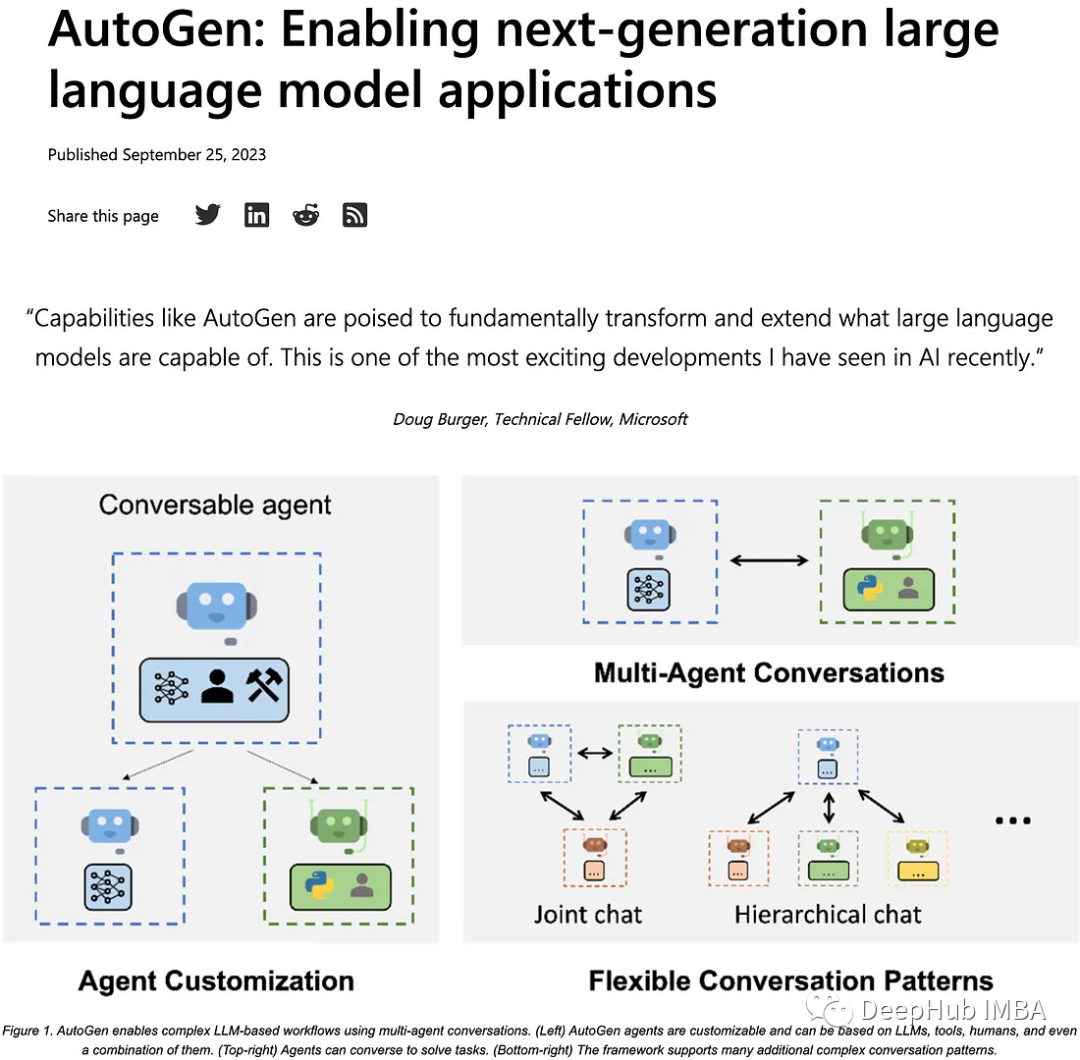
AutoGen完整教程和加载本地LLM示例
Autogen是一个卓越的人工智能系统,它可以创建多个人工智能代理,这些代理能够协作完成任务,包括自动生成代码,并有效地执行任务。
【深度学习】使用ffmpg及gstreamer进行视频拉流及编解码(一):ffmpg
GStreamer:一款功能强大的多媒体框架,可以用于音视频的采集、编码、解码、处理和传输。FFmpeg:一个开源的音视频处理工具,可以用于音视频的采集、编码、解码、转码、处理等。FFmpeg和GStreamer都是流媒体处理框架,它们在音视频编解码、转码、过滤、采集等方面都有广泛的应用。FFmpe
如何在kaggle上保存、加载文件,同时在output上删除已经保存的文件。
在kaggle的notebook下操作output,用torch对文件进行操作
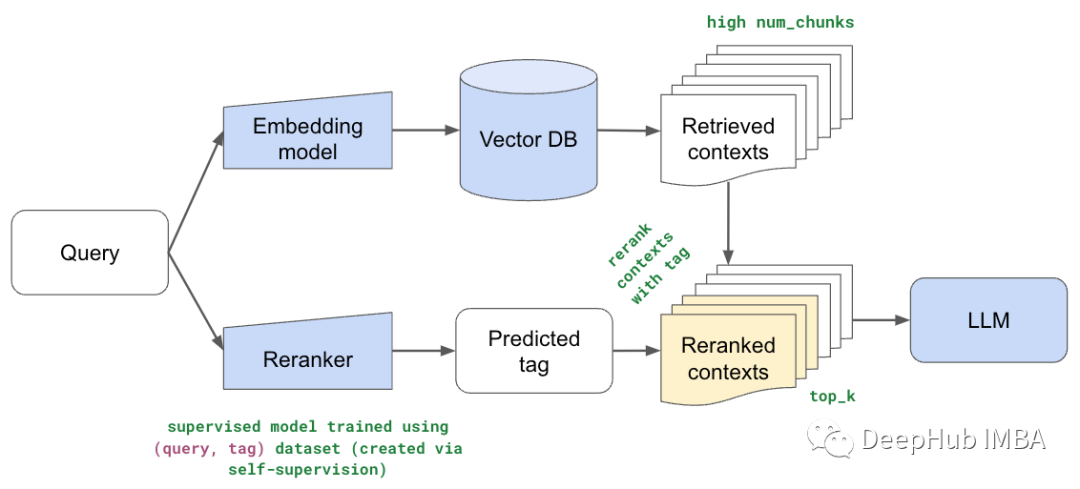
使用Llama index构建多代理 RAG
检索增强生成(RAG)已成为增强大型语言模型(LLM)能力的一种强大技术。通过从知识来源中检索相关信息并将其纳入提示,RAG为LLM提供了有用的上下文,以产生基于事实的输出。
最简单Anaconda+PyTorch深度学习环境配置教程
Anaconda,中文大蟒蛇,是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。安装它可以方便我们后续进行conda环境管理器下的命令生成和跑各自深度学习模型。CUDA(Compute Unified Device Architecture),是显卡厂商
卷积神经网络CNN的经典模型
主要介绍卷积神经网络CNN的发展史,并详细剖析了经典网络模型的架构。
【人工智能】大模型的发展历史
2012年以后的深度学习热潮:2012年,AlexNet横空出世,以卷积神经网络(CNN)为代表的深度学习模型在计算机视觉任务中取得了巨大突破,吸引了越来越多的计算机科学家和工程师投入深度学习研究和应用。:2018年,Google推出了基于Transformer的预训练模型BERT,通过大量无标签文
【深度学习】自监督学习详解(self-supervised learning)
详解!自监督学习:对比学习和生成学习。
使用Panda-Gym的机器臂模拟进行Deep Q-learning强化学习
强化学习(RL)是一种机器学习方法,它允许代理通过试错来学习如何在环境中表现。行为主体因采取行动导致预期结果而获得奖励,因采取行动导致预期结果而受到惩罚。随着时间的推移,代理学会采取行动,使其预期回报最大化。
CTC-Loss
CTC-Loss
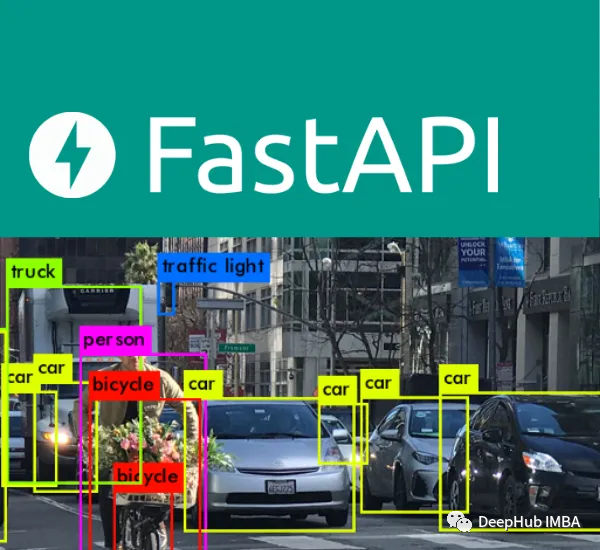
使用FastAPI部署Ultralytics YOLOv5模型
在本文中,我们将介绍如何使用FastAPI的集成YOLOv5,这样我们可以将YOLOv5做为API对外提供服务。
基于ChatGPT实现AI软件研发 | 神经网络 | 数据
这是一本讲解以ChatGPT/GPT-4为代表的大模型如何为软件研发全生命周期赋能的实战性著作。它以软件研发全生命周期为主线,详细讲解了ChatGPT/GPT-4在软件产品的需求分析、架构设计、技术栈选择、高层设计、数据库设计、UI/UX 设计、后端应用开发、Web 前端开发、软件测试、系统运维、技
深度学习中训练时经常碰到的train、val、test有啥区别?
train是训练集,val是训练过程中的测试集,是为了让你在边训练边看到训练的结果,及时判断学习状态。test就是训练模型结束后,用于评价模型结果的测试集。只有train就可以训练,val不是必须的,比例也可以设置很小。test对于model训练也不是必须的,但是一般都要预留一些用来检测,通常推荐比
基于深度学习的图像分割
摘要遥感图像分割是利用遥感技术获取的高分辨率图像进行像素级别的分类,将图像中的不同物体或不同地物提取出来的过程。这个过程对于遥感应用具有重要意义,因为它能够提取出地物和地表特征,如河流、道路、建筑、植被、水体等,并且这些特征是地面实际存在的。图像分割可以为地面覆盖分类、土地利用覆盖变化分析、城市规划
【1】深度学习之Pytorch——张量(tensor)的尺寸、储存偏移及步长等基本概念
这和我们python里面的numpy差不多的,多维数组如何索引,以及相关的概念,如果拥有线性代数的基础,你可以知道什么叫做矩阵,以及这一系列的相关操作,就可以理解这些概念。最开始的张量我们可以看到它是一个,一个数组里面包含2个数组,而这个单独的2个数组里面又包含3个蛋到户的数,那么现在互换维度就是,
图像风格迁移基础入门及实践案例总结
目录1图像的不同风格2何为图像风格迁移2.1基础概念及方法2.2示例3图像风格迁移的典型研究成果3.1deep-photo-styletransfer3.2CycleGAN3.3U-GAT-IT4风格迁移演进趋势5.使用训练好的模型来生成图像5.1环境5.2模型下载5.3使用训练好的模型6.训练一个
注意力机制详解
将attentionj机制全部都将其研究透彻,好好研究一下。
强化学习PPO从理论到代码详解(1)--- 策略梯度Policy gradient
笔者在强化学习的道路上看来很多书,看了很多代码,和很多大佬的博客,只是很多都是侧重一个方面,所以我在吸取百家之长后,决定完完整整的写一回PPO从算法理论到逐行代码手敲和详解的文章。
Pytorch使用Grad-CAM绘制热力图
使用grad_cam对不同预测目标的图像做activate图。需要模型feature的最后一层,模型训练权重。使用的是自己训练的MobileNetV2。原理与代码学习自B站。
Swin-Transformer 详解
用动画深入解释Swin-Transformer



