
需求背景
即席查询AD-HOC :以单独的SQL语句的形式执行的查询就是即席查询,比如说:HUE里面输入SQL语句并获得结果或者使用dbeaver连接hiveserver2自己键入的SQL代码并获取结果,这样的操作就是即席查询。
我们可以把OLAP分为两大类,即席查询就是其中的一类,另外一类可以被称作固化查询。它们之间的差别在于,固化查询在系统设计和实施时是已知的我们可以在系统中通过分区、预计算等技术来优化这些查询使这些查询的效率很高,而即席查询是用户在使用时临时生产的,查询的内容无法提前运算和预测。
对于数仓来说,即席查询的响应程度也就成为了评估数据仓库的一个重要指标。对于即席查询的支持程度不仅仅是对数据仓库设计的要求,也是对于整个数据平台架构的要求。在整个系统中即席查询使用的越多,对系统的要求就越高,对数仓中数据模型的对称性的要求也越高。(这里所说的对称性指的是:数据模型对所有的查询都是相同的,这也是维度建模的一个优点)
能够快速的执行自定义SQL对即席查询来说是最基本的要求,一般情况下即席查询基本上都是从全量的详细数据中进行过滤筛选,并且需要在短时间内给出查询的结果,这就对响应速度有了严格的要求,从查询输入到用户得到结果必须是秒级的相应。对于Hive这样的离线数仓肯定是满足不了这样的需求,所以就产生各种架构的查询引擎/系统。
引擎介绍和对比
这里我根据不同的实现方式把支持即席查询的系统分成了3个类别:
预计算
Kylin:通过建立cube模型,将事实表、维度、度量之间进行各种的排列组合和预计算,用户查询的结果直接从cube中获取,通过预计算的方式简化查询的计算量。这种方式对于数据模型的要求是最高的,因为要求所有的查询必须满足cube建立时的维度,对于新增维度需要从新进行计算,所以可以说Kylin其实对于固化查询是一个非常好的工具,但是对于查询目标本身就不定的即席查询支持度还是太低了。
数据存储
这个名字其实不太恰当,但是我实在想不出其他的词汇了。
Elasticsearch:他出现在这里并不奇怪,因为作为OLAP的要求他都可以达到,但是因为ES其实是一个搜索引擎,所以查询方面的支持还是比较少,比如不支持index之间的join,另外一个问题就是ES聚合不准,甚至有可能排序的结果也不准,这是因为ES的分片计算框架导致的,具体可以看官网说明:https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket-terms-aggregation.html
Apache Druid :一个分布式的支持实时分析的数据存储系统,旨在快速提取大量事件数据,并在数据之上提供低延迟查询。它核心设计结合了数据仓库,时间序列数据库和搜索系统的想法,从而创建了一个统一的系统。Druid 的最大好处是All In One,基本上安装完成后就可以直接使用,从数据导入到提供查询,完全不需要其他的组件支持Druid 全部都能够搞定。这样很方便,但是Druid 因为结合了时序数据库的特点,在导入时必须要指定时间字段(查询时好像也要指定,只做过测试后面就没线上使用所以不太确认了),使得druid并不适应所有的业务并且和ES一样聚合也不准,对于传统的数仓迁移或升级,这个就不要考虑了。Druid 更适合带有时间字段的数据,最显而易见的就是用户访问行为的数据或者监控类的数据。
MPP分布式并行处理
Greenplum:其实GP出现的时间是比较早的,应该是06,07年与Hadoop基本上是一同发布的。关系型数据库Postgres的团队因为hadoop的出现开始关注SQL on Hadoop的开发,慢慢成立了商业公司并开始商业化,所以GP才以Postgres作为底层的存储。后来以GP的架构开发了HAWQ (可以理解为GP的MPP 架构,但是后端不使用Postgres,而是HDFS、Hive、HBase)。使用GP的优点是简单方便,跟普通使用数据库是一样的,但是缺点也很明显,集群规模受物理Master限制,应用中很难超过20个物理节点,所以对于中等数据量还是可以的,中小公司几十TB到几百TB大小的一般应用是可以的。另外还一个要说明的是因为是独立架构,所以对于Hadoop生态的兼容性几乎为0。
Oracle RAC:其实GP做的事情RAC也是一样的,都是把表做成Hash+Range分区,理论上都是一样的只不过实现方式不一样,Oracle最大的问题是扩展能力也有限,其实还是钱有限😉,我没钱尝试所以就不多废话了。
Apache Doris和Click House:这两个放在一起说是因为都是MPP分析型数据库产品,Doris是百度的,Click House是Yandex的又都是搜索引擎,二者的原理也都一致。一般情况下PB 内的数据都是可以,再大还是Hive稳,因为2000台左右的HDFS优化好后基本不需要改源代码做定制,再大就要做Federation了例如2.x的viewfs或者3.x的rbf。
Doris是有自己的存储后端,所有的数据都需要导入到自己的存储统一管理(提供基本的导入工具),如果有其他的数仓的话就意味着数据需要存两份。ClickHouse也是一样,自己的mergetree引擎查询速度飞起,除此以外还支持HDFS的表引擎(只能一个表一个表建),这样就可以通过hive创建外部表,然后通过HDFS表引擎关联hdfs上的文件(这就是为什么我这边hive上的表都用Parquet格式)做到数据同源,因为读取的是HDFS上的数据,所以查询的速度也明显要比mergetree慢。
另外一点就是ClickHouse的join写法比较特殊并且性能不好,ClickHouse的策略是尽可能的占用所有资源去计算所以不能支持高并发的使用场景。一般情况下我们都是将一张大宽表放到ClickHouse中进行查询。所以使用Hive作为离线任务,数据处理完成以后通过HDFS表引擎直接创建临时交互表,然后再转到mergetree引擎表中或者直接导入到mergetree表,查询全部使用宽表进行,提高查询的响应速度。但这样数据还是存了2份。
Presto和Impala:这两个放到一起是因为可以算是Hadoop生态上的MPP引擎,都可以使用Hive的metastore无缝集成Hive(因为都是计算引擎,不存储),非常相似的技术、架构也很相似并且同是内存计算(都很费内存)。impala要求128 GB以上的内存,其实没有那么大,一般8G就够用了。
对于性能方面的评测,19年易观整理了一个完整的测试,有兴趣的可以看看:https://github.com/analysys/public-docs/
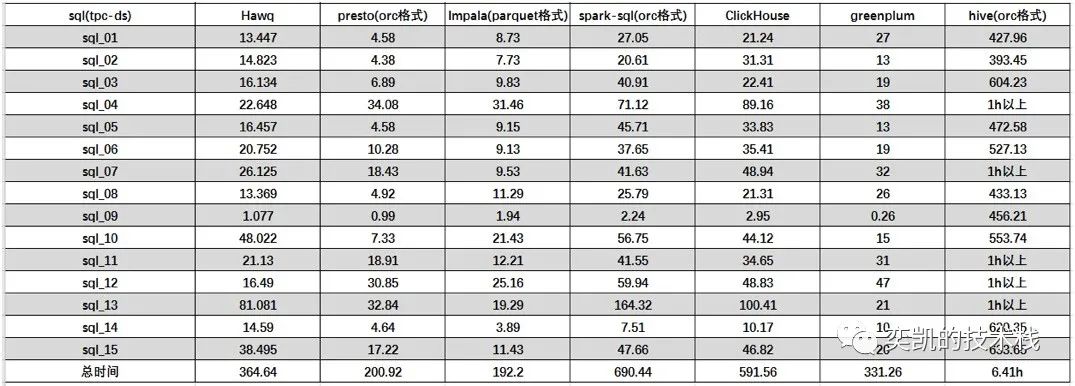
这里我截个图,供参考:
这图是多表的
这个图是单表的
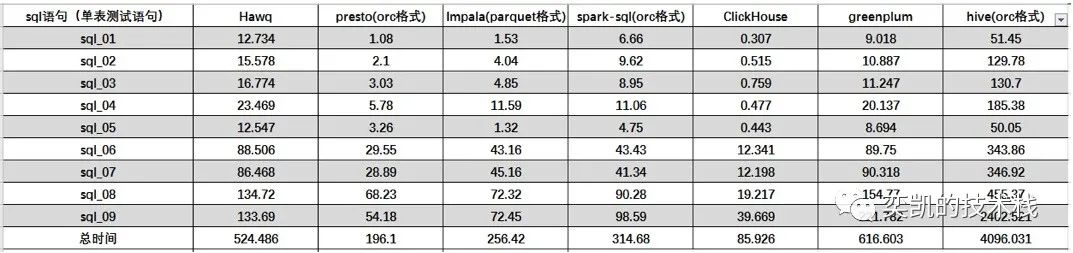
这里以Hive为基线,因为现在hive的作用更多的是metastore和离线任务,在hadoop生态中将各个组件使用的元数据统一的管理并在此基础上数据也尽量做到统一。单表ClickHouse速度绝对的第一,Presto对于单表速度也有明显的优势。对于多表的查询,Presto和Impala不相上下,对比其他的引擎性能要好一些。greenplum也不错;ClickHouse对于多表join所以效果不好,并且上面说了很多复杂语法支持的不够好。
选型推荐
这里的选型考虑到了数据计算的准确性,所以Apache Druid,ES首先被排除,除非你们能接受数据不准(不要妄想用它给财务出报表,用户行为数据另说不在今天的讨论范围内)。如果你们没有hadoop平台(以后也不想用),数据量也不大(PB内),完全可以使用GP和Doris,因为这俩完全可以当作传统的数据库来用。
Click House速度最快,但是不能完全独立承担这个任务,后面还是需要一个完整的离线计算流程,比如Hive,ClickHouse的最终角色是对于大宽表的查询,可以理解为DM层。
如果你有Hive的离线数仓,又想引入即席查询的功能,那就选Presto和Impala。
我的测试Presto和Impala多表查询性能差不多,单表查询方面Presto好。并且Impala在查询时占用的内存比Presto大。二者目前都对ORC的格式支持的很好(以前是不行的)。Impala的一个好处Coordinator是无单点的,并且计算中间结果不仅保存在内存,还可以在磁盘中,但是Presto的中间结果磁盘方案不成熟。相比于Impala,Presto综合性能要更好一些,支持数据源丰富并且将外部数据源抽离成connector,可以方便的引入更多的连接。Presto开源社区和生态更加广泛,例如亚马逊的Athena就是使用Presto作为引擎来进行构建的。
Presto最大的优势是支持跨数据源的join,例如我们可以用Mysql的表和Hive表做Join,将得到正确的计算结果保存到Oracle中。所以它不仅仅能做ad hoc和olap,还可以做ETL的操作😏。
这两个还有一个相同的问题就是对于hadoop资源抢占的问题。这两个引擎的worker节点官方都建议部署在datanode节点,但是这两个引擎都无法使用yarn进行资源管理,所以如果配置大了会占用yarn资源,配置小了遇到查询多了就OOM了,这个是一个要慎重规划的问题。
那么我们怎么选择呢?
本着有有乔选乔,无乔选鲨 的理论:
如果你们的集群是CDH,那么直接上Impala就可以了,因为安装就是点个按钮的事,CDH上装Presto就要完整的手动安装了,既然因为懒选了CDH那就懒到底,点个按钮就能装好他不香吗。
如果你跟我一样喜欢Apache原生的Hadoop,那么就装Presto吧,安装配置也很简单几步就搞定了,关键还可以做成ansible的playbook,一步到位。裸装Impala的话就比较麻烦,官方没有二进制版本,后端是用c++实现的所以编译起来很麻烦。不建议自找麻烦安装,当然百度一下有人已经编译好了,拿来是可以用的。
如果你有多数据源联合查询的需求,那么直接Presto吧因为没得选。
最后就是二者对于实时数仓的支持:
Impala:直接上Kudu就可以了一个公司的不会支持不好。但是这样问题又来了,不用hdfs又多了一个存储系统,分几个盘,怎么分盘,维护很麻烦。所以有些事情刚开始为了省事到了后面就会越来越麻烦。
Presto:可以适配Iceberg,Iceberg又可以使用HDFS,这不是很完美么,有些事情开始看似多做了很多但是到了后面会越来越简单。
Presto注意事项
时间类型
Presto的日期格式化函数与Hive有点不同,比如在Hive中,我们要格式化一个日期
date_format('2016-08-16','yyyyMMdd')
Presto中需要先把字符串的日期转化成时间戳,因为无法自动隐式转换
format_datetime(cast('2016-08-16'as timestamp),'yyyyMMdd')--如果毫秒,后面加.
Presto中也可以使用date_format函数,但是他的格式是与mysql相同的
date_format((cast('2016-08-16'as timestamp),'%Y-%m-%d %H:%i:%s') --如果毫秒,要使用 %f
所以为了统一规则,最好的办法就是将date_format直接替换成format_datetime
计算时间间隔:相差的时间小于24小时,Presto输出的是0,而Hive是1,这个坑要注意一下。Presto是时间大的放后面,而Hive是时间大的放前面。这俩结果是不一样的
select date_diff('day', cast('2020-07-23 15:01:13'astimestamp), cast('2020-07-24 11:42:58'astimestamp))selectdatediff('2020-07-24 11:42:58','2020-07-23 15:01:13');`
Presto的时间相关的函数基本上与Mysql类似,这个也要注意下。
关键字冲突
解决列名与关键字冲突的方式在hive中使用反引号,而Presto中与Oracle一样使用双引号。
ORC支持
以前对ORC支持的不好,后来已经优化了,可以支持了。
尽量少用Insert
Presto作为即席查询引擎,尽量少用Insert,我们的目的是查询而不是etl。
以前版本Parquet格式不支持insert,不支持 insert overwrite 只能先delete再insert 不知道最新版改了没有,因为我们在Presto上基本不用这几个操作。
常用的hive函数对应
collect_list-> array_aggconcat_ws-> array_joincollect_set-> array_agg 后 array_distinct去重
行专列
Hive:split拆分成数组,lateral view explode将数组分开
lateral view explode(split(id_list, ',')) b as oid ;
Presto:split拆分成数组,cross join unnest将数组分开,要注意一下两种语法的表名缩写位置不同
cross joinunnest(split(id_list, ',')) asb(oid) ;
JSON函数
get_json_object(json,'$.aaa') -- hivejson_extract(json,'$.aaa') --Presto
Map和List类型
这两种类型Presto支持都是没问题的,可以放心使用
但是数组下标,Hive是从0开始的,Presto是从1开始的。
数据转换
--hive5/2 =2.5--Presto5/2 = 25/2.0 = 2.55.0/2 =2.5
如果除法两边都为整型,那么结果也是整型,这个要强调一下,一定不要错。
Presto安装遇到的坑
虽然Presto的安装非常简单,但是也会遇到坑,例如我遇到的这两个
Oracle Connector
如果你按照官网配置了Oracle Connector ,但是缺提示 logon denied,这是因为Oracle Connector 的跟本没有读取配置中的username和password,看这个Issues:https://github.com/prestodb/presto/issues/15232
所以你需要在配置JDBC的url的时候将用户名密码添加进去,但是这里又来了一个问题,如果密码中包含关键字怎么办,这就需要使用双引号括起来。最后是这样的:
username/"p@ssword"@database
不支持的字符集 (在类路径中添加 orai18n.jar): ZHS16GBK
这个也是出现在Oracle Connector中,只需要将Oracle Connector目录中的ojdbc*.jar这个文件删除,然后替换Oracle官网下载的通用的ojdbc8.jar就可以了。
所以这个Oracle Connector就是个半成品啊出的问题都在这里,但是它运行的速度倒是不慢😂
写了这么多,使用Presto遇到的大部分问题我都帮你总结了,选择Presto肯定是没错的。
喜欢就关注一下吧: