openCV实践项目:银行卡卡号识别
openCV基础操作项目实战

DALL·E-2是如何工作的以及部署自己的DALL·E模型
在本文中,我们将简单介绍DALL-E2是如何工作的,并且把DALL·E Mini生成的图像输入到其他图像处理模型(GLID-3-xl和SwinIR)中来提高生成图像的质量
【机器学习】网络爬虫实战详解
【机器学习】网络爬虫实战详解,基于百度飞桨开发,参考于《机器学习实践》所作。
【机器学习】Python常见用法汇总
【机器学习】Python常见用法汇总,基于百度飞桨开发,参考于《机器学习实践》所作。
【Python 实战基础】Pandas如何精确设置表格数据的单元格的值
Python 中 Pandas如何精确设置表格数据的单元格的值文件读写基础语法Pandasnumpy
走进音视频的世界——RGB与YUV格式
在图像的世界里,一般使用RGB作为存储格式。而在视频的世界里,一般使用YUV作为压缩存储格式。有时候面试官会问:为什么视频使用YUV来压缩存储,而不用RGB?YUV与RGB有什么区别,两者如何转换的?常见的RGB格式有哪些,常见的YUV格式又有哪些?手机摄像头的预览格式是什么,如何转换为YUV420
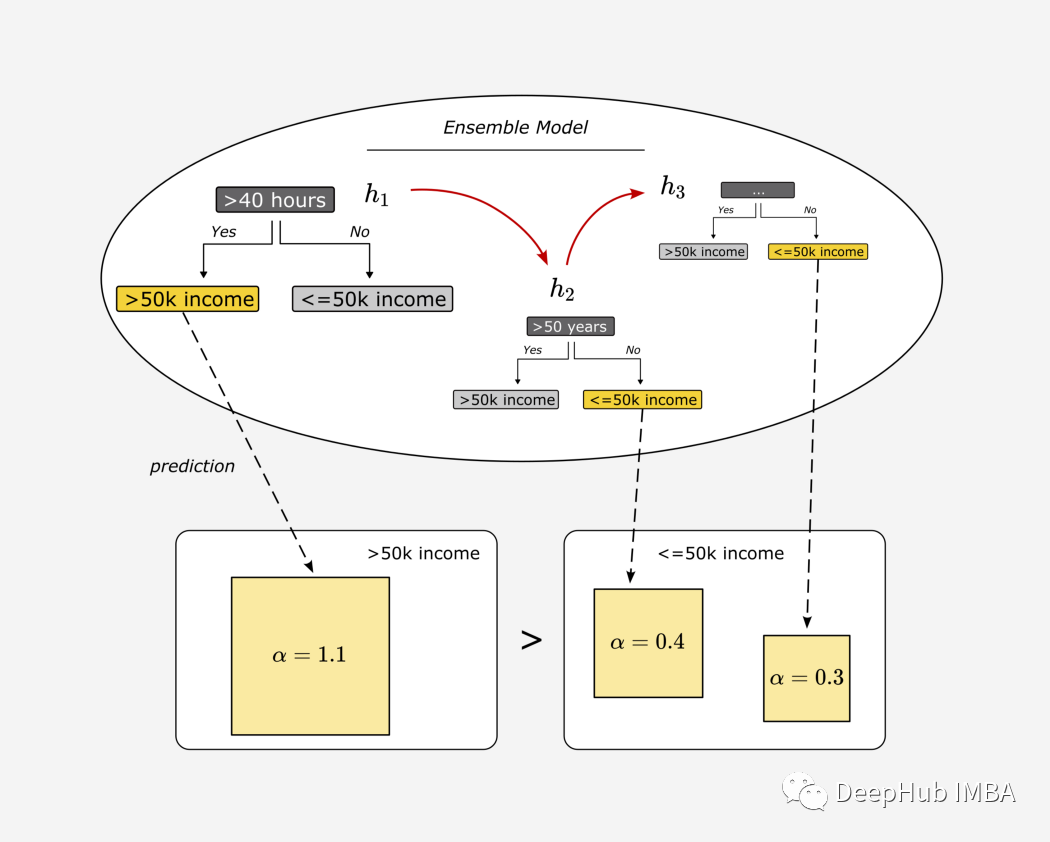
7个步骤详解AdaBoost 算法原理和构建流程
AdaBoost 是集成学习中的一个常见的算法,它模仿“群体智慧”的原理:将单独表现不佳的模型组合起来可以形成一个强大的模型。
人脸识别示例代码解析(二)——人脸识别解析
在openCV中,实现了著名的haar特征检测算法,而依托该算法分类器,我们可以实现人脸识别、定位。该算法基于特征模板的滑动计算图像特征,从而区分物体的显著轮廓。这些特征模板形似黑白区块图像:试想用这些黑白二值图像”蒙”在你的图像或部分图像上,然后你原来的图像被分成“黑”“白”两类区域,最后用黑色区
5.【opencv写入录制视频】
录制视频、通过代码进行保存到磁盘
Geoffrey Hinton:深度学习的下一个大事件
在当今享誉世界的AI科学家中,深度学习教父Geoffrey Hinton也许拥有最为与众不同的研究思维——他喜欢按直觉行事,更倾向于运用类比,研究生涯中的神来之笔大都源自瞬间迸发的思维火花。这与他本人的教育背景息息相关。他的本科专业是生理学和物理学,也读了哲学,拿到的却是心理学.........
【深度学习】笔记2-模型在测试集的准确率大于训练集
在模型训练过程中突然发现,模型的准确率在测试集上居然比在训练集上还要高。但是我们知道,我们训练模型的方式就是在训练集上最小化损失。因此,模型在训练集上有着更好的表现,才应该是正常的现象。那么,是什么导致了在测试集上准确率更高的现象呢?......
sklearn实现一元线性回归 【Python机器学习系列(五)】
sklearn实现一元线性回归 【Python机器学习系列(五)】
【Numpy-矩阵库~python】
个人主页:欢迎关注个人感悟: “失败乃成功之母”,这是不变的道理,在失败中总结,在失败中成长,才能成为IT界的一代宗师。
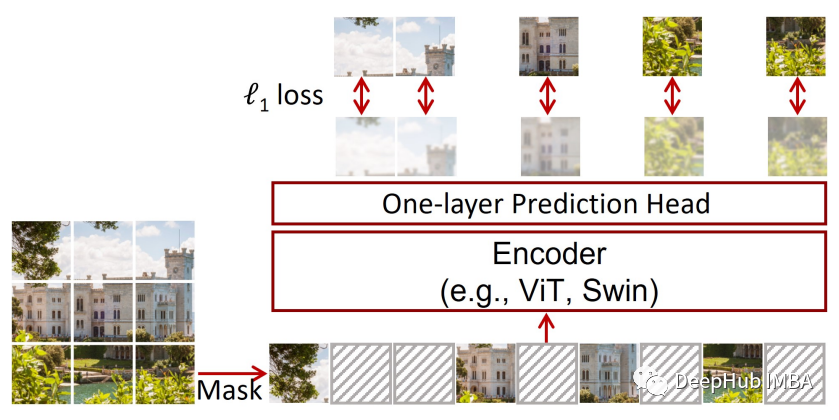
更简单的掩码图像建模框架SimMIM介绍和PyTorch代码实现
在本文中我们将探索一篇和MAE同期的工作:SimMIM,任何VIT都可以在大量未注释的数据上进行训练,并且可以很好地学习下游任务。
CSDN粉丝福利·全栈思维导图·信年✘原创
CSDN原力计划作者,全栈领域优质创作者阿里云开发者社区技术博主、专家博主51CTO 专家博主、TOP红人InfoQ写作平台 —— 签约作者掘金资讯创作者,2021年度人气作者No.1CSDN信年全栈自研社创建者!!知识图谱粉丝福利就到这里!...
【机器学习】数据科学基础——机器学习基础实践(一)
【机器学习】数据科学基础——机器学习基础实践,基于百度飞桨开发,参考于《机器学习实践》所作。
【Python 实战基础】Pandas如何移除包含空值的行
Python Pandas如何移除包含空值的行文件读写基础语法Pandasnumpy
【OpenCV】 人脸识别
C++ 版 OpenCV 人脸识别案例 步骤详解教程

10个自动EDA库功能介绍:几行代码进行的数据分析靠不靠谱
在本文中整理了10个可以自动执行EDA并生成有关数据的见解的软件包,看看他们都有什么功能,能在多大程度上帮我们自动化解决EDA的需求。
如何科学预测后代的身高
否者环境的效应为负,那就达不到理论身高了,误差是负的。如果成千上万的亲子身高数据,我们就可以观测到回归的现象,就是高尔顿所观测到的高的父母,后代会低于父母的平均值,低的父母,会高于父母的平均值。对于第二个,这是随机的,但是可以通过基因分型检测出来孟德尔抽样,也就是在孩子小的时候就可以检测出来像父亲还



