
在现实世界中开发机器学习(ML)模型的主要瓶颈之一是需要大量手动标记的训练数据。例如,Imagenet数据集由超过1400万手动标记的各种现实的图像组成。
虽然迁移学习的出现极大地缓解了这一要求但是仍然需要数百个标记的示例来进行微调。但是获得此类手动注释通常是耗时的和劳动力密集的,并且容易发生人类的错误和偏见。
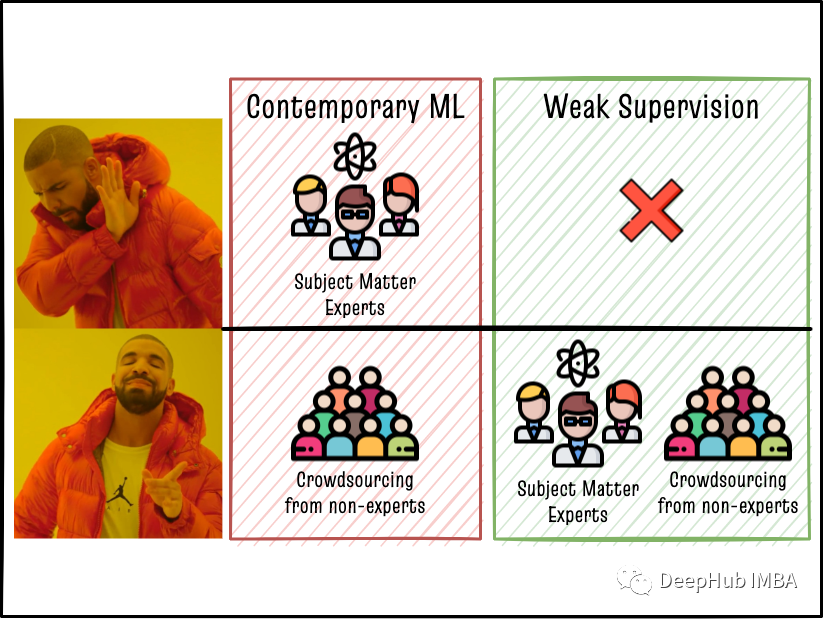
那么,该怎么做才能改善这种情况呢?
最近的弱监督(WS)框架可以通过利用多样化来减少手动标记的工作,并且可以利用领域主题专家(SME)的广泛知识来提高模型的表现。
这篇文章将介绍Edelman DxI数据科学团队在使用弱监督解决NLP问题的一些最新进展!
弱监督学习
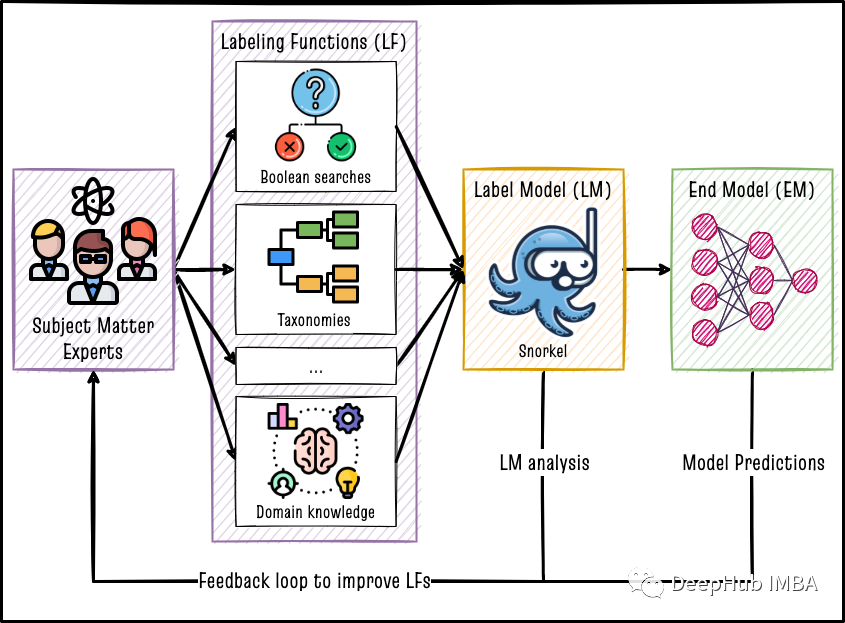
数据编程是指使用启发式标记函数结合标签模型以编程方式创建标记数据集。弱监督使用标签模型创建的标签数据集来训练下游模型,下游模型的主要工作是在标签模型的输出之外进行泛化。如Snorkel论文所述,在数据集上实现弱监督有三个步骤。
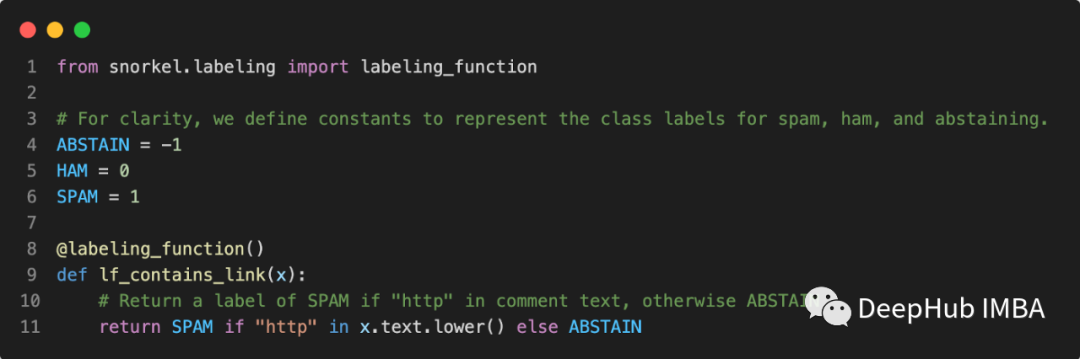
- 编写标记函数(LFS):标记函数是任何可以将数据作为输入的python函数,函数通过使用一些规则来输出该行的标签。例如,如果我们的任务是“电子邮件垃圾邮件检测”,则可以构建一个如下所示的标签函数。每个标签函数都独立运行以标记每行数据。在二元分类问题的情况下,标签为0(不存在标签)或1(标签的存在)或-1(信息不足,不标记)。
- 将弱标签与标签模型(LM)结合在一起:如果我们有M行数据和N个LFS,如果运行所有LFS将导致总共M x n标签,所以需要汇总n个单个LFS的输出,以使每行只有一个标记的结果。投票模型是将多个LF汇总到单个标签的最简单方法。但是还有更好的方法可以通过从整个M行的各个LF之间的相同结果和不同结果中学习的聚合方法。例如,Data Programming Paper ,MeTaL Pape,Flying Squid paper 这三篇论文中提到的一些方法。
- 训练下游模型(EM):使用标签模型的输出用作训练数据微调下游模型,例如BERT。由于LFS是程序化标签源,因此我们可以在整个未标记的语料库上运行步骤1和2,生成许多标签并在步骤3中训练的模型可以受益于步骤1和2中创建的更广泛的训练数据集。
上图中的Snorkel 是使用数据编程的弱监督学习的python库。它提供了易于使用的API来实现和评估步骤1和2。我们可以使用高级ML API,例如HuggingFace的transformers 或Sklearn来实现步骤3。
在某些方法中,还可以将步骤2和3结合到一个步骤中。但是一般情况下两阶段的方法优于单阶段方法,因为这样可以选择任何LM和EM组合,通过不同的组合可以找到最佳的性能。因此本文还是使用将步骤1和步骤2分开进行。
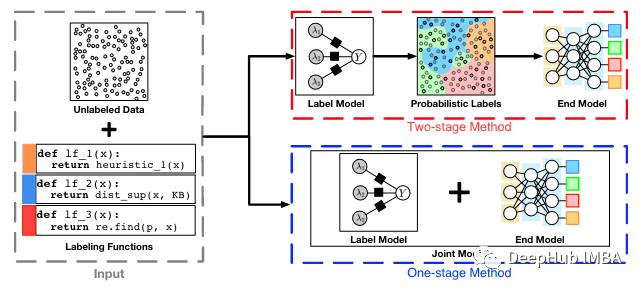
弱监督框架
在弱监督基准测试中,作者基准了各种弱监督框架,并将它们与完全监督的基准进行比较,如下所示。
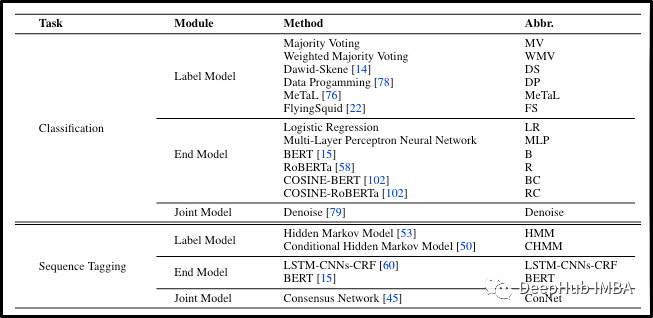
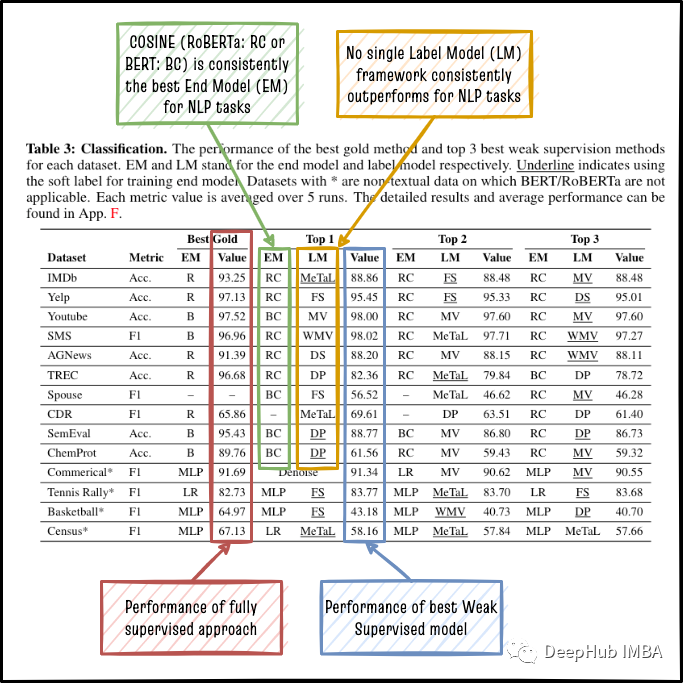
对于NLP任务,Cosine Roberta(RC)始终优于其他模型(EM),包括Vanilla Roberta(R),因此我们可以安全地选择RC作为两阶段方法的最终模型!从上图也能够看到没有单标签模型(LM)框架始终优于其他框架,这表明我们必须在数据集中尝试不同的LMS才能选择最佳的LMS。
COSINE (RC, BC)
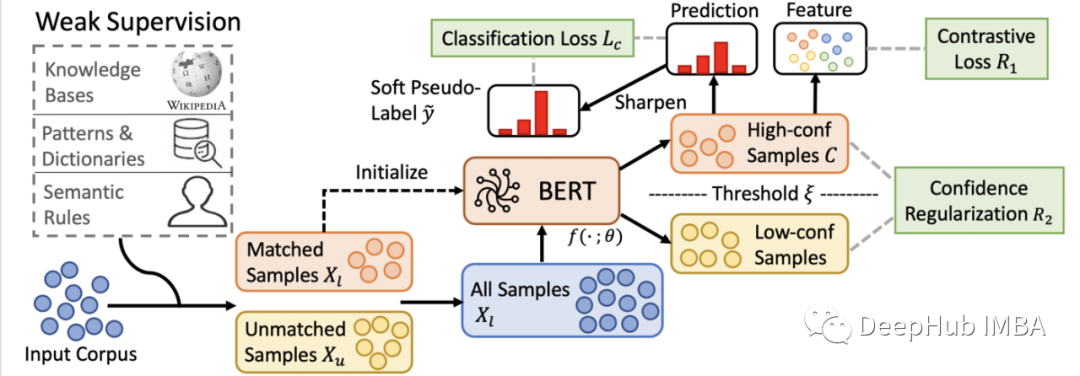
COSINE 是COntrastive Self-training for fINE-Tuning 的缩写,它是近年来弱监督领域最有前途的研究进展之一。该算法有五个步骤。
1、初始化:使用从标签模型的弱标签来微调语言模型,例如在初始化步骤中使用交叉熵损失。然后将微调后的BERT模型在整个数据集上的概率预测作为软伪标签。然后使用这些软伪标签来迭代使用复合损失继续BERT模型的微调,如下公式所示。
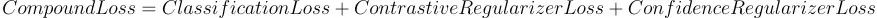
2、样本加权:根据其预测概率重新加权,使预测概率高的样本具有较高的权重,预测概率低的样本具有相应的较低的权重。
3、高置信度样本上的分类损失:因为使用了软伪标签。所以使用高于预定义的权重阈值ξ的样本来计算基于Kullback-Leibler Divergence的加权分类损失。
4、高置信度样本上的对比损失:使用上述步骤中相同的样本来计算对比损失,这样可以使具有相似伪标签的样品靠的更近,而具有不同伪标签的样品在矢量空间距离更远。这里的正样品和负样品之间的边缘差值是一个超参数。
5、所有样本上的置信度正则化::上述整个方法只有在置信度(预测概率)是正确的,而错误标记的样本置信度很低的情况下才有效。因此最终的Loss是一个基于置信度的正则化器,它阻止错误标记的样本获得过高的置信度(过度置信)。超参数λ可以调整正则化强度。
通过上面的步骤COSINE 的方法对弱标签中的噪声是非常健壮的。这也是基准测试中针对于小标签数据执行初始化步骤的最佳的方法之一。
Snorkel
Snorkel可以说是所有弱监督标签模型方法的创始者,可以说是弱监督标签模型方法之母!斯坦福大学的同一位研究人员创造了“数据编程”一词,也发明了Snorkel 。Snorkel 的前提很简单:给定启发式标签函数(LFS)的集合,将每个函数中的弱标签组合为每个样本的单个标签。Snorkel 提供了一个易于使用的框架,可以汇总多个不同的弱的LFS。
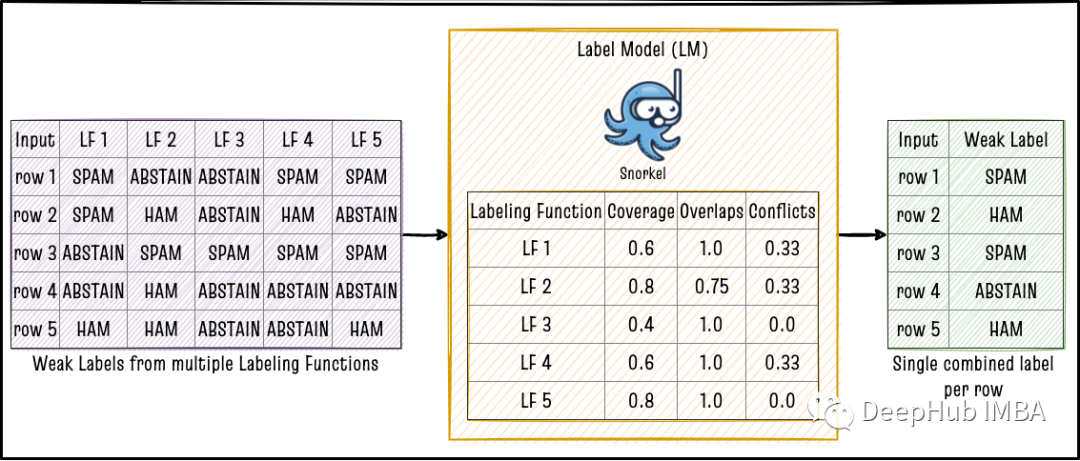
组合多个弱标签的一种方法是仅使用多数投票算法(majority vote),在基准测试中MV确实也是一些数据集的最佳LM。但是LF中的方法可能是相关的,所以导致特定特征在MV模型中过度表现。所以Snorkel实现了更复杂的LM,以使用一些数学矩阵逆向导组合单个LF的输出。
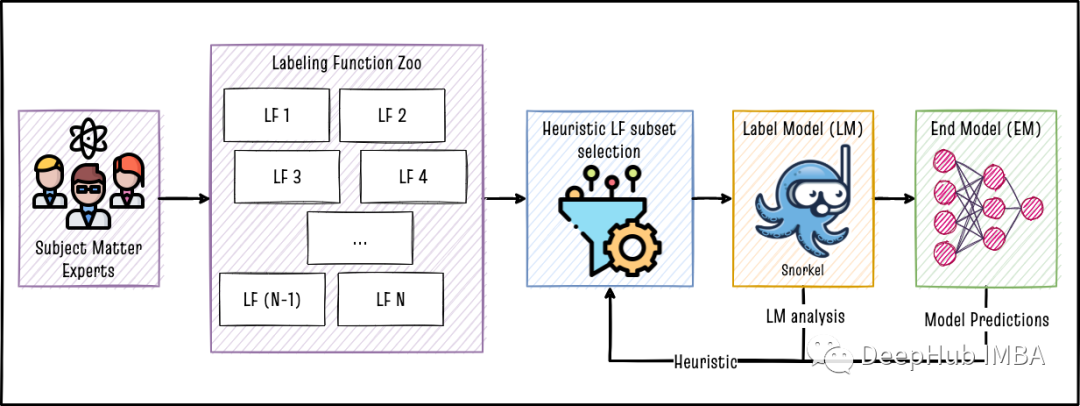
启发式LF选择
Snorkel 易于使用,但是在Snorkel 获得的标签上训练的最终模型(EM)的准确性可能会因LFS的质量而变化很大。因此启发式LF选择被提出出来,该过程只使在一个小的手工标记验证集上具有最好的准确性的LF集合的LF子集。
启发式LF选择可以让我们开始时只使用少量的LFS,并随着时间的推移对他们进行增加和完善。通过分析每次LFS在每次迭代的表现,我们可以确定LFS中的问题,并在下一轮中对LF进行更新或者增加新的条件。这个分析还可以暴露出对问题域理解的差距!
总结
这篇文章中介绍了弱监督的概念,以及如何使用它来将专家的领域知识编码到机器学习模型中。我还讨论了一些标记模型。在两步弱监督方法中结合这些框架,可以在不收集大量手动标记训练数据集的情况下实现与全监督ML模型相媲美的准确性!
引用:
- Want To Reduce Labeling Cost? GPT-3 Can Help
- X-Class: Text Classification with Extremely Weak Supervision
- OptimSeed: Seed Word Selection for Weakly-Supervised Text Classification with Unsupervised Error Estimation
- ASTRA: Self-Training with Weak Supervision
- SPEAR: Semi-Supervised Data Programming with Subset Selectio
- Revisiting Unreasonable Effectiveness of Data in Deep Learning Era
- Data Programming: Creating Large Training Sets, Quickly
- Snorkel: Rapid Training Data Creation with Weak Supervision
- Fine-Tuning Pre-trained Language Model with Weak Supervision: A Contrastive-Regularized Self-Training Approach
- Training Complex Models with Multi-Task Weak Supervision
- Fast and Three-rious: Speeding Up Weak Supervision with Triplet Methods
作者:Marie Stephen Leo