深度学习|BP神经网络
讲述BP神经网络原理,并通过Python语言,分别导入numpy、sklearn和pytorch库完成编程。
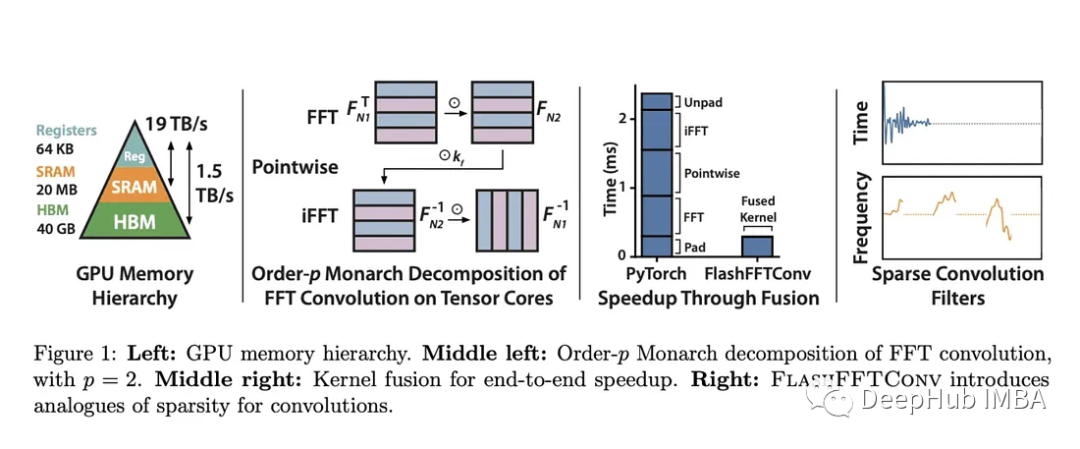
斯坦福大学引入FlashFFTConv来优化机器学习中长序列的FFT卷积
斯坦福大学的FlashFFTConv优化了扩展序列的快速傅里叶变换(FFT)卷积。该方法引入Monarch分解,在FLOP和I/O成本之间取得平衡,提高模型质量和效率。
人工智能中的文本分类:技术突破与实战指导
在本文中,我们全面探讨了文本分类技术的发展历程、基本原理、关键技术、深度学习的应用,以及从RNN到Transformer的技术演进。文章详细介绍了各种模型的原理和实战应用,旨在提供对文本分类技术深入理解的全面视角。
经典神经网络论文超详细解读(五)——ResNet(残差网络)学习笔记(翻译+精读+代码复现)
RseNet论文(《Deep Residual Learning for Image Recognition》)超详细解读。翻译+总结。文末有代码复现

使用ExLlamaV2量化并运行EXL2模型
量化大型语言模型(llm)是减少这些模型大小和加快推理速度的最流行的方法。在这些技术中,GPTQ在gpu上提供了惊人的性能。与非量化模型相比,该方法使用的VRAM几乎减少了3倍,同时提供了相似的精度水平和更快的生成速度。
听懂未来:AI语音识别技术的进步与实战
本文全面探索了语音识别技术,从其历史起源、关键技术发展到广泛的实际应用案例,揭示了这一领域的快速进步和深远影响。文章深入分析了语音识别在日常生活及各行业中的变革作用,展望了其未来发展趋势。
【计算机视觉】ViT:代码逐行解读
【计算机视觉】ViT:代码逐行解读
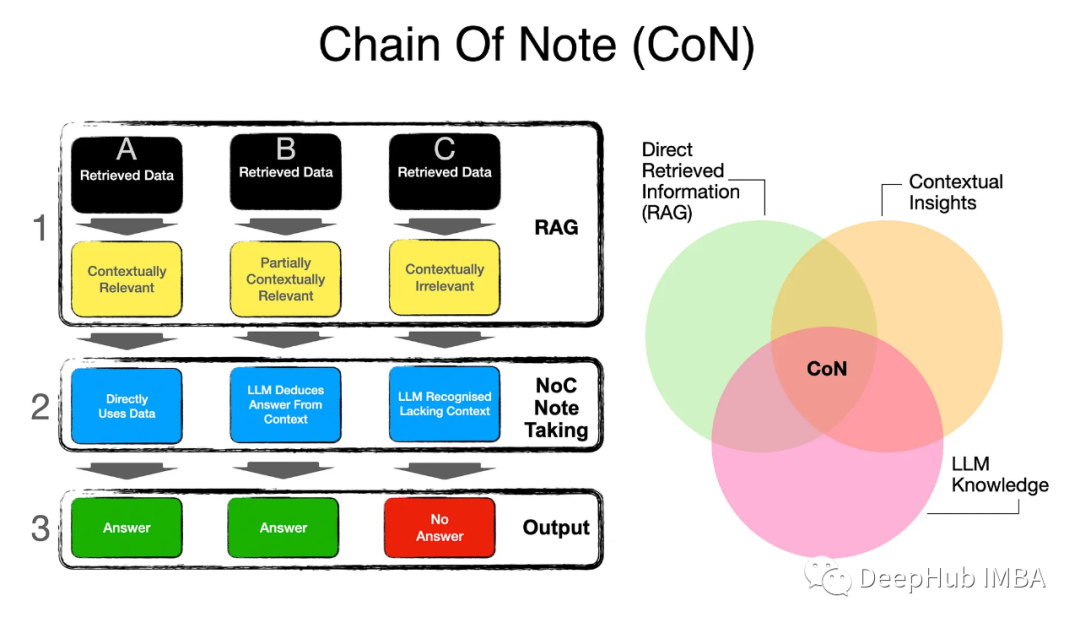
Chain-Of-Note:解决噪声数据、不相关文档和域外场景来改进RAG的表现
这是腾讯实验室在11月最新发布的一篇论文,CoN的核心思想是生成连续的阅读笔记对于检索到的文档,能够对其与给出问题并综合这些信息来形成最终的答案,提高了RAG的表现。
使用冻结层进行迁移学习
使用冻结层进行迁移学习
Swin-transformer详解
这篇论文提出了一个新的 Vision Transformer 叫做 Swin Transformer,它可以被用来作为一个计算机视觉领域一个通用的骨干网络.但是直接把Transformer从 NLP 用到 Vision 是有一些挑战的,这个挑战主要来自于两个方面一个就是尺度上的问题。因为比如说现在有
【简单作业向】【Pytorch】猫狗分类
【作业向】根据给定的猫狗分类数据集,对比不同训练方法的差异,并生成的模型的正向传播图。
pytorch加载模型和模型推理常见操作
pth文件可以保存模型的拓扑结构和参数,也可以只保存模型的参数,取决于model.save()中的参数。
多模态情感识别-MISA: baseline解读
不同模态数据分布的异质性使得模态融合的难度较高
关于迁移学习的方法
迁移学习的具体实现
火星探测器背后的人工智能:从原理到实战的强化学习
本文详细探讨了强化学习在火星探测器任务中的应用。从基础概念到模型设计,再到实战代码演示,我们深入分析了任务需求、环境模型构建及算法实现,提供了一个全面的强化学习案例解析,旨在推动人工智能技术在太空探索中的应用。
注意力机制——Convolutional Block Attention Module(CBAM)
其中通道注意力模块通过对输入特征图在通道维度上进行最大池化和平均池化,然后将这两个池化结果输入到一个全连接层中,最后输出一个通道注意力权重向量。空间注意力模块则通过对输入特征图在通道维度上进行平均池化和最大池化,然后将这两个池化结果输入到一个全连接层中,最后输出一个空间注意力权重张量。CBAM 模块
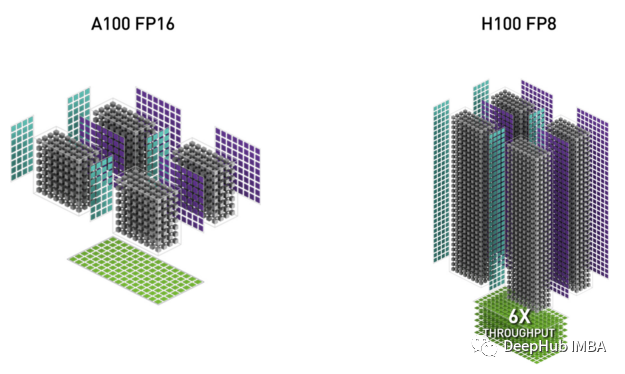
使用FP8加速PyTorch训练
在这篇文章中,我们将介绍如何修改PyTorch训练脚本,利用Nvidia H100 GPU的FP8数据类型的内置支持。
nnUNet原创团队全新力作!MedNeXt:医学图像分割新SOTA
MedNeXt是nnUNet原创团队于2023年3月17日上传至arxiv上的新作品,该模型受ConNeXt启发,根据Transformer改进了现有的卷积网络,实现了医学图像分割领域的SOTA。除了用Transformer改造UNet之外,MedNeXt还改进了上采样和下采样块、提出了一个用小卷积
用TrackEval评测自己的数据集
跑通代码最重要的就是路径问题, 为此我写了两个config模板, 让配置路径更简单.
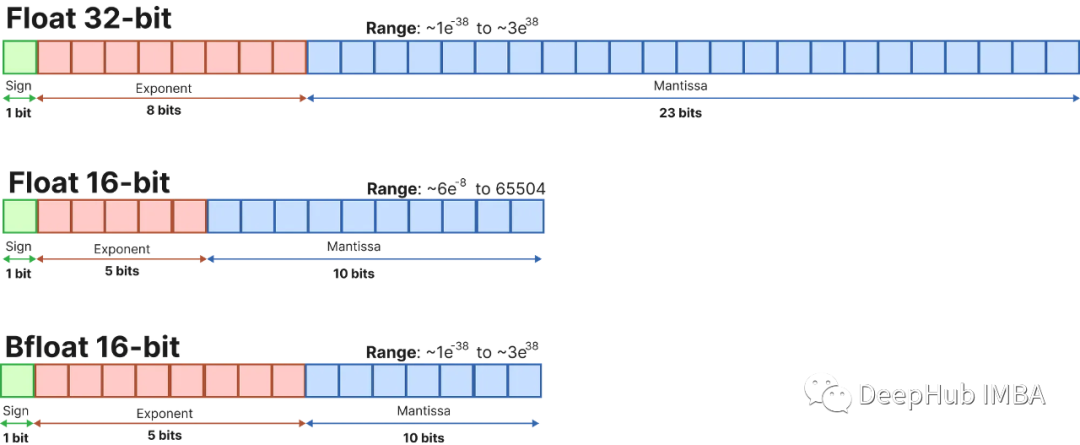
大语言模型量化方法对比:GPTQ、GGUF、AWQ
在过去的一年里,大型语言模型(llm)有了飞速的发展,在本文中,我们将探讨几种(量化)的方式,除此以外,还会介绍分片及不同的保存和压缩策略。



