【人工智能】大模型技术生态
大模型技术是指基于深度学习等机器学习技术,利用大规模数据进行训练得到的巨型神经网络模型。它可以在自然语言处理、视觉识别、语音识别等领域中实现更加准确、智能化的任务,具有非常强的应用前景。从模型大小来看,常见的大模型包括BERT、GPT-3、Turing NLG等,其中包含数十亿或数百亿参数,需要庞大
条件DDPM:Diffusion model的第三个巅峰之作
条件DDPM:Diffusion model的第三个巅峰之作
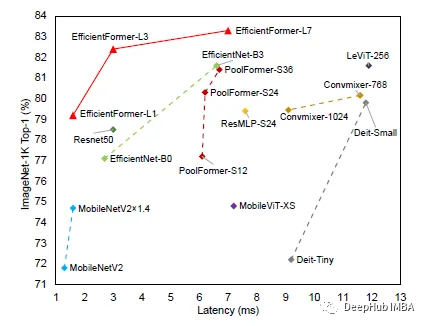
EfficientFormer:高效低延迟的Vision Transformers
我们都知道Transformers相对于CNN的架构效率并不高,这导致在一些边缘设备进行推理时延迟会很高,所以这次介绍的论文EfficientFormer号称在准确率不降低的同时可以达到MobileNet的推理速度。
No module named 'torch'怎么办
如果在使用 Python 程序时出现 "No module named 'torch'" 错误,说明你的环境中没有安装 PyTorch 库。可以使用以下命令来安装 PyTorch:pipinstall torch如果你正在使用 Anaconda 环境,则可以使用以下命令来安装 PyTorch:con
YOLO数据集实现数据增强的方法(裁剪、平移 、旋转、改变亮度、加噪声等)
数据集样本太少怎么办?数据集优质图像不够怎么办?如何做到更好的数据预处理?一文带你学会数据增强,还可实现带标签的扩充。
常用的19道人工智能面试题,作为人工智能工程师,你知道多少?
答案:人工智能(Artificial Intelligence,简称AI)是一种模拟人类智能的技术和科学。它涉及到各种领域,包括机器学习、自然语言处理、计算机视觉、语音识别、决策树等。人工智能的目标是让计算机具备类似于人类的智能,能够自主地思考、学习、推理和决策。人工智能的应用范围非常广泛,包括智能
【人工智能】LLM 大型语言模型发展历史
大型语言模型(Large Language Models,LLM)是指基于神经网络模型的自然语言处理技术,它可以通过大规模的训练数据和计算资源来预测自然语言文本的下一个词或句子。近年来,由于技术的不断进步和计算资源的不断增加,LLM已成为自然语言处理领域的一个热门技术。本文将从LLM的发展历史、技术
【人工智能】基础模型(Foundation Models)的机遇与风险
近几年,预训练模型受到了学术界及工业界的广泛关注,对预训练语言模型的大量研究和应用也推动了自然语言处理新范式的产生和发展,进而影响到整个人工智能的研究和应用。近期,由斯坦福大学众多学者联合撰写的文章《On the Opportunities and Risks of Foundation Model
【人工智能】Softmax 函数基础介绍、应用场景、优缺点、代码实现
在机器学习中,softmax函数是一种用于多项式分类问题的激活函数,它将一个K维向量转换为K个范围在[0,1]之间且总和为1的概率分布。它通常被用于将最后一层的输出映射到一个概率分布上,从而使得分类器可以预测每一类的概率。Softmax函数是一个非常有用的激活函数,它可以将实数向量转换为概率分布,并
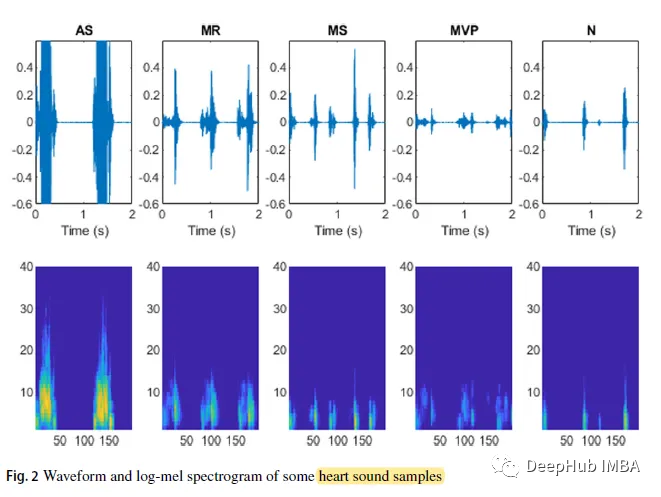
基于对数谱图的深度学习心音分类
这是一篇很有意思的论文,他基于心音信号的对数谱图,提出了两种心率音分类模型,我们都知道:频谱图在语音识别上是广泛应用的,这篇论文将心音信号作为语音信号处理,并且得到了很好的效果。
深度学习 yolov5等结构图
yolov5 卷积神经网络 等结构图
BiFPN 论文重点研读:高效双向跨尺度连接和加权特征融合
本文重点在于说明设计了BiFPN特征网络结构,如果能多使用几次BiFPN的话,会使实验效果更好。
【人工智能】大模型之编码器基础知识
序列数据输入:编码器接收输入序列数据,并将其存储在内存中。自注意力机制:编码器使用自注意力机制来提取序列中的信息,以使模型能够更好地理解序列中的不同部分。编码器输出:编码器通过将输入序列和其对应的输出向量相减来实现对序列数据的预测。编码器是神经网络中的一个重要组件,它的主要作用是将输入序列数据编码成
【目标检测】Grounding DINO:开集目标检测器(CVPR2023)
Grounding DINO,一种开集目标检测方案,将基于Transformer的检测器DINO与真值预训练相结合。开集检测关键是引入自然语言至闭集检测器,用于open world的检测。Grounding DINO将检测器分为三个阶段的紧密融合方案,包括。可实现对新颖类别进行检测,特定属性目标识别
【AI人工智能】如何使用Keras和TensorFlow来训练大型深度学习模型
Keras和TensorFlow都使用了动态图(Dynamic Graph)作为模型的表示。动态图允许模型在运行时进行修改,并且可以在编译时进行优化。Keras和TensorFlow都使用了神经网络模型的压缩和优化技术。例如,Keras的Transformer模型采用了一些针对压缩和优化的技术,例如
从传统的图像压缩到基于深度学习的图像压缩
早期的图像压缩方法直接利用熵编码减少图像的编码冗余来实现压缩,例如,霍夫曼(Huffman)编码,算术编码,上下文自适应二进制算术编码。在20世纪 60年代后期基于图像变换的压缩方法被提出,这种压缩方法即将图像从空间域转换至频率域在频率域进行编码。变换编码中用到的变换方法主要包括傅里叶变换,Hada
【代码复现】Windows10复现nerf-pytorch
本文主要介绍了nerf-pytorch在win10下复现的方法。
【人工智能】大模型(LLM)与人类大脑的结构及运行机制的关系
随着计算机科学的发展,我们渐渐地拥有了能力让人工智能系统处理更复杂的任务。在过去几十年中,人工智能的上限一直在不断提高。特别是,在计算机处理自然语言这个领域,人工智能已经取得了显著的成果。这方面的许多研究都关注于理解和模仿人类大脑的结构和机制,以提高人工智能的性能。LLM作为当今一种重要的人工智能表
【基础篇001】⼤模型理论基础——初探大模型:起源与发展《AI 大模型应用开发实战指南》
实战五:基于知识库的销售顾问 Sales-Consultant。实战三:使用 LangChain 重新实现智能翻译助手。实战二:动⼿开发第⼀个 ChatGPT Plugin。在 ChatGPT 聊天中实现 PDF ⽂件上传。实战一:基于 ChatGPT 开发智能翻译助⼿。实战四:手把手带你实现网红项
【人工智能的数学基础】多目标优化的帕累托最优(Pareto Optimality)
寻找多目标优化问题的帕累托最优解.多目标优化是指同时优化多个相关任务的目标,Ltotali∑nwiLi。为使得每个任务在训练时都获得有益的提升,需要合理的设置任务权重wi,使得每一次更新时目标损失函数L1L2⋯Ln都下降或保持不变。对于参数θ∗,若该参数任意变化都会导致某个目标的损失



