安装anaconda3,并搭建一个python3.10开发环境【AI深度学习环境搭建】
完成上面操作之后你的目录 C:\Users\<你的电脑名字> 下就会生成配置文件.condarc,我的电脑中的这个文件位置是:C:\Users\Administrator\.condarc 然后用记事本把这个文件打开,手动删除-defaults,并把https换成http即可。conda activ
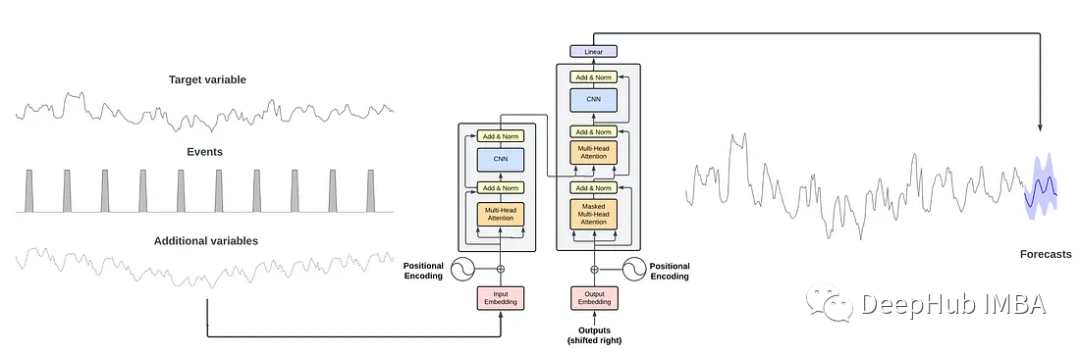
TimeGPT:时间序列预测的第一个基础模型
在本文中,我们将探索TimeGPT背后的体系结构以及如何训练模型。然后,我们将其应用于预测项目中,以评估其与其他最先进的方法(如N-BEATS, N-HiTS和PatchTST)的性能。
【深度学习】上采样,下采样,卷积
下采样的过程是一个信息损失的过程,而池化层是不可学习的,用stride为2的可学习卷积层来代替pooling可以得到更好的效果,当然同时也增加了一定的计算量。来讲,上采样和下采样的结构往往是对称的,我们可以在下采样做Max Pooling的时候记录下来最大值所在的位置,当做上采样的时候把最大值还原到
神经网络的发展历史
论文中提出了人工神经网络的概念,并给出了人工神经元的数学模型,从而开创了人工神经网络研究的时代。

Table-GPT:让大语言模型理解表格数据
在这篇文章中,我们将介绍微软发表的一篇研究论文,“Table-GPT: Table- tuning GPT for Diverse Table Tasks”,研究人员介绍了Table-GPT
深度学习面试问题与答案(2023)
深度学习热门面试题。
人工智能基础部分11-图像识别实战(网络层联想记忆,代码解读)
大家好,我叫微学AI,今天给大家带来图像识别实战项目。图像识别实战是一个实际应用项目,下面介绍如何使用深度学习技术来识别和检测图像中的物体。主要涉及计算机视觉,实时图像处理和相关的深度学习算法。学习者将学习如何训练和使用深度学习模型来识别和检测图像中的物体,以及如何使用实时图像处理技术来处理图像。项
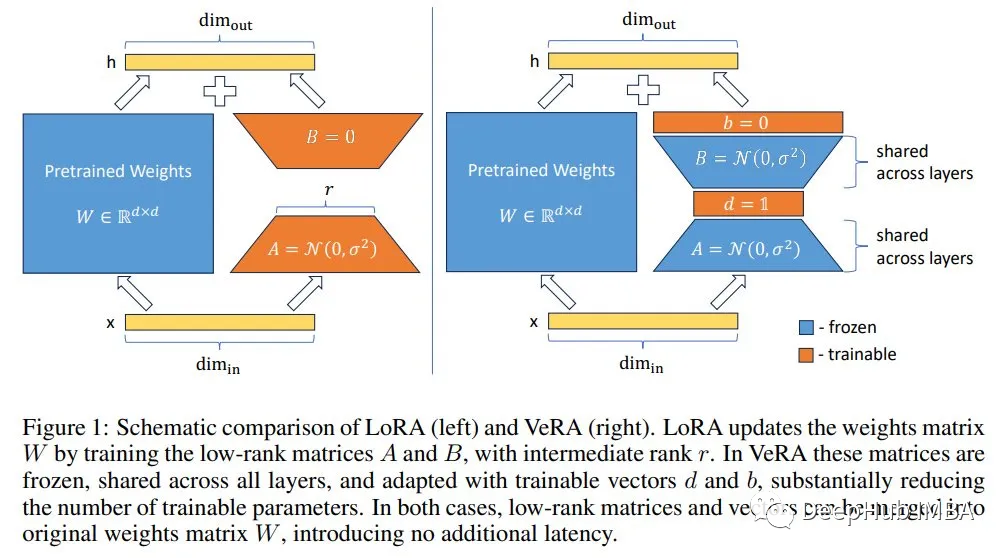
VeRA: 性能相当,但参数却比LoRA少10倍
VeRA在LoRA冻结的低秩张量上添加可训练向量,只训练添加的向量。论文中显示的大多数实验中,VeRA训练的参数比原始LoRA少10倍。
Multimodal Sentiment Analysis论文汇总
多模态情绪分析论文汇总
LlamaIndex使用指南
LlamaIndex是一个方便的工具,它充当自定义数据和大型语言模型(llm)(如GPT-4)之间的桥梁,大型语言模型模型功能强大,能够理解类似人类的文本
tensorflow安装步骤(CPU版本,Anaconda环境下,Windows10)
本文主要讲述了在Anaconda环境下,CPU版本tensorflow2.3.0的安装步骤,Windows10系统中Anaconda的安装步骤可以阅读此篇博客:用Anaconda安装TensorFlow(Windows10)本文分为两大部分:一、TensorFlow2.3.0安装步骤二、对Tenso
手部数据太难找?最全手部开源数据集分享
本期将给大家介绍22个与手部检测、手势识别、手部图像分割等任务相关的公开数据集,包含第一人称、第三人称视角,可用于人机交互、手语翻译、3D建模等场景。
VideoPose3D:基于视频的3D人体关键点检测
VideoPose3D,一个基于视频的3D人体关键点检测模型
MedNeRF:用于从单个X射线重建3D感知CT投影的医学神经辐射场
计算机断层扫描(CT)是一种有效的医学成像方式,广泛应用于临床医学领域,用于各种病理的诊断。多探测器CT成像技术的进步实现了额外的功能,包括生成薄层多平面横截面身体成像和3D重建。然而,这涉及患者暴露于相当剂量的电离辐射。过量的电离辐射会对身体产生决定性的有害影响。本文提出了一种深度学习模型,该模
人工智能ChatGPT如何下载?
ChatGPT 是一个基于人工智能技术的自然语言处理模型,其可以通过学习大量的文本数据,自主生成符合语法、通顺、流畅的文本。ChatGPT 可以被广泛应用于智能客服、聊天机器人、自动摘要、机器翻译等领域,可以大幅提高人们的生产效率,使人与计算机之间的交互更加无缝,这使得 ChatGPT 的应用面非常
Adding Conditional Control to Text-to-Image Diffusion Models
代码 URL:https://github.com/lllyasviel/ControlNet。
人工智能专业毕业设计最新最全选题精华汇总-持续更新中
本文为人工智能专业学生提供了最新、最全的毕业设计选题推荐。人工智能作为当今科技领域的热门专业之一,其毕业设计选题的选择对学生的学术发展和职业前景至关重要。我们精心汇总了各个子领域的选题,包括机器学习、深度学习、自然语言处理、计算机视觉等,以满足学生们对不同研究方向的需求。这些选题既包括了理论研究和算
Pyinstaller打包报错小结
1.Pyinstaller打包exe文件,执行后提示缺失yaml,csv,dll等资源文件。2.打包后运行提示 WARNING: file already exists but should not: C:\Users\ADMINI~1\AppData\Local\Temp_MEI130922\to
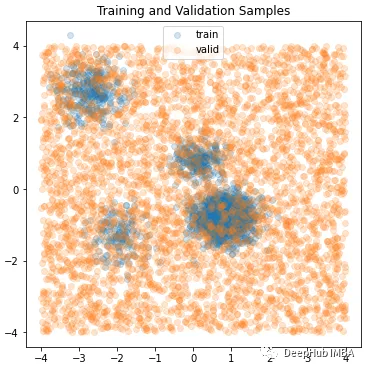
使用pytorch实现高斯混合模型分类器
本文是一个利用Pytorch构建高斯混合模型分类器的尝试。我们将从头开始构建高斯混合模型(GMM)。这样可以对高斯混合模型有一个最基本的理解,本文不会涉及数学,因为我们在以前的文章中进行过很详细的介绍。
深度学习:GPT1、GPT2、GPT-3
保存之前阶段训练的参数,在上述结构的基础上,去掉softmax层,然后加上一层全连接层与特定任务的softmax,然后用有标签的数据集训练,在这期间,半监督学习的参数可以选择处于冻结状态,然后只更新新的全连接层参数。GPT-1主要针对的是生成型NLP任务,如文本生成、机器翻译、对话系统等。GPT-2



