
正如您现在听说的那样,生成对抗网络是一种能够从生成器和鉴别器之间的竞争中学习分布的框架。生成器学习生成希望与真实数据无法区分的样本,而鉴别器学习分类给定图像是真实的还是虚假的。自 GAN 发明以来,它们经历了各种改进,被认为是用于各种问题的强大工具,尤其是在生成和重建任务中。
大量工作都集中在 GAN 的基本目标上,即 GAN 的训练损失。这篇论文项研究显示了证据表明它们在 GAN 的性能方面并不重要。事实上,通过足够的超参数搜索,几乎所有算法都有随机排名,甚至最新的的模型也也与 Ian Goodfellow 提出的原始 GAN 表现相似。
今天要介绍的论文主要有以下内容:
- 在大规模实验中比较了各种GAN损失的性能。
- 建议将精确度和召回率作为特定领域的性能指标。
- 如果你想深入了解GAN的训练,请直接看结论。
评价GANs的经典方法
GAN 研究中的一项挑战是关于评估生成图像质量的定量指标。两个常用的指标是 Inception Score (IS) 和 Fréchet Inception Distance (FID)。这些方法都依赖于经过图像识别训练的分类器。我们将很快讨论这些指标的特征。
IS结合了当有意义的对象存在时标签分布应该具有低熵的并且样本的可变性应该高的想法。它是根据生成图像的特征分布计算的。但是IS 不是一个合适的距离,可能是因为它没有以任何方式包含真实图像的分布(论文中没有明确阐述)。
FID 测量预训练分类器的网络特征空间中统计量的距离。我们将特征视为基于真实和虚假图像的均值和协方差的高斯特征,并测量两个高斯特征之间的 Fréchet 距离。FID 解决了称为intra-class mode dropping的 IS 问题,例如,每个类仅生成一个图像的模型可以获得良好的 IS,但会具有糟糕的 FID。此外,根据之前的实验,它们图像质量方面更可靠。

准确率和召回率
FID 和 IS 都没有检测过拟合的能力,比如防止网络完美地记住训练样本。我们设计了一种方法来弥补 FID 在评估 GAN 性能方面的弱点。

准确率、召回率和 F1 分数是广泛用于评估预测质量的指标。我们构建了一个带有多样体(manifold,一般翻译成流形,我觉得这样不通,改成叫多样体会好点,哲学里面翻译叫"杂多",DIO sama:咋瓦鲁多🤭)的数据集,以便可以有效地计算从样本到多样体的距离。我们可以根据到多样体的距离直观地评估样本的质量。如果模型分布中的样本接近多样体,则其精度高,如果生成器可以从多样体中恢复任何样本,则召回率高。
数据集在上图中被描述为灰度三角形的分布。我们将样本到多样体的距离定义为到多样体中最近样本的欧几里得距离的平方。精度定义为距离低于 δ = 0.75 的样本的比率。我们将测试集中的 n 个样本转化为潜在向量 z* 并计算 x 和 G(z*) 之间的距离。通过反演,我们找到了最接近或精确地恢复给定图像的潜在,求解下面的方程。召回率定义为距离小于δ的样本的比率。上面解释了它们的直观概念。

各种GAN

GAN 的设计和损失因问题而异,但我们的实验将关注无条件图像生成。上面描述的 GAN 可能看起来很相似,因为抽象地讲,生成器和鉴别器正在以某种方式优化彼此相反的目标。然而,它们不仅在计算生成器和鉴别器的每个损失的方式上有所不同,而且在优化根本不同的距离。
原始的 GAN(MM GAN) 框架近似优化了生成和真实分布之间的 JS 散度。WGAN 和 WGAN-GP 在 Lipschitz 平滑假设下最小化 Wasserstein 距离。LSGAN 最小化 Pearson χ² 散度。每个 GAN 在分布之间的距离类型以及如何近似距离方面都有非常不同的理论背景,因为在大多数情况下它们是不可计算的。
实验设计
评估指标必须有效、公平且不能增加太多计算量。因此,我们使用 FID 分数和精度、召回率和 F1 作为指标。模型的性能通常因超参数、随机性(初始化)或数据集而异。
为了抵消除损失之外的算法组件的影响,我们
对所有模型使用相同的 INFO GAN 架构。(除了使用自动编码器的 BEGAN、VAE)
对每个数据集执行超参数优化。
从随机种子开始。
在 4 个中小型数据集(CelebA、CIFAR10、Fashion-MNIST、MNIST)上进行实验。
训练多个计算。
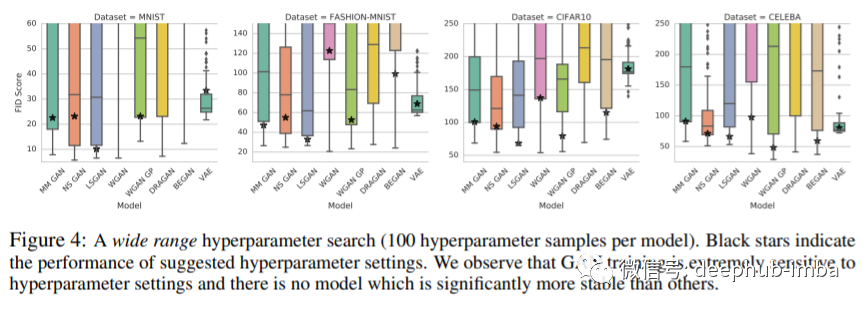
根据上面的图,作者发现超参数搜索是必要的,其中搜索的超参数对最终性能有很大的影响。关于超参数搜索过程的详细信息在原论文中提供。
总结
这表明,在最先进的gan中,算法差异不是很相关,但超参数搜索有更大的影响。
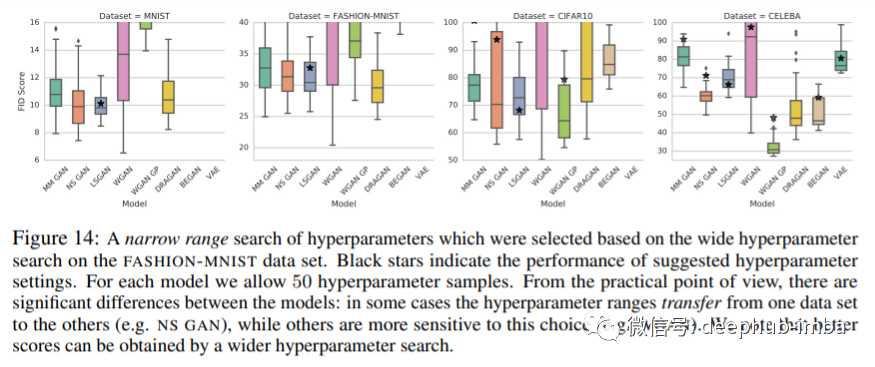
最优超参数在很大程度上取决于数据集。如上图所示,除了LSGAN外,black star 超参数在不同的数据集上表现得非常糟糕。
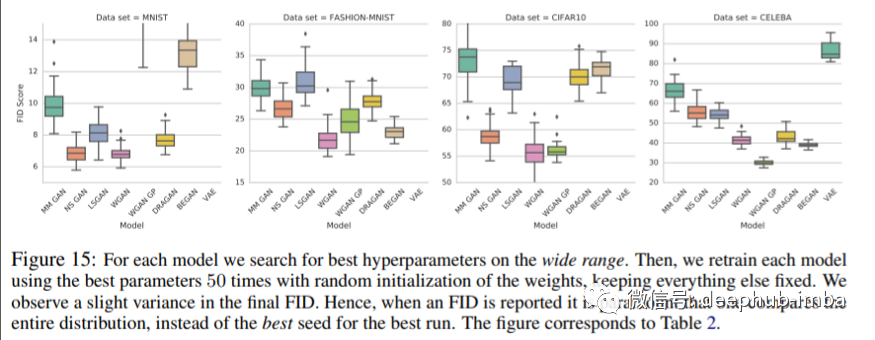
由于随机种子导致最终性能始终存在差异,因此我们必须比较运行的分布以进行公平比较。
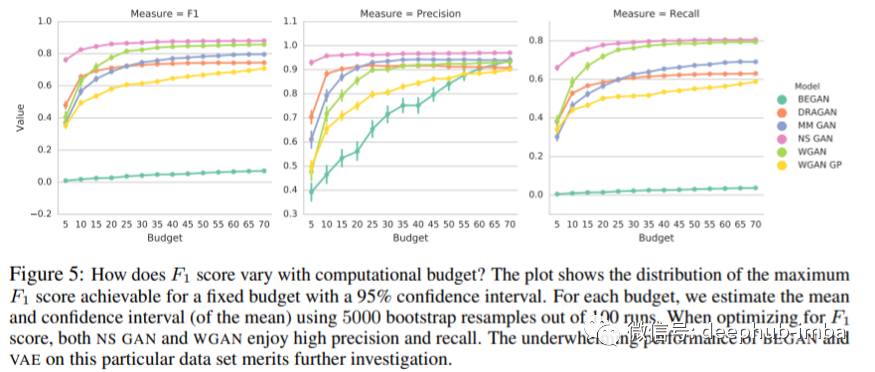
许多模型的 F1 分数很差,并且在对其进行优化时似乎会有所改进。
最后论文如下:arxiv 1711.10337
作者:Sieun Park