
本篇文章内容
- 介绍
- AdaBoost
- Gradient Boost1. XGBoost2. Histogram-Based Gradient Boost3. LightBoost4. CatBoost
- 总结
介绍
在集成学习中,目标是用多种学习算法最成功地训练模型。Bagging方法是一种集成学习方法,将多个模型并行应用于同一数据集的不同子样本。Boosting是另一种在实践中经常使用的方法,它不是并行构建的,而是按顺序构建的,目的是训练算法和模型。弱算法先对模型进行训练,然后根据训练结果对模型进行重组,使模型更容易学习。然后将修改后的模型发送给下一个算法,第二个算法比第一个算法学习起来更容易。本文包含了不同的增强方法,从不同的角度解释了这些方法并进行了简单的测试。
AdaBoost
自适应提升(Adaboost)是一种广泛使用的基于决策树桩(Decision stump: Threshold isassigned and the Prediction is made by the threshold.)的boosting方法。但是在Adaboost中并不是盲目地重复这种方法。建立了多个算法,这些算法依次更新它们的权值,并在做出最准确的估计时发挥各自的作用。计算了每种算法的错误率。权值被更新,因此被引用到第二种算法中。第二个算法对模型进行分类,像第一个模型一样更新权重,并将其转移到第三个算法。这些过程一直持续到n_estimator的数目或达到误差=0。在这个过程中,由于权值由之前的算法更新并发送给其他算法,使得分类更加容易和成功。让我们用一个例子来解释这个复杂的顺序算法过程:
假设有两个标签,红色和蓝色。第一种算法(弱分类器1)对标签进行分离,结果是2个蓝色样本和1个红色样本被误分类。这些错误分类的权重增加,正确分类的权重降低后,发送到下一个模型进行学习。在新模型中,错误分类样本的偏差增大,而正确分类样本的偏差减小,这两种模型的学习效果较好。接下来的步骤将重复相同的过程。综上所述,强分类是在弱分类的配合下发生的。因为它用于分类,所以也可以通过导入AdaBoostRegressor用于回归。
超参数
base_estimators:一个顺序改进的算法类(默认= DecisionTreeClassifier)
n_estimators:确定上述过程将采取的最大步骤数。(默认= 50)
learning_rate:决定权重的变化量。如果选择过小,则n_estimators的值必须非常高。如果它被选得太大,它可能永远达不到最优值。(默认= 1)
import numpy as np
from time import time
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score,train_test_split
from sklearn.model_selection import KFold
x,y = make_classification(n_samples=100000,n_features=30, n_informative=10,
n_redundant=5,random_state=2021)
一个将用于所有方法的数据集已经导入,现在让我们实现Adaboost:
from sklearn.ensemble import AdaBoostClassifier
start_ada = time()
ada = AdaBoostClassifier()
kf=KFold(n_splits=5,shuffle=True,random_state=2021)
ada_score=cross_val_score(ada,x,y,cv=kf,n_jobs=-1)
print("ada", np.round(time()-start_ada,5),"sec")
print("acc", np.mean(ada_score).round(3))
print("***************************")
Gradient Boost
Adaboost 通过使用决策树桩(1 个节点分为 2 个叶子)更新权重来改进自身。梯度提升是另一种顺序方法,通过创建 8 到 32 个叶子来优化损失,这意味着树在梯度提升中更大(损失:就像是在线性模型中的残差)。(y_test-y_prediction)通过每个数据点给出损失的平方和给出残差。为什么使用平方?因为我们正在寻找的值是预测与实际结果的偏差。负值平方后也会作用于损失值的计算 。简而言之,将残差值转移到下一算法,使残差值更接近于0,从而使损失值最小化。
GB = GradientBoostingClassifier()
start_gb = time()
kf=KFold(n_splits=5,shuffle=True,random_state=2021)
GB_score=cross_val_score(GB,x,y,cv=kf,n_jobs=-1)
print("gb", np.round(time()-start_gb,5),"sec")
print("acc", np.mean(GB_score).round(3))
print("***************************")
在Adaboost中,梯度增强可以通过导入GradientBoostRegressor用于回归。
from sklearn.metrics import mean_squared_error
x_train, x_test, y_train, y_test = train_test_split(x, y,test_size=0.2,random_state=2021)
gbr = GradientBoostingRegressor(max_depth=5, n_estimators=150)
gbr.fit(x_train, y_train)
error_list = [mean_squared_error(y_test, y_pred) for y_pred in gbr.staged_predict(x_test)]
OUT
[0.22686585533221332,0.20713350861706786,0.1900682640534445,
0.1761959477525979,0.16430532532798403,0.1540494010479854,
0.14517117541343785,0.1375952312491854,0.130929810958826,
0.12499605002264891,0.1193395594019215,0.11477096339545599,
0.11067921343289967,0.10692446632551068,...................
...........................................................
0.05488031632425609,0.05484366975329703,0.05480676108875857,
0.054808073418709524,0.054740333154284,0.05460221966859833,
0.05456647041868937,0.054489873127848434,0.054376259548495065,
0.0542407250628274]
查看Error_list,可以看到损失值在每一步都在变小。[从0.22开始,完成到0.05]
XGBoost
XGBoost(Extreme Gradient Boosting)是由Tianqi Chen在2014年开发的,在Gradient boost之前速度最快,是首选的Boosting方法。由于它包含超参数,可以进行许多调整,如正则化超参数防止过拟合。
超参数
booster [缺省值=gbtree]决定那个使用那个booster,可以是gbtree,gblinear或者dart。gbtree和dart使用基于树的模型,而gblinear 使用线性函数.
silent [缺省值=0]设置为0打印运行信息;设置为1静默模式,不打印
nthread [缺省值=设置为最大可能的线程数]并行运行xgboost的线程数,输入的参数应该<=系统的CPU核心数,若是没有设置算法会检测将其设置为CPU的全部核心数下面的两个参数不需要设置,使用默认的就好了
num_pbuffer [xgboost自动设置,不需要用户设置]预测结果缓存大小,通常设置为训练实例的个数。该缓存用于保存最后boosting操作的预测结果。
num_feature [xgboost自动设置,不需要用户设置]在boosting中使用特征的维度,设置为特征的最大维度
eta [缺省值=0.3,别名:learning_rate]更新中减少的步长来防止过拟合。在每次boosting之后,可以直接获得新的特征权值,这样可以使得boosting更加鲁棒。范围:[0,1]
gamma [缺省值=0,别名: min_split_loss](分裂最小loss)在节点分裂时,只有分裂后损失函数的值下降了,才会分裂这个节点。Gamma指定了节点分裂所需的最小损失函数下降值。这个参数的值越大,算法越保守。这个参数的值和损失函数息息相关,所以是需要调整的。范围: [0,∞]
max_depth [缺省值=6]这个值为树的最大深度。这个值也是用来避免过拟合的。max_depth越大,模型会学到更具体更局部的样本。设置为0代表没有限制范围: [0,∞]
min_child_weight [缺省值=1]决定最小叶子节点样本权重和。XGBoost的这个参数是最小样本权重的和,而GBM参数是最小样本总数。这个参数用于避免过拟合。当它的值较大时,可以避免模型学习到局部的特殊样本。但是如果这个值过高,会导致欠拟合。这个参数需要使用CV来调整。.范围: [0,∞]
subsample [缺省值=1]这个参数控制对于每棵树,随机采样的比例。减小这个参数的值,算法会更加保守,避免过拟合。但是,如果这个值设置得过小,它可能会导致欠拟合。典型值:0.5-1,0.5代表平均采样,防止过拟合.范围: (0,1]
colsample_bytree [缺省值=1]用来控制每棵随机采样的列数的占比(每一列是一个特征)。典型值:0.5-1范围: (0,1]
colsample_bylevel [缺省值=1]用来控制树的每一级的每一次分裂,对列数的采样的占比。我个人一般不太用这个参数,因为subsample参数
colsample_bytree参数可以起到相同的作用。但是如果感兴趣,可以挖掘这个参数更多的用处。范围: (0,1]
lambda [缺省值=1,别名: reg_lambda]权重的L2正则化项。(和Ridge regression类似)。这个参数是用来控制XGBoost的正则化部分的。虽然大部分数据科学家很少用到这个参数,但是这个参数在减少过拟合上还是可以挖掘出更多用处的。.
alpha [缺省值=0,别名: reg_alpha]权重的L1正则化项。(和Lasso regression类似)。可以应用在很高维度的情况下,使得算法的速度更快。
scale_pos_weight[缺省值=1]在各类别样本十分不平衡时,把这个参数设定为一个正值,可以使算法更快收敛。通常可以将其设置为负样本的数目与正样本数目的比值。
from xgboost import XGBClassifier
xgb = XGBClassifier()
start_xgb = time()
kf=KFold(n_splits=5,shuffle=True,random_state=2021)
xgb_score=cross_val_score(xgb,x,y,cv=kf,n_jobs=-1)
print("xgboost", np.round(time()-start_xgb,5))
print("acc", np.mean(xgb_score).round(3))
print("***************************")
Histogram-Based Gradient Boost
使用binning(discretizing)对数据进行分组,这是一种数据预处理方法,这里已经解释过了。例如,当给出“年龄”列时,将这些数据分为 30-40、40-50、50-60 3 组,然后将它们转换为数值数据是一种非常有效的方法。当这种分箱方法适用于决策树时,通过减少特征数量可以加快算法速度。该方法还可以通过将其与直方图分组来用作构建每棵树的集成。
from sklearn.experimental import enable_hist_gradient_boosting
from sklearn.ensemble import HistGradientBoostingClassifier
HGB = HistGradientBoostingClassifier()
start_hgb = time()
kf=KFold(n_splits=5,shuffle=True,random_state=2021)
HGB_score=cross_val_score(HGB,x,y,cv=kf,n_jobs=-1)
print("hist", np.round(time()-start_hgb,5),"sec")
print("acc", np.mean(HGB_score).round(3))
print("***************************")
LightBoost
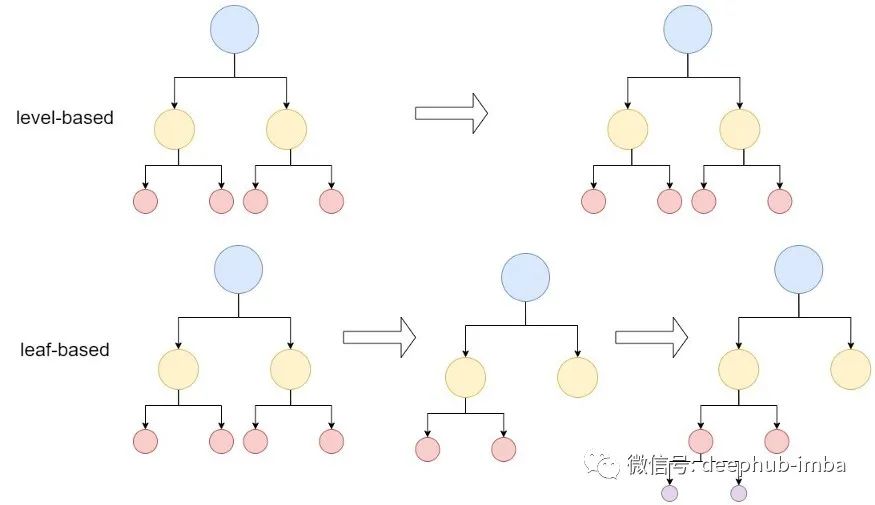
LGBM (Light Gradient Boosting Machine)是微软于2017年首次发布的一种基于决策树的梯度增强方法,是用户首选的另一种梯度增强方法。与其他方法的关键区别在于它是基于叶子进行树的分裂,即它可以通过关键点位检测和停计算(其他提升算法是基于深度或基于级别的)。由于LGBM是基于叶的,如图2所示,LGBM是一种非常有效的方法,可以减少误差,从而提高精度和速度。但是它不支持字符串类型的数据,需要使用特殊算法拆分分类数据,因为必须输入整数值(例如索引)而不是列的字符串名称。
from lightgbm import LGBMClassifier
lgbm = LGBMClassifier()
start_lgbm = time()
kf=KFold(n_splits=5,shuffle=True,random_state=2021)
lgbm_score=cross_val_score(lgbm,x,y,cv=kf,n_jobs=-1)
print("lgbm", np.round(time()-start_lgbm,5))
print("acc", np.mean(lgbm_score).round(3))
print("***************************")
CatBoost
CatBoost 由 Yandex 于 2017 年开发。由于它使用 One-Hot-Encoding 将所有分类特征转换为数值,因此名称来自 Categorical Boosting。将字符串自动转化成索引值输入的同属他还处理了缺失的数值。而且它也比 XGBoost 快得多。与其他 boosting 方法不同,Catboost 与对称树进行区分,对称树在每个级别的节点中使用相同的拆分。
XGBoost 和 LGBM 计算每个数据点的残差并训练模型以获得残差目标值。它针对迭代次数重复此操作,从而训练并降低残差,从而达到目标。由于这种方法适用于每个数据点,因此在泛化方面可能会很弱并导致过度拟合。
Catboost 还计算每个数据点的残差,并使用其他数据训练的模型进行计算。这样,每个数据点就得到了不同的残差数据。这些数据被评估为目标,并且通用模型的训练次数与迭代次数一样多。由于许多模型将根据定义实现,因此这种计算复杂性看起来非常昂贵并且需要太多时间。但是catboost通过有序提升但可以在更短的时间内完成。例如,catboost不是从每个数据点 (n+1)th 计算的残差的开头开始,俄日是计算(n+2)个数据点,应用(n+1)个数据点,依此类推
超参数
l2_leaf_reg:损失函数的L2正则化项。
learning_rate:学习率。在过度拟合的情况下降低 learning_rate。
depth:树的深度,多在6-10之间使用。
one_hot_max_size:使用一个独热编码对所有分类特征进行编码,其中几个不同的值小于或等于给定的参数值
grow_policy:决定树的构造类型。可以使用 SymmetricTree、Depthwise 或 Lossguide。
from catboost import CatBoostClassifier
cat = CatBoostClassifier()
start_cat = time()
kf=KFold(n_splits=5,shuffle=True,random_state=2021)
cat_score=cross_val_score(cat,x,y,cv=kf,n_jobs=-1)
print("cat", np.round(time()-start_cat,5))
print("acc", np.mean(cat_score).round(3))
print("***************************")
总结
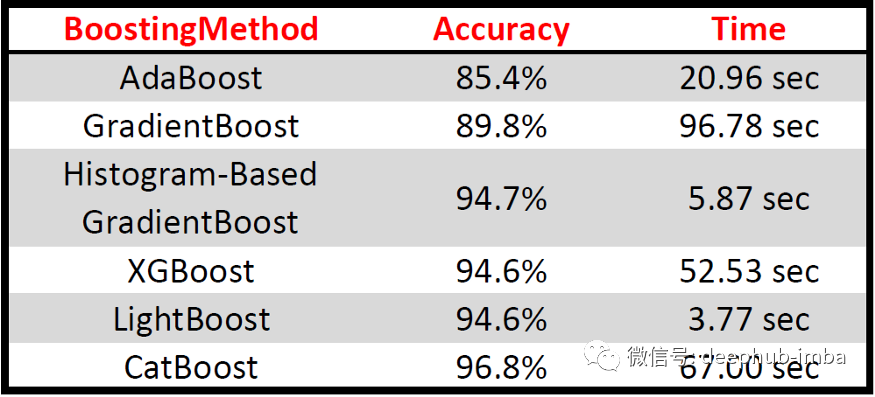
在本文中,使用 DecisionTree 来处理提升方法,但可以通过更改相关的超参数轻松实现其他机器学习模型。此外,所有boosting方法都使用base version(未调整任何超参数)来比较boosting方法的性能,上面应用的代码如下表:
作者:Ibrahim Kovan