
知识蒸馏是一种将知识从一组繁琐的模型中提取出来并将其压缩成单个模型的方法,以便能够部署到现实生活中的应用程序中。知识蒸馏是由人工智能教父 Geoffrey Hinton 和他在谷歌的两位同事 Oriol Vinyals 和 Jeff Dean 于 2015 年引入的。
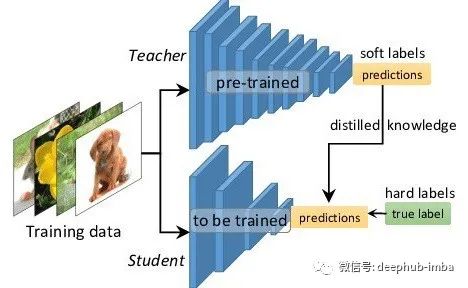
知识蒸馏是指将繁琐的模型(教师)的学习行为转移到较小的模型(学生),其中,教师模型产生的输出作为训练学生的“软目标”。作者揭示了他们在MNIST数据集上取得了令人惊讶的结果,并表明将一组模型中的知识提取到一个单一模型中可以获得显著的改进。
图像分类的知识蒸馏
Hinton和他的两位合著者在《Neural Network: extraction the knowledge in a Neural Network》中首次介绍了他们用于图像分类任务的知识蒸馏。论文中写道,知识蒸馏最简单的形式是将蒸馏后的模型在具有软目标分布的迁移数据集上进行训练。到目前为止,我们有两个目标用于训练学生模型。一是教师网络生成的正确标签(硬标签),另一种是上述提出的软标签。因此,目标函数是两个不同目标函数的加权平均。第一个目标函数是学生预测与软目标之间的交叉熵损失,第二个目标函数是学生输出与正确标签之间的交叉熵损失。作者还提到,通常通过对第二个目标函数使用较低的权重来获得最佳结果。
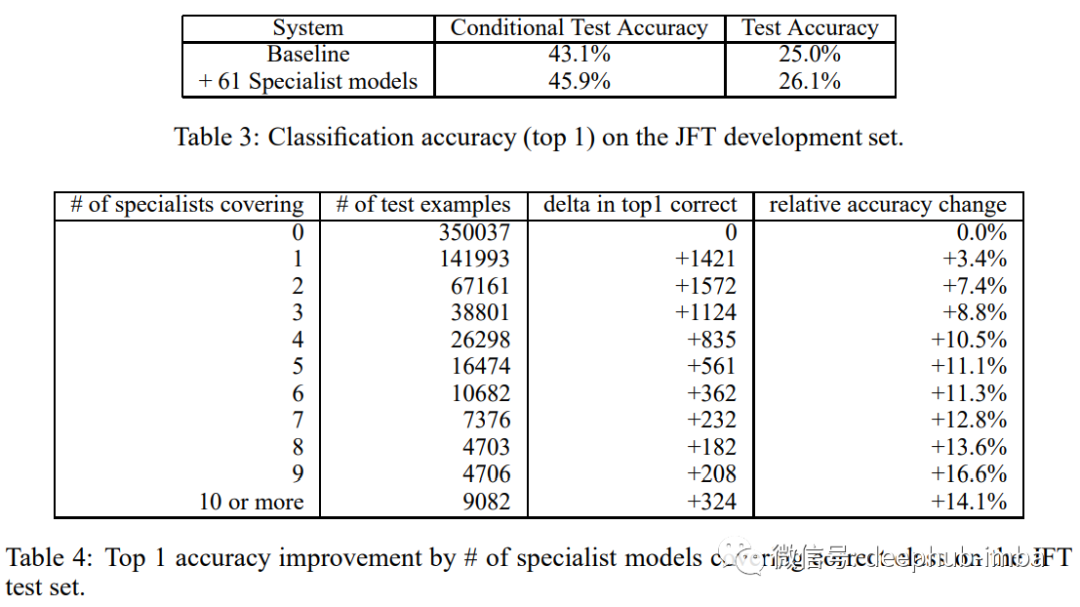
本文得出的一些令人惊讶的结果如下所示,详见原文:

目标检测的知识蒸馏
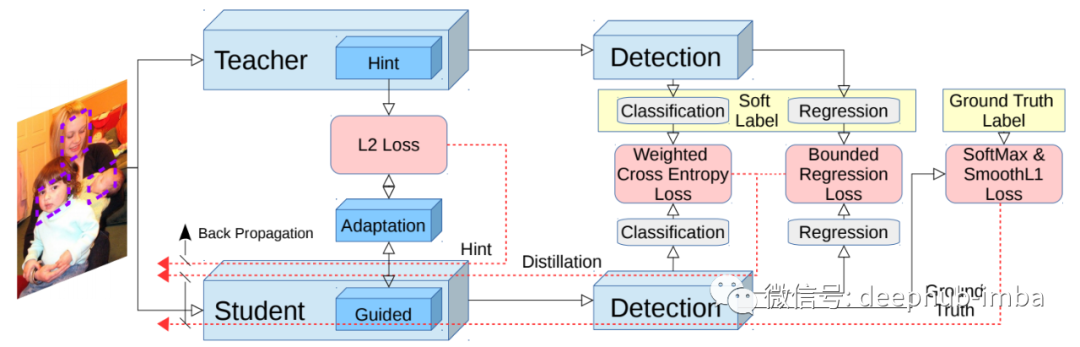
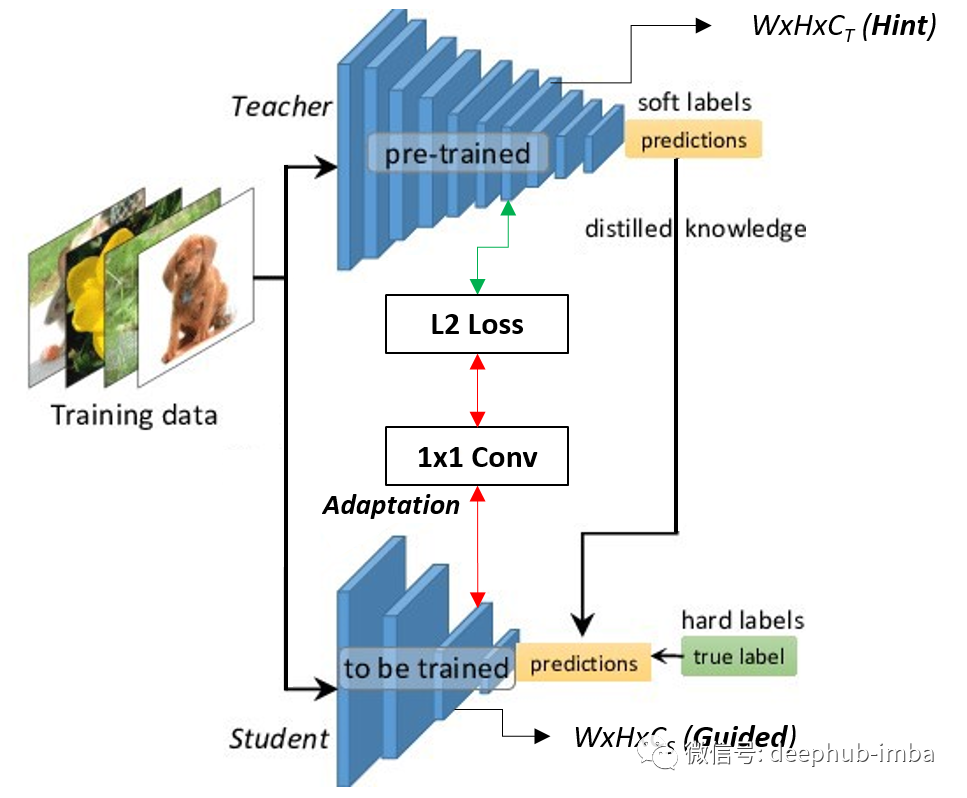
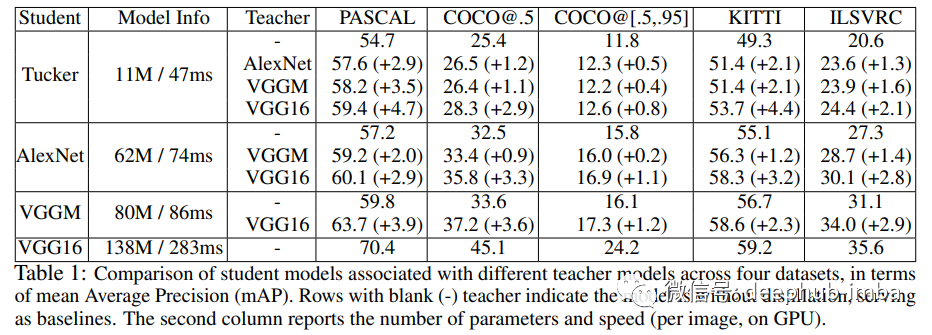
在neuroips 2017上,Guobin Chen等人发表了基于知识蒸馏结合hint learning的目标检测研究论文:learning Efficient object detection Models with knowledge distillation。在他们的方法中,他们进一步使用从教师中间层获得的特征图作为提示,引导学生尽可能接近地学习教师的行为。此外,为了获得最佳的知识提取性能,还需要一个适应层,这个适应层将在后面讨论。Faster-RCNN是本文实验使用的目标检测网络。他们的学习方案如下图所示:
学习目标函数为:
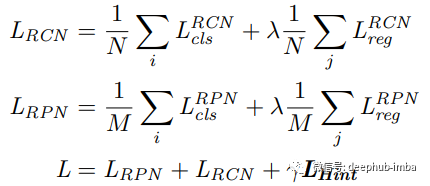
公式中RCN、RPN分别为regression-and-classification和区 region proposal network;N、M分别为RCN、RPN的批大小;L_RCN、L_RPN、L_Hint分别为RCN、RPN、hint的损失;λ(通常为1)和γ(通常设置为0.5)是控制最终盛损失的超参数。
Hint Learning
Adriana Romero在《FitNets: Hints for Thin Deep Nets》一文中证明,利用教师网络的中间表示作为提示,帮助学生进行训练过程,可以提高学生网络的性能。因此,使用L1距离计算提示特征Z(教师中间层得到的特征图)与引导特征V(学生中间层的特征图)之间的损失。
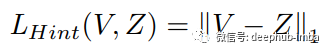
或L2距离,
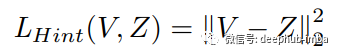
下图是我在WAYMO数据集上训练的YOLOv4模型提取的特征图。WAYMO数据集是我的一个知识蒸馏目标检测项目。在这些示例中,输入图像的大小被调整为800x800。


知识蒸馏+Hint Learning
使用Hint Learning需要提示特征和引导特征具有相同的形状(高x宽x通道)。此外,提示特征和引导特征始终不在一个相似的特征空间中,因此使用一个适应层(通常是1x1卷积层)来帮助提高知识从教师到学生的转移。
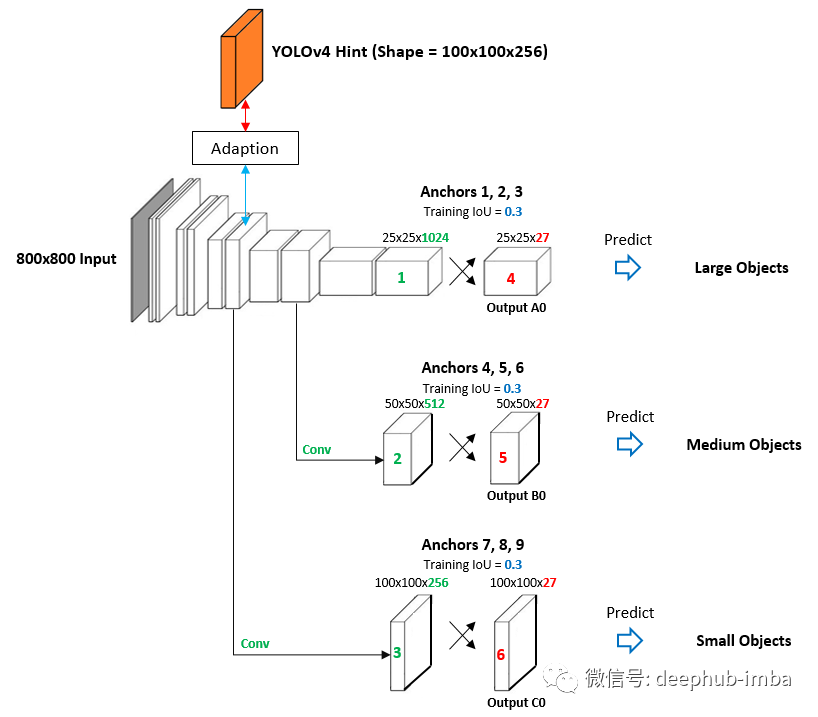
下图描述了我在我的目标检测项目中正在进行的学习方案,我使用一个三级检测的小网络从预先训练的YOLOv4中提取知识。
Guobin Chen将知识蒸馏和Hint Learning相结合进行目标检测,取得了很好的效果。详细内容请参见原论文Learning Efficient Object Detection Models with Knowledge extraction。
总结
在这篇文章中,我简要介绍了知识蒸馏和Hint Learning。知识蒸馏是将复杂模型集合中的知识转化为更小、更精炼模型的有效方法。将提示学习与知识提取相结合是提高神经网络性能的有效方法。
以下是本文提到的三篇论文:
https://arxiv.org/abs/1503.02531
https://arxiv.org/abs/1412.6550
https://paperswithcode.com/paper/learning-efficient-object-detection-models
作者:LA Tran