

背景
典型的机器学习工作流程是数据处理、特征处理、模型训练和评估的迭代循环。想象一下,必须对数据处理方法、模型算法和超参数的不同组合进行试验,直到我们获得令人满意的模型性能。这项费时费力的任务通常在超参数优化期间执行。

超参数优化
超参数优化的目标是找到最佳模型管道组件及其关联的超参数。让我们假设一个简单的模型管道,它有两个管道组件:一个输入器,然后是一个随机森林分类器。

输入步骤有一个超参数称为“strategy”,它决定了如何执行输入,例如使用平均值、中值或众数。随机森林分类器有一个称为“depth”的超参数,它决定了森林中单个决策树的最大深度。我们的目标是找出哪个跨模型管道组件的超参数组合能提供最好的结果。超参数优化的两种常见方法是使用Grid Search或Random Search。
Grid Search
对于每个超参数,我们生成一个可能值的列表,并尝试所有可能的值组合。在我们的简单示例中,我们有3种输入策略和3种不同的随机森林分类器深度来尝试,因此总共有9种不同的组合。

Random Search
在随机搜索中,我们定义了每个超参数的范围和选择,并在这些范围内随机选择超参数集。在我们的简单例子中,深度的范围是2到6之间,输入策略的选择是平均值、中值或众数。

Grid和Random Search中的超参数集是相互独立选择的。这两种方法都没有利用以前的训练和评估试验的结果来改善下一次试验的结果。进行超参数优化的一种更有效的方法是利用以前试验的结果来改进下一次试验的超参数选择。这种方法被用于贝叶斯优化。
贝叶斯优化
贝叶斯优化存储先验搜索的超参数和预定义目标函数的结果(如二进制交叉熵损失),并使用它来创建代理模型。代理模型的目的是在给定一组特定的候选超参数的情况下快速估计实际模型的性能。这允许我们决定是否应该使用候选超参数集合来训练实际模型。随着试验次数的增加,替代模型(使用额外的试验结果更新)将得到改进,并开始推荐更好的候选超参数。
贝叶斯优化在为下一次试验推荐好的候选超参数之前,需要试验数据来建立代理模型,因此存在冷启动问题。代理模型在开始时没有历史试验可学习,因此候选超参数是随机选择的,这导致在寻找性能良好的超参数时开始较慢。
为了克服冷启动问题,开源AutoML库Auto-Sklearn通过一个称为元学习的过程将热启动整合到贝叶斯优化中,以获得比随机更好的超参数实例化。
Auto-Sklearn
AutoML是对机器学习管道中的数据预处理、特征预处理、超参数优化、模型选择和评估等任务进行自动化的过程。Auto-Sklearn使用流行的Scikit-Learn机器学习框架自动完成上述任务。下面的图片展示了自动学习的工作原理。

Auto-Sklearn使用贝叶斯优化和热启动(元学习)来找到最优的模型管道,并在最后从单个模型管道构建一个集成。让我们检查Auto-Sklearn框架中的不同组件。
元学习
元学习的目的是为贝叶斯优化找到好的超参数实例化,使其在开始时比随机的性能更好。元学习背后的理论很简单:具有相似元特征的数据集在同一组超参数上的表现也相似。由Auto-Sklearn作者定义的元特征是“可以有效计算的数据集特征,并帮助确定在新数据集上使用哪种算法”。
在离线训练过程中,我们将140个OpenML参考数据集的偏度、峰度、特征个数、类数等38个元特征列成表。对每个参考数据集进行贝叶斯优化训练,并对训练结果进行评价。存储为每个参考数据集提供最佳结果的超参数,这些超参数作为具有类似元特征的新数据集的贝叶斯优化器的实例化。
在对新数据集进行模型训练时,将新数据集的元特征制表,并根据元特征空间中到新数据集的L1距离对参考数据集进行排序。存储的前25个最接近的参考数据集的超参数用于实例化贝叶斯优化器。
作者在参考数据集上试验了不同的Auto-Sklearn变量,并使用不同训练时间的平均排名进行了比较。等级越低,性能越好。带有元学习的变体(蓝色和绿色)由于贝叶斯优化器良好的初始化,在开始时排名急剧下降。

数据预处理
Auto-Sklearn对数据的预处理顺序如下:[2]。
- 分类特征独热编码
- 使用平均数、中位数或模式的归因
- 归一化
- 使用类权重平衡数据集
特征预处理程序
在数据预处理之后,特征可以选择使用下列特征预处理器[2]中的一种或多种进行预处理。
- 利用主成分分析、SCV、核主成分分析或ICA进行矩阵分解
- 单变量特征选择
- 基于分类特征选择
- 特征聚类
- 核逼近(Kernel approximations)
- 多项式特征扩展
- 特征嵌入
- 稀疏表示与变换
模型集成
在训练过程中,Auto-Sklearn训练多个个体模型,这些个体模型可以用来构建集成模型。集成模型结合多个训练模型的加权输出来提供最终的预测。众所周知,它们不太容易过度拟合,总体表现优于单一模型。
从图1中,作者显示了使用集成的变体比不使用集成的变体性能更好(黑色vs红色,绿色vs蓝色)。带有元学习和集成的变体(绿色)表现最好。
代码实例
让我们来看一些Auto-Sklearn的实际例子。
安装包
pip install auto-sklearn==0.13
导入包
import pandas as pd
import sklearn.metrics
from sklearn.model_selection import train_test_split, StratifiedKFold
from autosklearn.classification import AutoSklearnClassifier
from autosklearn.metrics import (accuracy,
f1,
roc_auc,
precision,
average_precision,
recall,
log_loss)
加载数据集
我们将使用来自UCI的数据集,该数据集描述了银行为客户提供定期存款的营销活动。如果客户同意村换,目标变量是“是”;如果客户决定不存款,目标变量是“否”。
我们使用Pandas来读取。
df = pd.read_csv('bank-additional-full.csv', sep = ';')
准备数据
Auto-Sklearn要求列都是数字的,所以让我们现在转换它。
num_cols = ['ge', 'duration', 'campaign', 'pdays', 'previous', 'emp.var.rate', 'cons.price.idx', 'cons.conf.idx', 'euribor3m', 'nr.employed']
cat_cols = ['job', 'marital', 'education', 'default', 'housing', 'loan', 'contact', 'month', 'day_of_week', 'poutcome']
df[num_cols] = df[num_cols].apply(pd.to_numeric)
df[cat_cols] = df[cat_cols].apply(pd.Categorical)
y = df.pop('y')
X = df.copy()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state=1, stratify=y)
实例化分类器
skf = StratifiedKFold(n_splits=5)
clf = AutoSklearnClassifier(time_left_for_this_task=600,
max_models_on_disc=5,
memory_limit = 10240,
resampling_strategy=skf,
ensemble_size = 3,
metric = average_precision,
scoring_functions=[roc_auc, average_precision, accuracy, f1, precision, recall, log_loss])
下面是AutoSklearnClassifier中使用的一些参数。
time_left_for_this_task:限制总训练时间(秒)
max_models_on_disc:限制要保留的模型数量
memory_limit:希望使用的内存数量(以MB为单位)
Resampling_strategy:交叉验证重采样策略。
ensemble_size:要包含在ensemble中的模型数量。Auto-Sklearn提供了一个选项,在创建单个模型之后,通过采用加权方式获ensemble_size模型数量来创建集成模型。
metric:我们想要优化的度量指标
scoing_function:我们想要评估模型的一个或多个指标
训练
clf.fit(X = X_train, y = y_train)
在Auto-Sklearn在每次试验期间构建一个Scikit-Learn管道。Scikit-Learn管道用于组装一系列执行数据处理、特征处理和估计(分类器或回归器)的步骤。fit函数触发整个Auto-Sklearn构造、拟合和评估多个Scikit-Learn管道,直到满足停止条件time_left_for_this_task。
结果
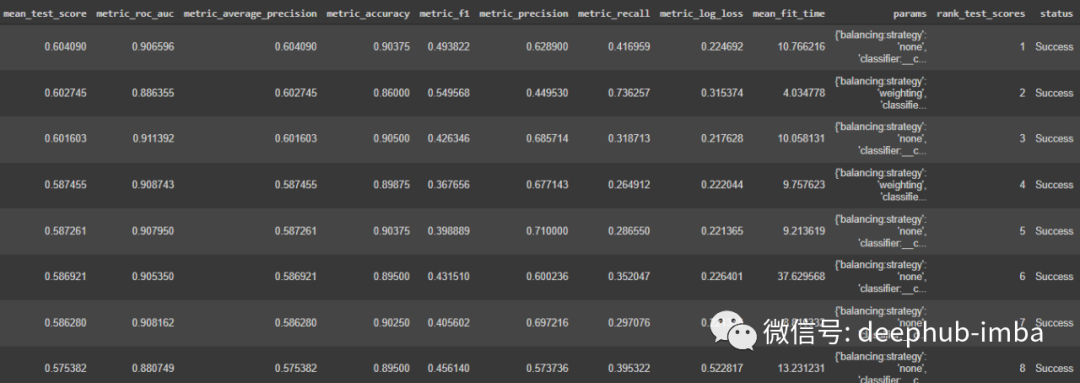
我们可以查看结果和选择的超参数。
df_cv_results = pd.DataFrame(clf.cv_results_).sort_values(by = 'mean_test_score', ascending = False)
df_cv_results
我们还可以在列表上查看所有结果的比较
clf.leaderboard(detailed = True, ensemble_only=False)
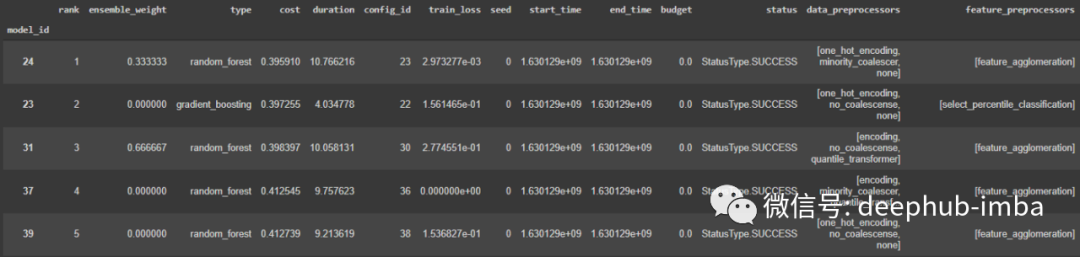
我们可以查看为使用的集成模型选择了哪些管道
clf.get_models_with_weights()
这个方法返回一个元组列表[(weight_1, model_1),…,(weight_n, model_n)]。权重表示它赋予每个模型的输出多少权重。所有权重值的总和为1。
我们还可以查看额外的训练统计数据。
clf.sprint_statistics()
用所有的训练数据进行重新训练
在k倍交叉验证期间,Auto-Sklearn对每个模型流水线进行k次拟合,仅用于评估,它不保留任何训练的模型。因此,我们需要调用修正方法来拟合在交叉验证过程中发现的所有训练数据的模型管道。
clf.refit(X = X_train, y = y_train)
保存模型
dump(clf, 'model.joblib')
读取模型及预测
让我们加载保存的模型管道以进行推断。
clf = load('model.joblib')
y_probas = clf.predict_proba(X_test)
pos_label = 'yes'
y_proba = y_probas[:, clf.classes_.tolist().index(pos_label)]
总结
寻找最优的模型管道组件和超参数是一项非常重要的任务。Auto-Sklearn可以帮助自动化这个过程。在本文中,我们研究了Auto-Sklearn如何使用元学习和贝叶斯优化来找到最优的模型管道并构建模型集成。Auto-Sklearn是众多AutoML包中的一个。还有很多的AutoML解决方案如H2O AutoML。
引用
[1] Efficient and Robust Automated Machine Learning
[2] Supplementary material for Efficient and Robust Automated Machine Learning
[3] Auto-Sklearn API documentation
作者:Edwin Tan
喜欢就关注我们把:
点个 在看 你最好看!********** **********