openCV第二篇
openCV第二篇
【OpenCV】 书本视图矫正 + 广告屏幕切换 透视变换图像处理
【OpenCV】 书本视图矫正 + 广告屏幕切换 通过实际案例 深入学习OpenCV透视变换
openCV第一篇
openCV第一章
使用百度EasyDL实现厂区工人抽烟行为识别
在安全巡检场景中,我们通常建议采用端云协同的业务模式,也就是将模型部署至边缘计算节点,在边缘直接完成视频分析,并将分析得到的结构化数据回传至云端,从而避免视频传输所带来的额外延时,以获得较好的业务实时性。通常情况下,我们建议智能视频分析采用端云协同模式,也就是在边缘节点上直接进行视频分析,并将分析后

10快速入门Query函数使用的Pandas的查询示例
pandas.的query函数为我们提供了一种编写查询过滤条件更简单的方法,特别是在的查询条件很多的时候,在本文中整理了10个示例,掌握着10个实例你就可以轻松的使用query函数来解决任何查询的问题。
K-means聚类算法
聚类分析K-means算法
软件工程国考总结——选择题
3)组织过程是指那些与软件生产组织有关的过程(8个)管理过程、基础设施过程、改进过程、人力资源过程、资产。(1)基本过程是指那些与软件生产直接相关的过程(5个)获取过程、供应过程、开发过程、运行过程、维护过程获。文档过程、配置管理过程、质量保证过程、验证过程、确认过程、联合评审过程、审计过程、问题解
一文带你了解推荐系统常用模型及框架
通过对用户之间的关系,用户对物品的评价反馈一起对信息进行筛选过滤,从而找到目标用户感兴趣的信息。用户—商品的评分矩阵(该矩阵很可能是稀疏的)用户\物品xxxxxx行向量表示每个用户的喜好,列向量表明每个物品的属性余弦相似度皮尔逊相关系数欧氏距离曼哈顿距离主要有基于用户的协同过滤与基于物品的协同过滤。
【OpenCV】红绿灯识别 轮廓识别 C++ OpenCV 案例实现
本文以实现行车过程当中的红绿灯识别为目标,核心的内容包括:OpenCV轮廓识别原理以及OpenCV红绿灯识别的实现具体步骤
入门opencv,欢笑快乐每一天
从入门opencv,到对opencv更加感兴趣。

使用分类权重解决数据不平衡的问题
在分类任务中,不平衡数据集是指数据集中的分类不平均的情况,会有一个或多个类比其他类多的多或者少的多。
pynlpir更新license Error: unable to fetch newest license解决方案
pynlpir更新license Error: unable to fetch newest license解决方案1. 问题描述2. 解决方案
可解释深度学习:从感受野到深度学习的三大基本任务,让你真正理解深度学习!
深度学习一直作为一个“盲盒”被大家诟病,我们可以借助深度学习实现端到端的训练,简单,有效,但是我们并不了解神经网络的中间层到底在做什么,每一层卷积的关注点是什么。我在之前的专题浅谈图像处理与深度学习中提到,我们在深度学习刚开始的时候,我们要实现一个任务,比如:把不清晰的图像变清晰,我们随意的搭建了
Python 教程之输入输出(1)—— 在 Python 中接受输入
直接跳到末尾开发人员经常需要与用户交互,以获取数据或提供某种结果。今天的大多数程序都使用对话框来要求用户提供某种类型的输入。而Python为我们提供了两个内置函数来读取键盘输入。此函数首先从用户那里获取输入并将其转换为字符串。返回对象的类型总是。它不评估表达式,它只是将完整的语句作为字符串返回。例如
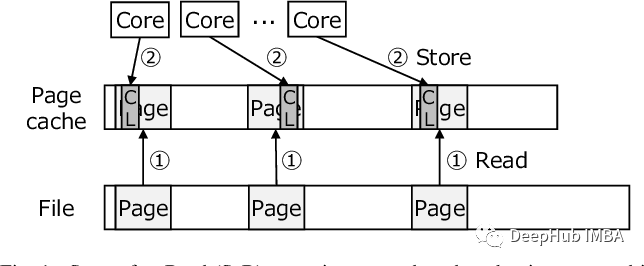
使用内存映射加快PyTorch数据集的读取
本文将介绍如何使用内存映射文件加快PyTorch数据集的加载速度
【NLP】Transformer理论解读
Attention Is All You Need
手推机器学习 吴恩达 神经网络BP反向传播矩阵推导(上篇)
吴恩达机器学习 神经网络BP反向传播算法 基础篇
【机器学习算法】集成学习-1 强学习器的融合学习
集成学习认为多个决策者比一个决策者可能会做出更好的决策,各种模型的整合也是如此,机器学习这种多样化就是通过集成学习的技术实现的。
【4天快速入门Python数据挖掘之第1天】Matplotlib的使用
matplotlib —— 一个画二维图表的 Python 库,专门用于开发 2D 图表(包括 3D 图表),使用起来及其方便,以渐进、交互方式实现数据可视化

30 个数据工程必备的Python 包
在本文中,将介绍一些非常独特的并且好用的 Python 包,它们可以在许多方面帮助你构建数据的工作流。



