
使用Pytorch Geometric 进行链接预测代码示例
PyTorch Geometric (PyG)是构建图神经网络模型和实验各种图卷积的主要工具。在本文中我们将通过链接预测来对其进行介绍。
Stable-Baselines 3 部分源代码解读 3 ppo.py
阅读PPO相关的源码,了解一下标准库是如何建立PPO算法以及各种tricks的,以便于自己的复现。在Pycharm里面一直跳转,可以看到PPO类是最终继承于基类,也就是这个py文件的内容。所以阅读源码就先从这里开始。: )
【深度学习】GPT系列模型:语言理解能力的革新
大力出奇迹的语言模型!
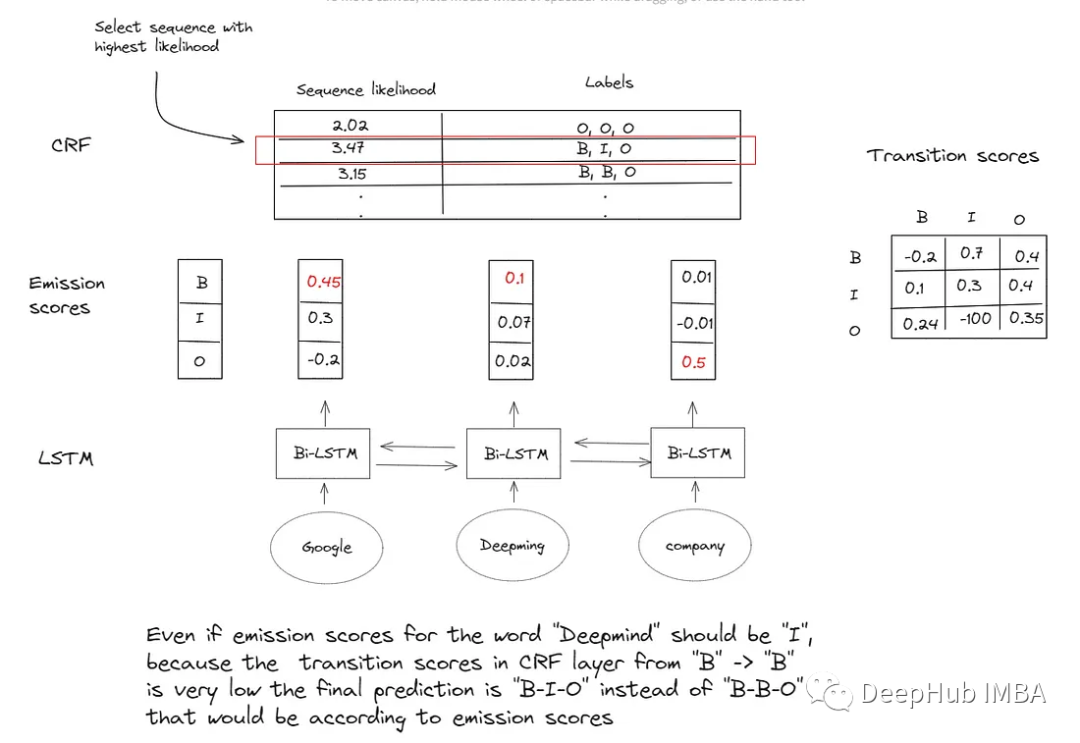
LSTM-CRF模型详解和Pytorch代码实现
本文中crf的实现并不是最有效的实现,也缺乏批处理功能,但是它相对容易阅读和理解,因为本文的目的是让我们了解crf的内部工作,所以它非常适合我们。
图像分割中常用数据集及处理思路(含代码)
一些分割常用的道路数据集,以及一个普遍适合的读入数据代码
【组会整理及心得】BiFormer、SICNet、IceNet
BRA、TSAM、海洋领域应用
【NLP相关】NLP领域经典论文汇总(附代码实现)
随着chat-gpt的爆火,越来越多的小伙伴们对NLP这个领域开始感兴趣。NLP设计多个领域,文本分类、文本摘要、机器翻译、信息抽取等等,本文对NLP领域的相关文献进行了梳理,筛选出一些必读文献和其他领域的基础文献,方便入门的小伙伴们学习。
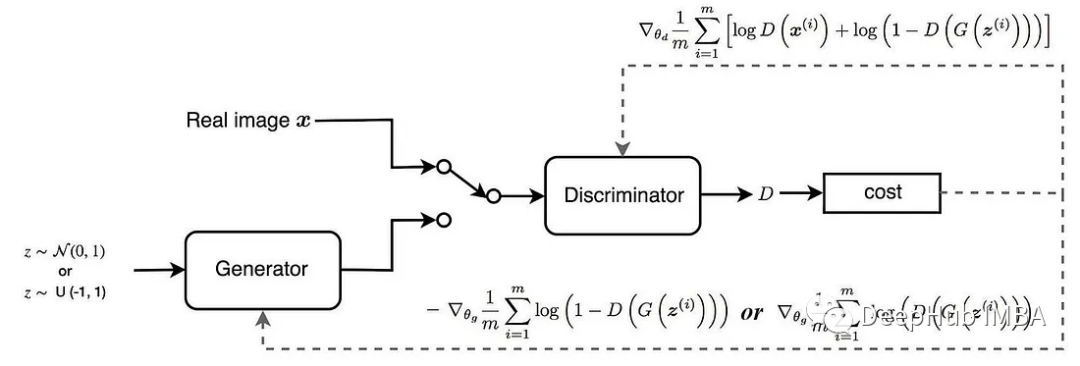
使用Pytorch实现频谱归一化生成对抗网络(SN-GAN)
自从扩散模型发布以来,GAN的关注度和论文是越来越少了,但是它们里面的一些思路还是值得我们了解和学习。所以本文我们来使用Pytorch 来实现SN-GAN
【人工智能】MAAS 模型即服务:概念、应用场景、优势、挑战等 —— 我们人类已经进入人工智能大模型时代
MAAS即模型即服务,是一种通过网络提供人工智能模型的服务,用户可以通过API或其他接口访问和使用这些模型。MAAS的基本原理是将模型部署在云端服务器上,用户可以通过网络连接到这些服务器,使用云端的计算资源和存储空间,以及高效的模型部署和管理机制,从而实现模型的快速部署和使用。MAAS的出现,主要是
隐函数的求导
有隐函数就有显函数,我们首先要了解显函数的定义:隐函数:例如:对于有些隐函数,我们可以显化:但是有些隐函数,我们并不能显示化这个隐函数,我们就不能显示化对于这个函数,我们发现以下特征:当x趋近于正无穷时,y也趋近于正无穷。当x趋近于负无穷时,y也趋近于负无穷。假设我们把这里的x当作1,然后再对y进行
AI「鸟口普查」,康奈尔大学利用深度学习分析北美林莺分布
据世界自然基金会统计,过去 40 年间,全球代表物种种群数量减少了 68%,全球生物多样性面临威胁。要制定合理的生态保护政策,需要对当地的生态数据进行准确的大规模统计。然而,由于生态数据量庞大,不同地区统计标准存在偏差,大规模的生态统计很难进行,得到的数据也很难为生态政策提供参考。深度学习为大规模的
深度学习技巧应用2-神经网络中的‘残差连接’
残差连接通过直接将前一层的输出加到后一层的输入中,使得梯度能够更容易地传递到前一层,从而使得深度神经网络的训练更加容易。由于深层网络容易出现梯度消失或梯度爆炸的问题,因此可以通过残差连接的方式,将网络的深度扩展到数十层以上,从而提高模型的性能。残差连接的基本思想是,在网络的某些层中,将输入的信号直接
深度学习篇之tensorflow(2) ---图像识别
tensorflow处理图像识别图像识别图像识别的关键点及特点卷积神经网络原理视觉生物学研究神经网络优势卷积层池化层正则化层卷积神经网络实例样本数据读取urlretrieve()方法python tarfile模块构建卷积神经网络模型构建卷积层构建池化层完整代码实战完成代码
常见注意力机制解析
详细解析多种注意力机制!
33- PyTorch实现分类和线性回归 (PyTorch系列) (深度学习)
线性回归预测的是一个连续值, 逻辑回归给出的”是”和“否”的回答, 逻辑回归通过sigmoid函数把线性回归的结果规范到0到1之间.sigmoid函数是一个概率分布函数, 给定某个输入,它将输出为一个概率值.# 回归和分类之间, 区别不大, 回归后面加上一层sigmoid, 就变成分类了.(py
编码器-解码器架构
编码器-解码器架构学习,并举例。
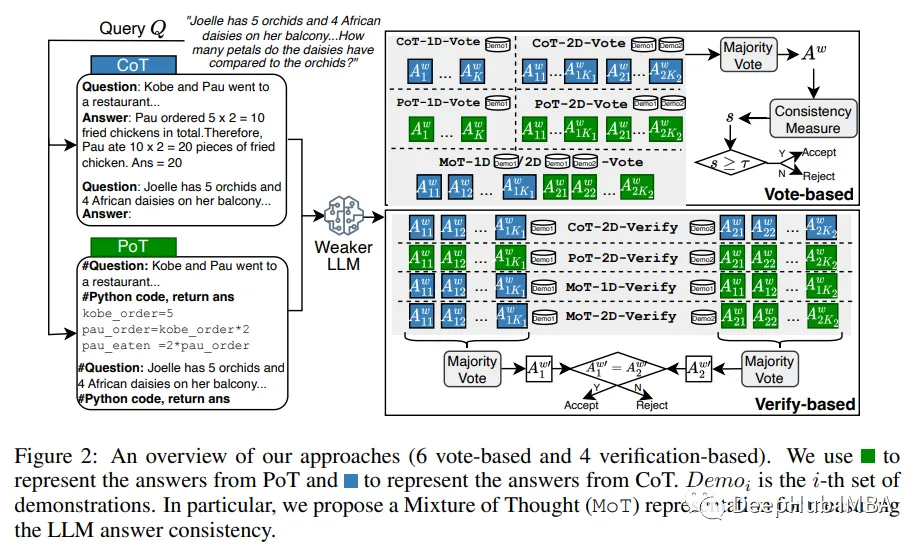
9月大型语言模型研究论文总结
这些论文涵盖了一系列语言模型的主题,从模型优化和缩放到推理、基准测试和增强性能。最后部分讨论了有关安全训练并确保其行为保持有益的论文。
torchvision.models简介
torchvision.models简介
计算机专业研究方向相关论文查找方法,分享给大家,实测有用。
论文文献查找的方法合集
Conda 创建和删除虚拟环境
我们在学习深度学习时,往往会由于不同代码需要配置不同的环境,这就需要Conda来进行创建虚拟环境。



