
由于图数据结构无处不在,图神经网络 (GNN) 越来越受欢迎。图使我们能够对科学领域中的许多不同问题进行建模,例如(但不限于)生物学、社会学、生态学、视觉、教育、经济学等。此外,图表示使我们能够处理大规模的非结构化数据。
在本文中,我将展示如何在分类、聚类和可视化等任务中使用简单的 GNN。我将使用 GCN(图卷积网络)作为运行示例。这应该提供一个很好的启发,将意识形态扩展到他们自己的领域。
GNN 的正式表示方法
任何GNN都可以表示为一个包含两个数学算子的层,即聚合函数和组合函数。使用MPNN(消息传递神经网络)框架可以最好地理解这一点。

聚合
如果我们考虑上面的一个例子图,聚合器函数专门用于结合邻域信息。更正式地说,聚合可以表示为;
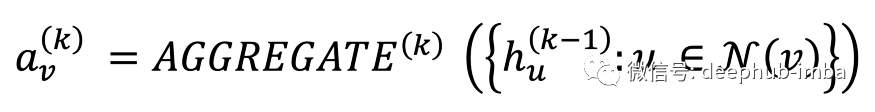
简单来说,第k层GNN层中节点v的邻域聚合是使用相邻节点u的激活,k-1层的hᵤ来表示的。v 的邻居表示为 N(v)。在第一层 k-1=0,回退到当前节点特征。在第一层,我们简单地聚合相邻节点的初始特征。在 GCN 的情况下,聚合器只是归一化度(degree)的平均值(每个消息都由 v 和 u 的度的乘积的平方根归一化)。只要操作是顺序不变的(结果不会因打乱而改变),就可以想到各种聚合器,例如 max、mean、min 等。
组合
相邻节点信息与节点本身的组合在下面的等式中正式表示。
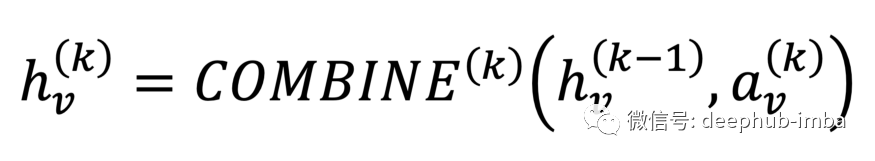
这里可以使用不同的操作,例如连接、求和或wise pooling操作。不同的 GNN 架构依赖于不同的功能。例如 GCN 使用平均值,我们将在接下来讨论。
在上图中,我们可以通过 X1/(sqrt(7×2)) 来聚合节点 1 到 6 的特征 X1 是节点 1 的特征,7、2 分别是节点 6 和 1 的度数。对于每个节点,我们都可以这样做。直观地,我们可以将其视为每个节点通过对其出度进行平均来将其消息传递给其他节点,并且他们通过对入度进行平均来接收其他人的消息。因此得名 MPNN(Message Passing Neural Network)。
对于具有邻接矩阵 A 和具有特征 X 的度矩阵 D(degree**matrix) 的图 G(V, E),这可以通过 D(-1/2)XAD(-1/2) 轻松实现。通常,邻接矩阵加上I(单位矩阵)以结合节点自身的特征。在这种情况下,A 表示为 Â (A-hat),而 D 被 D-hat 替换,其中 D-hat 对应于 A-hat。在这一点上,我们已经在几个矩阵运算中执行了聚合和组合。得到的矩阵被传递到一个可训练的可微函数 ɸ,它通常是一个 MLP(多层感知器),即神经网络。
堆叠层
我们讨论了 GNN 层中发生的事情,现在我们堆叠了几个这样的层。这意味着我们对邻接矩阵进行了更多的乘法运算。如果你熟悉随机游走,则 D^(-1)A 称为转移矩阵(跃迁矩阵)。用于迭代幂次直到收敛以找到从给定节点到另一个节点的随机游走概率。直观地说,我们添加的 GNN 层越多,聚合扩展的跳数就越多。或者换句话说,在一层之后,我们有节点及其邻居的信息。当我们再次这样做时,邻居(拥有他们的邻居)再次聚合。因此有 2 跳,依此类推。
PyTorch几何框架
GNN 可以使用 pytorch 几何库轻松实现。你可以找到许多 GNN 的实现和一个消息传递类来使用你自己的自定义实现。在以下链接中查看。
https://pytorch-geometric.readthedocs.io/en/latest
Cora 数据集
我们将使用流行的 Cora 数据集,该数据集由 7 类以下的科学出版物组成。它通过引文连接,引文代表节点之间的边,即研究论文。

使用 networkx 的图形可视化产生了上面的图像。我们可以看到很少有颜色聚集在一起,让我们减少特征的维度并进行更多探索。
UMAP查看特征
解释数据的一种简单方法是查看数据它们的联系方式。UMAP 是一个非常有用的流形学习工具,它使我们能够做到这一点。
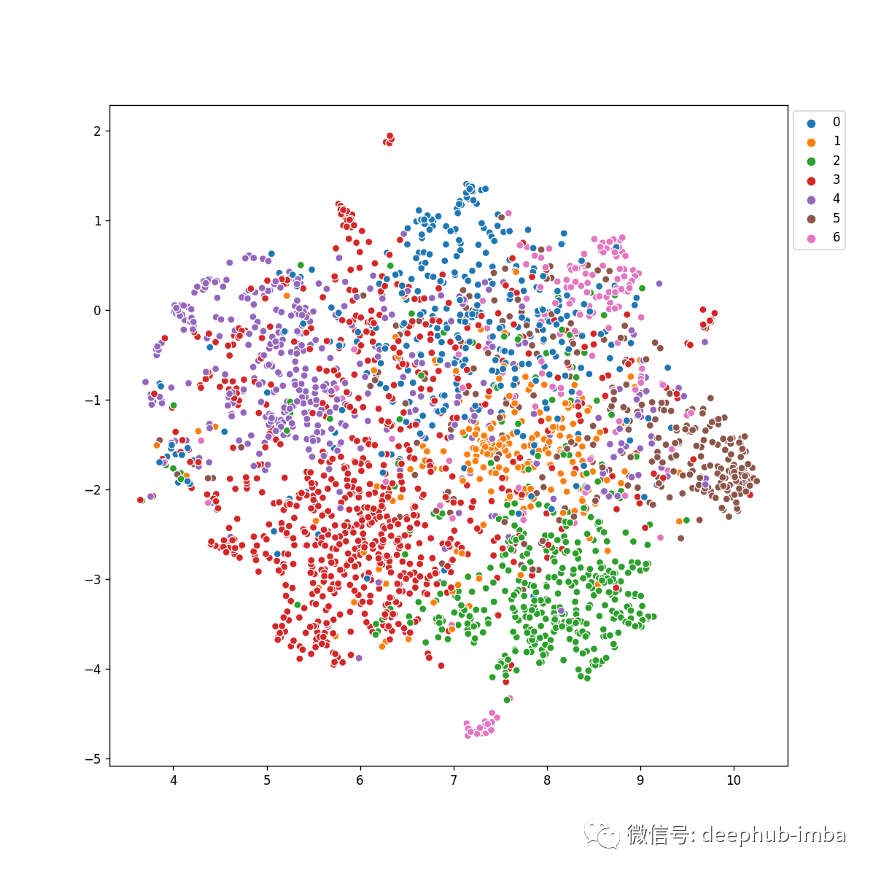
我们可以看到一些类的未知,但它也没法完整的区分。以上操作的简化代码如下(文末完整代码);
# essential imports that will be needed throughout the blog
importtorch
importtorch.nn.functionalasF
fromtorch_geometric.datasetsimportPlanetoid
fromtorch_geometric.nnimportGCNConv
importmatplotlib.pyplotasplt
importseabornassns
importumap
importnetworkxasnx
importnumpyasnpdataset = 'Cora'
path = "./"
dataset = Planetoid(path, dataset, transform=T.NormalizeFeatures())
data = dataset[0]embd = umap.UMAP().fit_transform(data.x.numpy())
plt.figure(figsize=(10, 10))
sns.scatterplot(x=embd.T[0], y=embd.T[1], hue=data.y.numpy(), palette=palette)
plt.legend(bbox_to_anchor=(1,1), loc='upper left')
我们肯定对所看到的不满意,所以让我们尝试 GCN 并查看可视化。我的网络如下(我从pytorch几何库github示例修改);
classNet(torch.nn.Module):
def__init__(self):
super(Net, self).__init__()
self.conv1 = GCNConv(dataset.num_features, 16, cached=True)
self.conv2 = GCNConv(16, 16, cached=True)
self.fc1 = torch.nn.Linear(16, dataset.num_classes)
defforward(self):
x, edge_index, edge_weight = data.x, data.edge_index,
data.edge_attr
x = self.conv1(x, edge_index, edge_weight)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index, edge_weight)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.fc1(x)
returnF.log_softmax(x, dim=1)
我们可以使用以下代码进行训练;
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model, data = Net().to(device), data.to(device)
optimizer = torch.optim.Adam([
dict(params=model.conv1.parameters(), weight_decay=5e-4),
dict(params=model.fc1.parameters(), weight_decay=5e-4),
dict(params=model.conv2.parameters(), weight_decay=0)
], lr=0.01)
def train():
model.train()
optimizer.zero_grad()
F.nll_loss(model()[data.train_mask],
data.y[data.train_mask]).backward()
optimizer.step()
请注意,Conv layer 2 中缺少 L2 正则化,这是 GCN 的作者凭经验决定的(https://github.com/tkipf/gcn/issues/108)。
可视化时,输出如下所示;
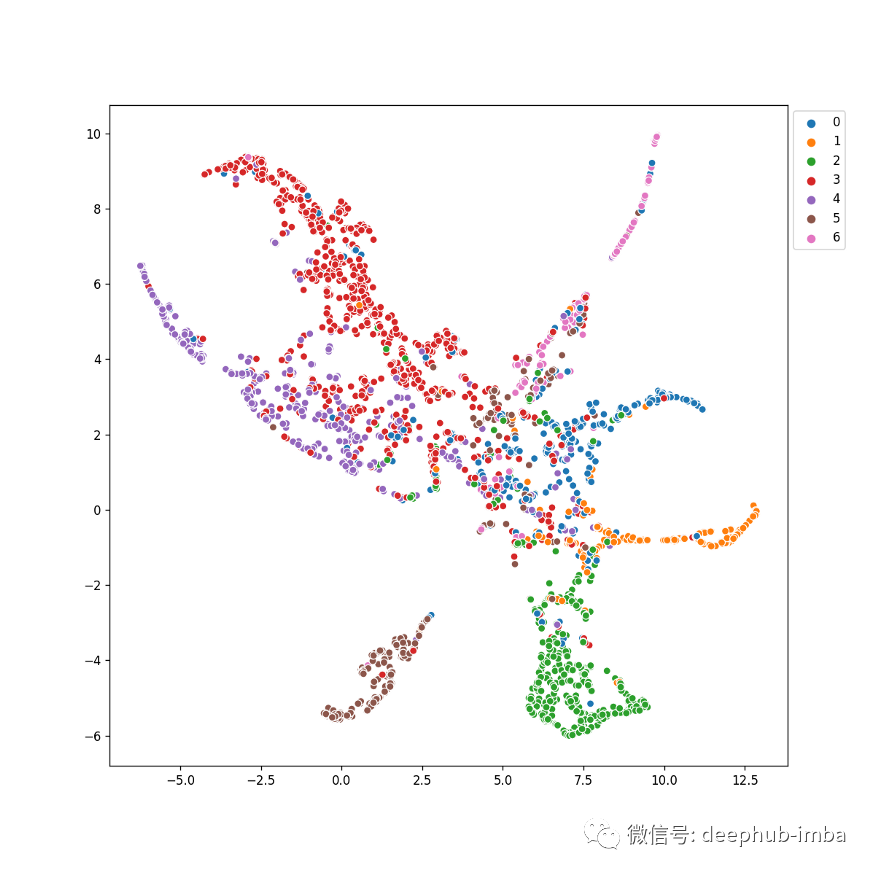
我们可以看到不同的类之间有非常清晰的分离。在这里,训练以 0.7800 的测试精度结束。我们可以多操作一点吗?让我们来看看。
Embedding losses
神经网络可以看作是连续的可微函数。分类本质上是学习预测的决策边界。
总之,如果我们强制网络有更好的边界,我们可以有更好的可视化。这意味着,我们应该能够分别看到这些类。如果我们可视化聚集簇的数据,这将特别有用。我们可以做的一件简单的事情是;
- 要求 GNN 更紧密地嵌入相似的类
- 要求 GNN 进一步嵌入不同的类
请注意,嵌入是网络的最终层输出或分类输出。在这种情况下,我们可以使用点积作为距离的度量。我们为这种损失准备如下数据点对;
y_neg_pairs = []
y_pos_pairs = []
data_idx = np.arange(len(data.x))
foridx1, y1inenumerate(data.y[data.train_mask].cpu().numpy()):
foridx2, y2inenumerate(data.y[data.train_mask].cpu().numpy()):
ifidx1>idx2andy1!=y2:
y_neg_pairs.append([idx1, idx2])
ifidx1>idx2andy1==y2:
y_pos_pairs.append([idx1, idx2])
y_neg_pairs = np.array(y_neg_pairs)
y_pos_pairs = np.array(y_pos_pairs)
我们的修正损失函数如下:
model_out = model()[data.train_mask]
y_true = data.y[data.train_mask]
nllloss = F.nll_loss(model_out, y_true)
#Negative loss
disloss_neg = F.logsigmoid(-1* (model_out[y_neg_pairs.T[0]]*model_out[y_neg_pairs.T[1]])).sum(-1).mean()
#Positive loss
disloss_pos = F.logsigmoid((model_out[y_pos_pairs.T[0]]*model_out[y_pos_pairs.T[1]])).sum(-1).mean()
loss = 10*nllloss-disloss_neg-disloss_pos
现在我们的训练结束了,损失为0.7720,比之前稍差。让我们可视化并查看使用UMAP的GNN的输出。

我们可以看到簇现在更好,噪音略小。尽管我们的准确性较低,但我们有更好的聚类分离。实际上,较小的测试损失是由于集群的不确定性。我们可以看到一些点自信地位于错误的颜色簇中。这主要是由于数据的性质。
将想法扩展到无监督聚类
当我们没有标签,只有特征和图时,我们如何扩展这个想法。 简单的想法是使用图拓扑将更近的节点嵌入得更近,反之亦然。代替我们的正负对,我们可以将直接连接对和随机对分别作为正负对。这在各个领域都显示出良好的效果 😊
我希望你喜欢这篇文章,我相信这对你的研究也会有用!
本文代码如下:https://gist.github.com/anuradhawick/bd2eb3f4e5f9c8030f8125d97dc686ac
作者:Anuradha Wickramarachchi