
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
知识图谱并不是一个全新的概念,早在 2006 年就有文献提出了语义网(Semantic Network)的概念,呼吁推广、完善使用本体模型来形式化表达数据中的隐含语义,RDF(resource description framework,资源描述框架)模式和 OWL(Web ontology language,万维网本体语言)就是基于上述目的产生的
本文内容
- 什么是知识图谱(KG)?
- 为什么KG?
- KG怎么用?
- 开源KG整理
- 创建自定义KG
- KG Ontology
- KG存储(数据库)
- 从KG查询事实
什么是知识图谱?
为了更好地理解知识图谱,让我们从理解它的基本单元开始,即“事实”。事实是可以存储在 KG 中的最基本的信息。事实可以以任何一种方式以三元组的形式表示,
- HRT:<头部,关系,尾部>
- SPO:<主语、谓语、宾语>
上述表示只是为了命名,因此您可能会遇到人们以任何方式提及该事实。让我们遵循本文的 HRT 表示。无论哪种方式,事实都包含 3 个元素(因此事实也称为三元组),可以帮助将 KG 直观地表示为图形,
- 头或尾:这些实体是现实世界的对象或抽象概念,表示为节点
- 关系:这些是表示为边的实体之间的连接
下面显示了一个简单的 KG 示例。事实的一个例子可能是 <BoB, is_interested_in, The_Mona_Lisa>。您可以看到 KG 只不过是多个此类事实的集合。
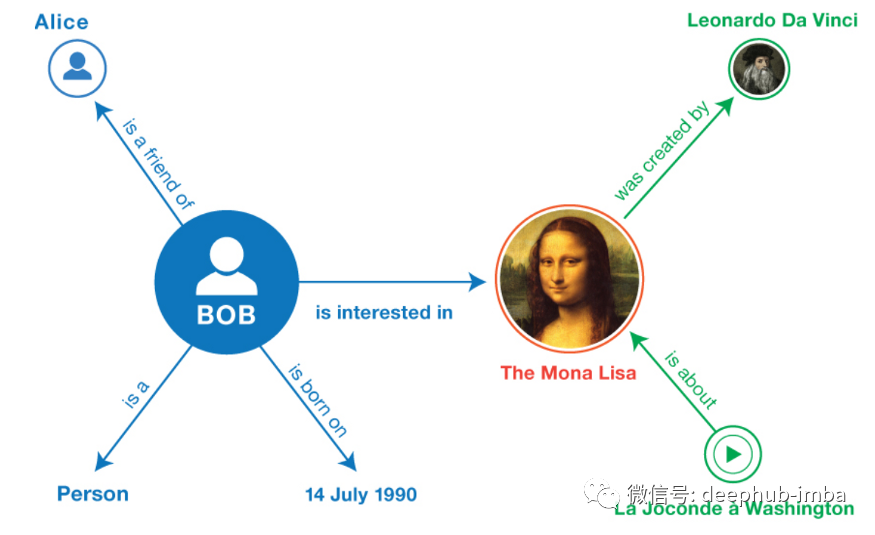
KG中存储的事实的数据类型没有限制。如上例所示,我们有人(Bob、Alice、..)、绘画(蒙娜丽莎)、日期等,表示为 KG 中的节点。
为什么需要知识图谱?
这是任何人在介绍 KG 时都会问的第一个也是有效的问题。我们将尝试通过一些点来比较 KG 与普通图,甚至其他存储信息的方式。目的是突出使用 KG 的主要优势。
与普通图相比
- 异构数据:支持不同类型的实体(人物、日期、绘画等)和关系(喜欢、出生等)。
- 模拟真实世界的信息:更接近我们大脑对世界的心理模型(像正常人一样代表信息)
- 执行逻辑推理:沿路径遍历图以建立逻辑连接(A 的父亲是 B,B 的父亲是 C,因此 C 是 A 的祖父)
与其他存储类型相比
- 结构化表示:与文本数据等非结构化表示相去甚远
- 去除冗余:与表格数据相比,不需要添加大部分为空的列或行来添加新数据(一些事实)
- 查询复杂信息:对于关系比单个数据点更重要的数据,比 SQL 更好(例如,如果您必须在 SQL 查询中执行大量 JOIN 语句,这本身就很慢)
怎么用知识图谱?
知识图谱可用于大量任务——无论是用于逻辑推理、可解释的建议、复杂的分析,还是只是作为一种更好的信息存储方式。我们将简要讨论两个非常有趣的例子。
谷歌知识面板
在向 Google 查询名人、地点或概念时,它会在右侧返回一个知识面板。该面板包含各种各样的信息(描述、教育、出生、死亡、引用等),有趣的是,以不同的格式(文本、图像、日期、数字等)。所有这些信息都可以存储在一个 KG 中,下面显示了一个这样的例子。这展示了存储信息是多么容易,并且还注意到从 KG 读取和理解事实是多么直观。实际上,Google 以 KG 为基础来存储此类信息。

推荐系统
经典算法考虑用户-产品交互来生成推荐。随着时间的推移,新创建的算法开始考虑有关用户和产品的附加信息以改进推荐。
下面,我们可以看到一个 KG(电影 KG),它不仅包含用户-产品连接(这里是人-电影),还包含用户-用户交互和项目属性。我们的想法是,提供所有这些附加信息,我们可以提出更准确、更明智的建议。在不深入研究确切算法的情况下,让我们对可以生成的推荐进行合理化。
“阿凡达”可以推荐给:
- Bob:因为它与星际和盗梦空间一样属于科幻类型(鲍勃已经看过了)
- Alice:由詹姆斯卡梅隆(泰坦尼克号)执导
“血钻”可以推荐给:
- Bob:因为迪卡普里奥也在《盗梦空间》中扮演过角色
这个简单的思考练习应该展示如何使用 KG 以事实的形式轻松表示许多现实世界的交互。然后我们可以将基于 KG 的算法用于下游用例,例如生成推荐。

知识图谱的应用实践
在本节中,我们将从从业者的角度来看 KG。我们将介绍一些开源且随时可用的 KG。在某些情况下,我们甚至可能想要创建自己的 KG,因此我们将讨论一些指针 w.r.t. 它也是。然后我们将通过讨论KG本体来快速了解KG可以构建的一些规则和方式。最后,我们将讨论 KG 托管数据库,并学习如何查询(从中获取事实)KG。
开源知识图谱
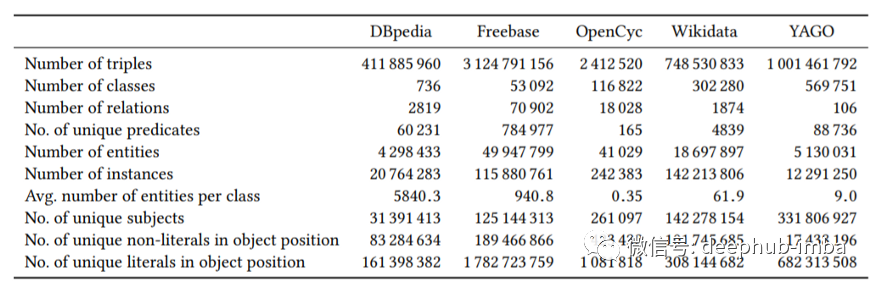
虽然有几个小型且特定领域的 KG,但另一方面,我们也有许多大型且与领域无关的 KG,其中包含所有类型和形式的事实。一些著名的开源产品如下:
DBpedia:是一项基于众包社区的努力,旨在从各种维基媒体项目中存在的信息中提取结构化内容。
Freebase:一个庞大的、协作编辑的交叉链接数据数据库。被誉为“世界知识的公开共享数据库”。它被谷歌收购,用于为自己的 KG 提供内容,所以2015年就停止了。
OpenCyc:是通往 Cyc 全部功能的门户,Cyc 是世界上最完整的通用知识库和常识推理引擎之一。
Wikidata:是一个免费的、协作的、多语言的数据库,收集结构化数据,为维基媒体项目提供支持。
YAGO:庞大的语义知识库,源自维基百科、WordNet 和 GeoNames。
创建自定义知识图
尽管有几个开源 KG,但我们可能需要为我们的用例创建特定于领域的 KG。在那里,我们的基础数据(我们要从中创建 KG)可以是多种类型——表格、图形或文本 blob。我们将介绍如何从文本等非结构化数据创建 KG 的一些步骤,因为使用最少的领域知识和脚本将结构化数据转换为 KG 相对容易。整个过程可以分为两步:
事实创建:这是我们解析文本(逐句)并以三元组格式(如 <H、R、T>)提取事实的第一步。在处理文本时,我们可以利用标记化、词干提取或词形还原等预处理步骤来清理文本。接下来,我们要从文本中提取实体和关系(事实)。对于实体,我们可以使用命名实体识别 (NER) 算法。对于关系,我们可以使用句子依赖解析技术来找到任何实体对之间的关系。
事实选择:一旦我们提取了几个事实,下一个明显的步骤可能是删除重复项并确定可以添加到 KG 的相关事实。为了识别重复项,我们可以使用实体和关系消歧技术。这个想法是在重复的情况下合并相同的事实或事实的元素。例如,“Albert Einstein”也可以写成“Albert E.”。或“A. Einstein”在文本中,但实际上,它们都指的是同一个实体。最后,我们可以有一个全面的基于规则的系统,该系统根据冗余信息等因素决定应该将哪个三元组添加到 KG 或者可以跳过哪个三元组(A → 兄弟 → B 存在,因此 B → 兄弟→ A 是多余的)或不相关的信息。

知识图谱本体(Ontology)
这里我个人感觉Ontology应该翻译成才存在,它是哲学的分支,研究客观事物存在的本质。但是一般都会国内一般将其译为“本体”,所以这里面就按照一般翻译来了。
本体是世界的模型(实际上只是一个子集),列出了实体的类型、连接它们的关系以及对实体和关系组合方式的限制。在某种程度上,本体定义了实体在世界中如何连接的规则。
资源描述框架 (RDF) 和 Web 本体语言 (OWL) 是用于建模本体的一些词汇框架。它们提供了一个表达这些信息的通用框架,因此它可以在应用程序之间交换而不会失去意义。

RDF 提供了用于创建本体的语言,我们将使用它来创建示例 KG。在下面,您可以看到 KG 创建脚本和用 Turtle 语言描述KG。请注意,在脚本的顶部,我们正在创建对许多预定义本体的引用,因为无需重新发明轮子。接下来,要创建我们的 KG 的事实(或三元组),我们可以按照 PREFIX 命令下面的行进行操作。
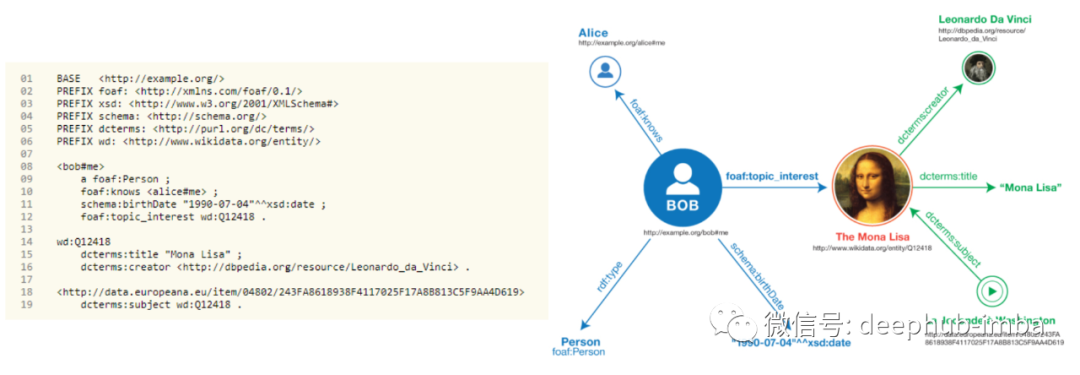
每个实体和关系都有一个唯一标识符(它们的唯一键或 UID)。在整个代码中,相同的实体或关系应该由相同的 UID 引用。接下来,使用预定义的模式,我们可以为实体添加事实(在图形方面,将连接边和尾节点添加到头节点)。这些事实可能包括另一个实体(通过其 UID 引用)、一些文本、日期(以 DateTime 格式)、链接等。
最后,一旦我们准备好脚本(带有 ttl 扩展名——用于 Turtle 语言的脚本),该脚本包含我们的 KG 的完整模式和定义。就其本身而言,这可能并不有趣,因此可以将文件导入任何 KG 数据库,以实现美观的可视化和高效的查询。
知识图的存储
有两种类型的数据库可用于存储图形信息。第一个是“属性图”,如 Neo4j 和 OrientDB,它们不支持 RDF 文件(开箱即用)并且有自己的自定义查询语言。另一方面,我们有“RDF 三元组存储”,它支持 RDF 文件并支持查询语言,如普遍用于查询 KG 的 SPARQL。一些最著名的是(带有开源版本),
GraphDB:Ontotext 的解决方案,提供前端(可视化)和后端(服务器)服务来查看和查询托管知识图谱。
Virtuoso:OpenLinkSoftware 的一个解决方案,提供后端服务来查询托管的 KG。它还支持使用 SQL 和 SPARQL 的组合查询 KG。最重要的是,很多像 DBpedia 这样的开源 KG 都托管在 Virtuoso 上。
查询知识图谱
一旦事实被创建为 RDF 并托管在像 Virtuoso 这样的 RDF 三元组存储上,我们就可以查询它们以提取相关信息。SPARQL 是一种 RDF 查询语言,能够检索和操作以 RDF 格式存储的数据。
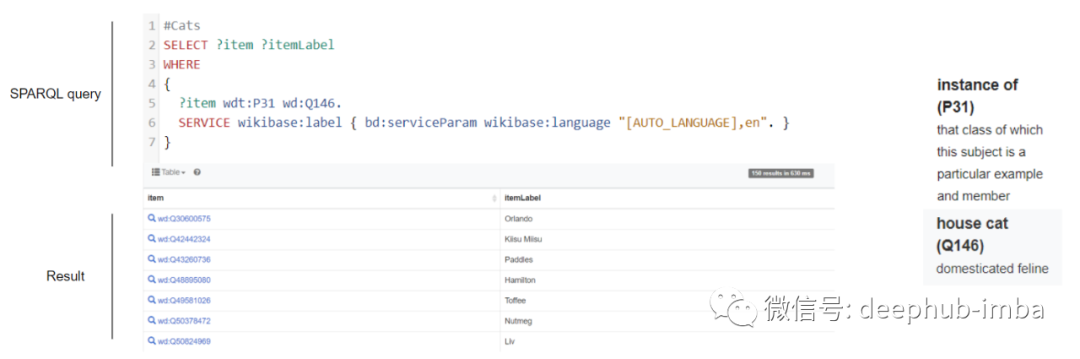
大多数 RDF 三元组存储提供可视化的 SPARQL 查询页面来获取相关信息。对于我们的案例,让我们使用wikidata公开的一个这样的可视化查询助手(如下所示)。显示了一个示例查询,其中我们想要提取所有属于家猫实例的实体(我们只想要一些猫🐱)。如前所述,每个实体都有一个 UID,因此关系 <instance of> 表示为 P31,实体 <house cat> 表示为 Q146。这个查询很容易理解,因为从第 2 行到第 5 行,我们只是想传达我们想要任何作为家猫实例的实体。由于wikidata包含多种语言的数据,因此需要第 6 行来过滤特定于英语的结果。结果(带有 UID 和一些基本详细信息的实体)显示在查询下方。
开源 KG 还为常用查询公开了几个现成的 API。下面显示了一个这样的 API(对于 Wikidata),它返回给定实体的相关信息。下面我们可以看到查询实体 Q9141 的 wbgetentities API 的结果,该实体是泰姬陵的 UID。

作者:Mohit Mayank
喜欢就关注一下吧:
点个 在看 你最好看!********** **********