
标题选的好,绅士少不了。标题与文章的点击量有很大的联系,一个好的标题能够带来更多的读者。标题是潜在观众在决定是否阅读的文章之前首先看到的内容。作为一名数据科学家,我决定制作一个模型来帮助我使用 GPT2 生成这些标题。
数据
我制作了一个 csv 文件,其中包含我在 Medium.com 网站上使用 Parsehub 抓取的各种标签中最好的数据科学文章。csv 文件包含有关文章标题、使用的标签、作者、点在人数、回复数量等信息。该数据集可在 Kaggle 上获得,称为 Medium-Search-Dataset。
任务
我的任务是制作一个文本生成器来生成连贯的文章标题。我将使用 Transformers 库进行预处理和模型构建,然后我将使用 PyTorch Lightning 微调模型。
安装Transformers
使用以下命令安装 Transformers。
pip install transformers
你可以在 Kaggle 和 Github 上查看完整的代码(链接最后提供)。我建议在 Kaggle 而不是本地机器运行这个 notebook,因为 Kaggle 已经在环境中安装了大部分依赖项。Pytorch Lightning 将用作包装类以加快模型构建。
运行下面的单元格以确保安装了所有必需的包。如果你没有安装所有的包,它会抛出一个错误。
from transformers import GPT2LMHeadModel, GPT2Tokenizer,AdamW
import pandas as pd
from torch.utils.data import Dataset , DataLoader
import pytorch_lightning as pl
from sklearn.model_selection import train_test_split
数据
df = pd.read_csv("../input/mediumsearchdataset/Train.csv")
df

我将下载 GPT2-large 。它的大小为 3 GB,这就是为什么我建议使用像 Kaggle 这样的远程笔记本。
tokenizer = GPT2Tokenizer.from_pretrained("gpt2-large")
gpt2 = GPT2LMHeadModel.from_pretrained("gpt2-large")

在微调前可以测试 一下GPT2的模型
tokenizer.pad_token = tokenizer.eos_token
prompt = tokenizer.encode("machine learning", max_length = 30 , padding = "max_length" , truncation = True , return_tensors = "pt")
output = gpt2.generate(prompt,do_sample = True, max_length = 100,top_k = 10, temperature = 0.8)
tokenizer.decode(output[0] , skip_special_tokens = True)
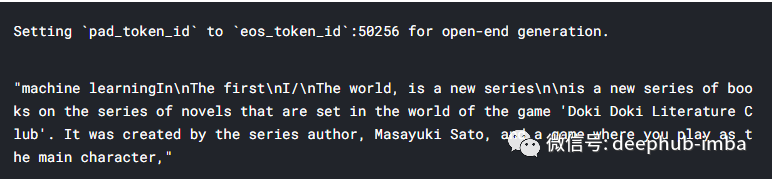
正如我们所看到的,该模型确实在我们输入的“机器学习”上生成文本,但是它生成的与标题差的太多了。在以下部分中,我们将微调模型以生成更好的文本。
下面我们要自定义一个数据集,它将创建标记化的标题并将其发送到数据集。
class TitleDataset(Dataset):
def __init__(self,titles):
self.tokenizer = tokenizer
self.titles = titles
def __len__(self):
return len(self.titles)
def __getitem__(self,index):
title = self.titles[index]
title_token = tokenizer.encode(title , max_length = 30 , padding = "max_length" , truncation = True, return_tensors = "pt").reshape(-1)
return title_token
#sanity check
dset = TitleDataset(df["post_name"].values)
title = next(iter(DataLoader(dset , batch_size = 1,shuffle = True)))
display(title)

class Quadratic_Module(pl.LightningDataModule):
def __init__(self):
super().__init__()
self.train_dataset = Quadratic_Dataset(path = train_df["id"].values , targets = train_df[["a_","b_", "c_"]].values)
self.test_dataset = Quadratic_Dataset(path = test_df["id"].values , targets = test_df[["a_","b_" , "c_"]].values)
self.val_dataset = Quadratic_Dataset(path = val_df["id"].values , targets = val_df[["a_","b_" , "c_"]].values)
self.predictions = Quadratic_Dataset(path = test_df["id"].values , targets = None)def prepare_data(self) :
pass
def train_dataloader(self):
return DataLoader(self.train_dataset , batch_size = 32 , shuffle = True)def test_dataloader(self):
return DataLoader(self.test_dataset , batch_size = 32 , shuffle = False)def val_dataloader(self):
return DataLoader(self.val_dataset , batch_size = 32 , shuffle = False)
def predict_dataloader(self):
return DataLoader(self.predictions , batch_size = 1 , shuffle = False)
以上是数据读取的一些辅助函数,帮助我们生成dataloader
当文本传递给 GPT2 时,它会返回输出 logits 和模型的损失,因为pytorch lighting是这样要求的。
class TitleGenerator(pl.LightningModule):
def __init__(self):
super().__init__()
self.neural_net = gpt2_model
def forward(self,x):
return self.neural_net(x , labels = x)
def configure_optimizers(self):
return AdamW(self.parameters(), 1e-4)
def training_step(self,batch,batch_idx):
x= batch
output = self(x)
return output.loss
def test_step(self,batch,batch_idx):
x= batch
output = self(x)
return output.loss
def validation_step(self,batch,batch_idx):
x= batch
output = self(x)
return output.loss
训练
微调 GPT2 模型需要很长时间我建议使用 GPU(如果可用)。Lightning 允许我们在训练器中声明 GPU,同时处理其余部分。6轮训练应该需要大约 30 分钟。
from pytorch_lightning import Trainer
model = TitleGenerator()
module = TitleDataModule()
trainer = Trainer(max_epochs = 6,gpus = 1)
trainer.fit(model,module)

训练完成后可以进行测试和预测
如果你计划将代码部署到生产中,我不建议这样做,因为它可能会导致错误。以下代码是改变原始模型权重的快速的方法,但是她会有一些问题。
raw_text = ["The" ,"machine Learning" , "A" , "Data science" , "AI" , "A" , "The" , "Why" , "how"]
for x in raw_text:
prompts = tokenizer.encode(x , return_tensors = "pt")
outputs = gpt2.generate(prompt,do_sample = True, max_length = 32,top_k = 10, temperature = 0.8)
display(tokenizer.decode(outputs[0] , skip_special_tokens = True))

最后说明
我会将该模型部署为 API,但该模型超过 3 GB,将其托管在网站上确实没有意义。你也可以尝试在微调后将模型上传到 Huggingface hub上。
代码地址在这里:https://github.com/Aristotle609/Medium-Title-Generator
或者直接fork这个kaggle的代码:https://www.kaggle.com/aristotle609/medium-titles-generator
本文作者:Aristotle Fernandes