,help='confidence threshold')
parser.add_argument('--iou-thres',type=float, default=0.45,help='NMS IoU threshold')
parser.add_argument('--max-det',type=int, default=1000,help='maximum detections per image')
parser.add_argument('--device', default='',help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true',help='show results')
parser.add_argument('--save-txt', action='store_true',help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true',help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true',help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true',help='do not save images/videos')
parser.add_argument('--classes', nargs='+',type=int,help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true',help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true',help='augmented inference')
parser.add_argument('--visualize', action='store_true',help='visualize features')
parser.add_argument('--update', action='store_true',help='update all models')
parser.add_argument('--project', default=ROOT /'runs/detect',help='save results to project/name')
parser.add_argument('--name', default='exp',help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true',help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3,type=int,help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true',help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true',help='hide confidences')
parser.add_argument('--half', action='store_true',help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true',help='use OpenCV DNN for ONNX inference')
在这里需要对前三个参数进行修改:
在第一个weights的参数中填入训练好的权重文件的路径地址,在第二个source参数中填入要检测的图片,在第三个参数中填入之前复制修改的data文件夹中的yaml文件。点击运行即可
总结
例如:以上就是今天要讲的内容,本文仅仅简单介绍了yolov5的简单使用过程,对于其中很多参数以及yolov5的网络模型,后续将出其他博客进行详细解释。
版权归原作者 摆烂无敌王者 所有, 如有侵权,请联系我们删除。