
【CVPR2023】BiFormer: Vision Transformer with Bi-Level Routing Attention
BiFormer:Vision Transformer with Bi-Level Routing Attention - 知乎
【本文贡献】
- 通过双层路由(bi-level routing)提出了一种新颖的动态稀疏注意力(dynamic sparse attention),以实现更灵活的计算分配和内容感知,使其具备动态的、query感知的稀疏性
- 使用两级路由注意力作为基本构建块,提出了一个新的视觉Transformer,名为BiFormer,视觉领域的多个实验表明该模型具有更好的性能。
【网络结构】
先是提出了Bi-Level Routing Attention (BRA),先将特征图划分为S×S个非重叠区域,得到QKV,再求Q和K的均值来得到对应的Qr和Kr,再使用转置乘法得到区域间的亲和度的邻接矩阵Ar,使用topK算子保留关系最密切的前k个区域,得到区域路由索引矩阵Ir。

得到Ir后即可应用细粒度的Token-to-token attention,如下图所示,先汇集以Ir中的所有元素为索引的路由区域,并收集它们的所有K和V得到Kg和Vg,再将Kg和Vg应用于注意力。
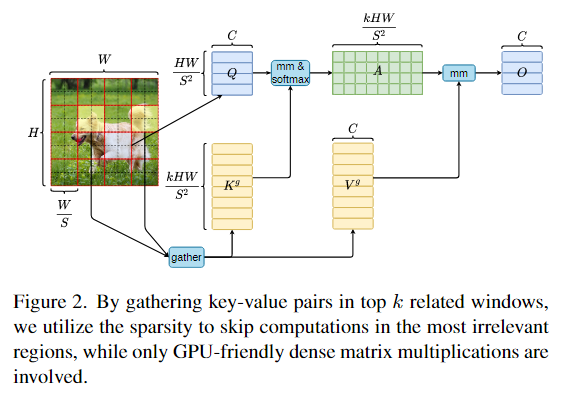
最后,有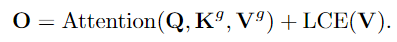
这里的LCE是一个局部上下文增强项(相关论文《Shunted Self-Attention via Multi-Scale Token Aggregation》)。
使用 BRA 作为基本构建块,本文提出了BiFormer,如下图所示,大致结构为四阶段金字塔结构。
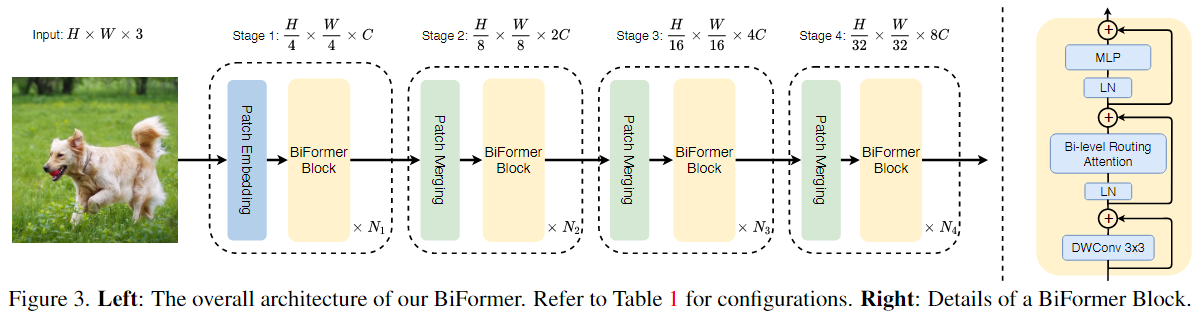
【心得体会】
采用动态稀疏注意力和topK方式有利于减少运算量,但也有使得准确率变低的风险,或许要注意一下K值的选取。
【TGRS2022】A data-driven deep learning model for weekly sea ice concentration prediction of the Pan-Arctic during the melting season
- SICNet [Yibin Ren, Xiaofeng LI, Wenhao Zhang] - 知乎
【本文贡献】
提出了一个用于海冰预测的模型SICNet,它比现有的模型更轻量,并且性能好,显示了出比异常持久性 (Persist) 更好的递归预测性能。
【网络结构】
总体上是一个U-Net结构,主要创新点是提出了TSAM,它是将CBAM的MLP部分替换为本文提出的TCN模块形成的,相当于给特征图添加了权重信息。
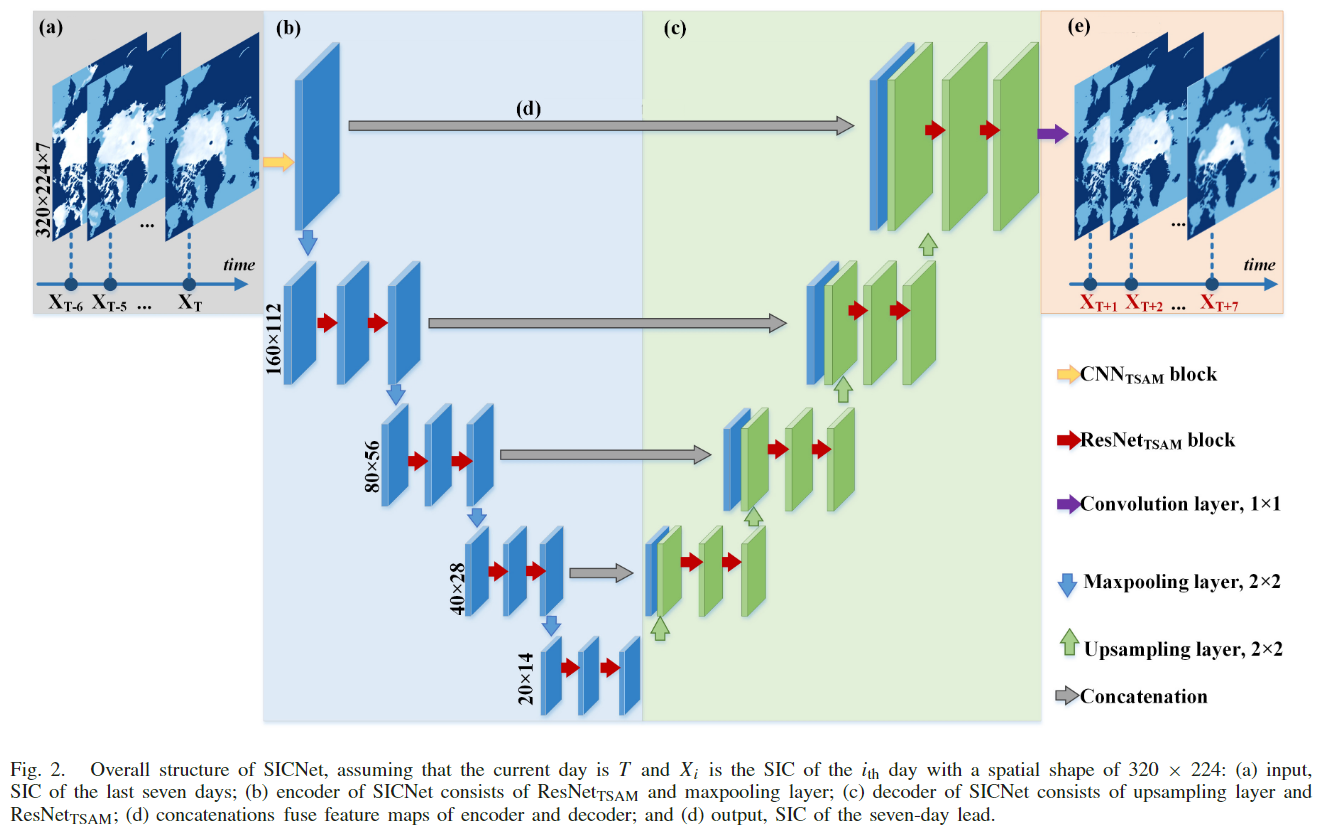
TSAM相关模块的结构以及与CBAM的对比:
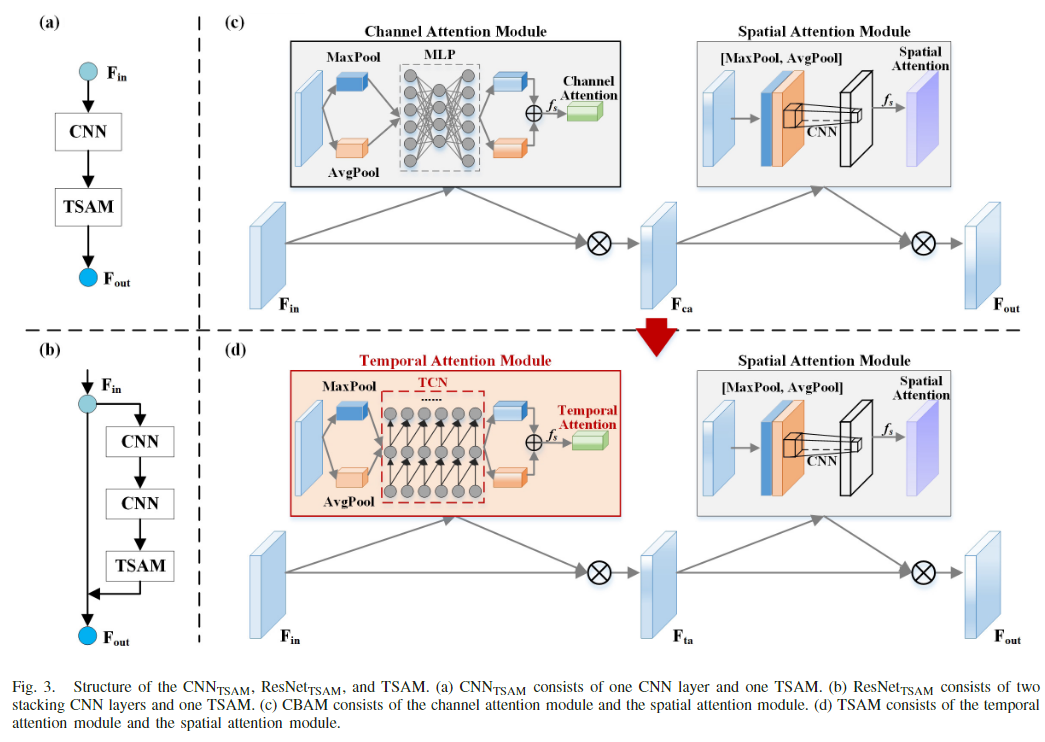
本文认为直接将 CBAM 搬到本文SIC长序列中不太合适, 因为计算机视觉中通常用不同 channel 表示不同类, MLP是用于提取类之间的全局关联性的, 而在 SIC 的长序列中, 更需要得到的是通道序列之间的顺序依赖关系, 即时空关系。由于SIC 任务高度依赖历史的 SIC 序列,并且需要考虑时序,本文把MLP替换为TCN 结构,如下图所示:
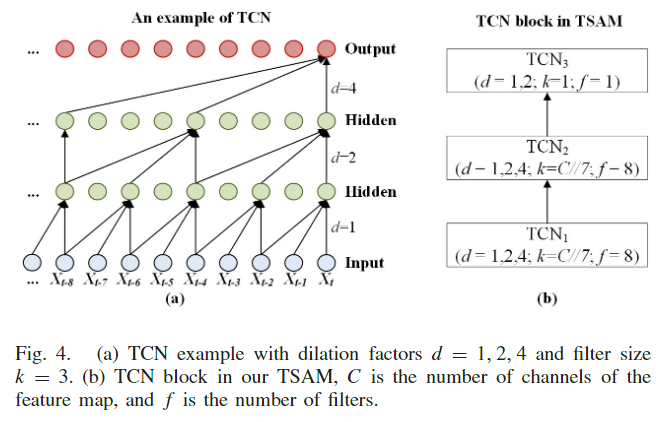
【心得体会】
这里的TCN相当于将MLP改成了稀疏的,和CBAM相比,TSAM计算量应该更小,在特定任务中可以尝试用TSAM替代原本的CBAM。
【Nature Communications】Seasonal Arctic sea ice forecasting with probabilistic deep learning
【本文贡献】
提出了一个基于概率和深度学习的海洋冰预测系统 IceNet。
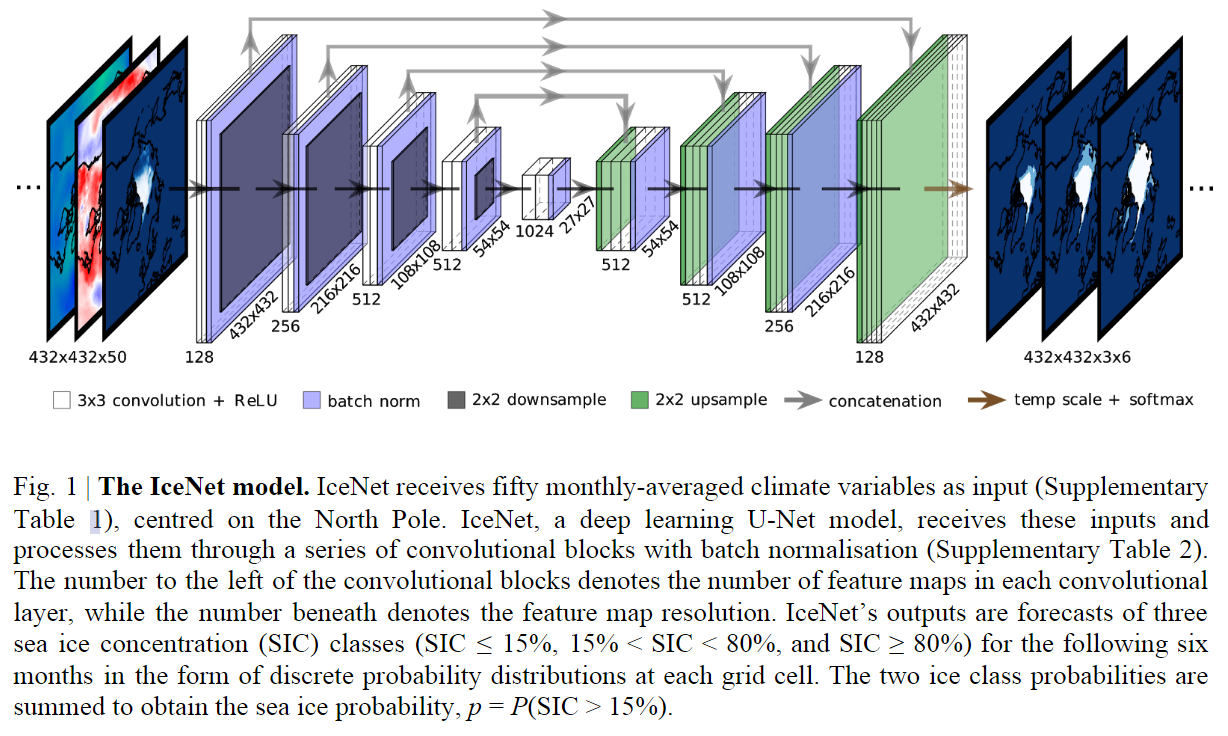
【网络结构】
总体上是一个U-Net结构:
相关训练方案和参数:
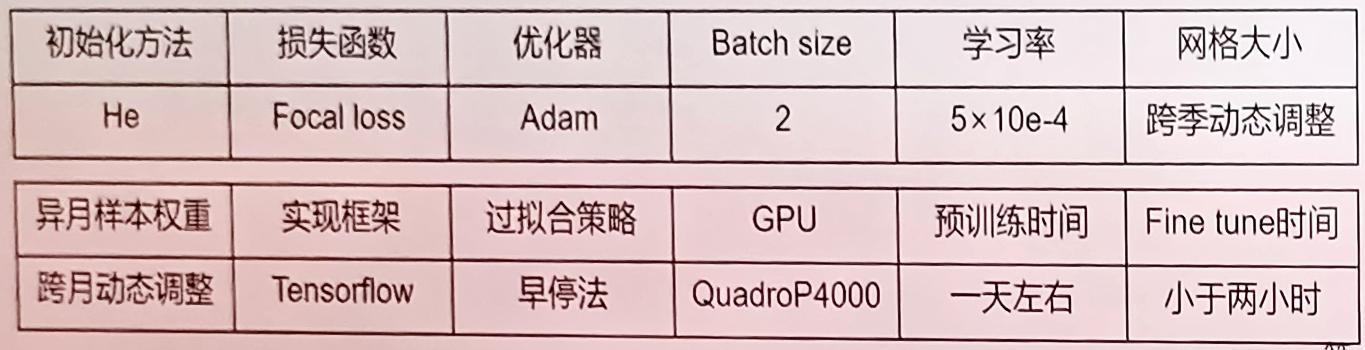
【心得体会】
本文是一个将深度学习模型用于海洋领域的一个应用。
版权归原作者 深蓝与夜的呼吸 所有, 如有侵权,请联系我们删除。