从GPU的内存访问视角对比NHWC和NCHW
NHWC和NCHW之间的选择会影响内存访问、计算效率吗?本文将从模型性能和硬件利用率来尝试说明这个问题。
华为开源自研AI框架昇思MindSpore应用案例:分布式并行训练基础样例(CPU)
华为开源自研AI框架昇思MindSpore应用案例:分布式并行训练基础样例
U-Net 模型改进和应用场景研究性综述
参考之前的一篇文章:U-Net代码练习结构性改进就三种情况,编码器解码器改进,跳连接改进,以及模型整体结构改进;大 部 分 改 进 工 作是在原有模块的基础上,增加残差模块、Dense 模 块 、Inception 模 块 、Attention 模 块 等 经 典 网 络 模 块 , 或 综 合 运
使用python实现LDA线性判别分析
LDA(Linear Discriminant Analysis)线性判别分析是一种监督学习的线性分类算法,它可以将一个样本映射到一条直线上,从而实现对样本的分类。LDA的目标是找到一个投影轴,使得经过投影后的两类样本之间的距离最大,而同一类样本之间的距离最小。LDA的过程可以分为以下几步:1.计算
【人工智能】深度强化学习的新突破:如何打造智能决策系统
在深度强化学习中,有很多的概念和术语需要我们去了解。本文介绍了深度强化学习技术的相关概念、原理及应用,以及如何使用深度强化学学实现智能决策系统。在深度强化学习中,模型设计、数据集选择、模型评估和应用场景都是需要我们注意的重要因素。通过实际案例的演示,我们可以看到深度强化学习技术在实践中的应用和实现过

CLIP与DINOv2的图像相似度对比
在本文中,我们将探讨CLIP和DINOv2的优势和它们直接微妙的差别。我们的目标是发现哪些模型在图像相似任务中真正表现出色。
【人工智能】大模型时代,程序员需要具备哪些技能才能胜任?
近年来,随着深度学习技术的飞速发展和计算能力的提升,大模型已经成为了人工智能领域的一个重要趋势。而在这个趋势中,程序员的技能需求也在不断变化和升级。本文将为大家介绍,在大模型时代,程序员需要具备哪些技能才能胜任。
图-文多模态,大模型,预训练
图-文任务是指需要同时处理图像和文本数据的任务,如图像描述、图像检索(image retrieval)、视觉问答(visual question answering)等。例如,图像描述(image captioning)就是一种典型的多模态任务,它需要根据给定的图像生成相应的文本描述。既不是单塔模型
python-matplotlib-箱线图为不同的箱体设置不同颜色
python-matplotlib-箱线图为不同的箱体设置不同颜色。
ChainForge:衡量Prompt性能和模型稳健性的GUI工具包
ChainForge是一个用于构建评估逻辑来衡量模型选择,提示模板和执行生成过程的GUI工具包。ChainForge可以安装在本地,也可以从chrome浏览器运行。

用于数据增强的十个Python库
在本文中,我们将介绍数据增强的十个Python库,并为每个库提供代码片段和解释。
【深入探究人工智能】:历史、应用、技术与未来
人工智能(Artificial Intelligence,AI作为一门前沿科技,正以惊人的速度深刻改变着我们的生活和社会。本篇将从人工智能的历史、应用、技术和未来四个方面深入探讨,同时也介绍一些当代的人工智能产物,带你领略AI技术的魅力与应用。当代的人工智能产物不断涌现,为我们的生活带来了越来越多的
范数详解-torch.linalg.norm计算实例
本文以torch.linalg.norm(),详细讲解二范数、F范数、核范数、无穷范数、L1范数、L2范数的定义和计算。
Huggingface Transformers Deberta-v3-base安装踩坑记录
huggingface deberta-v3-base下载踩坑记录
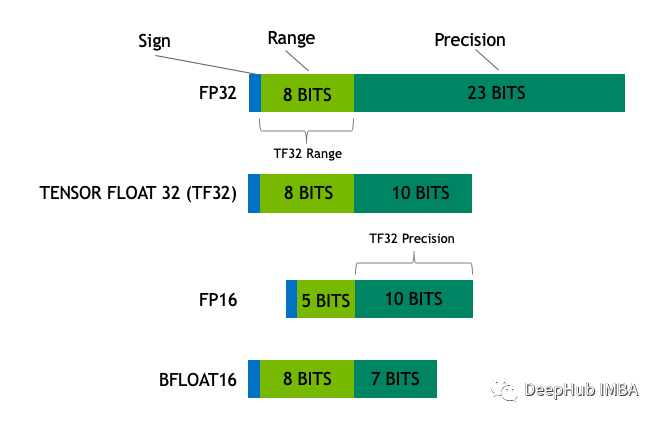
16,8和4位浮点数是如何工作的
在本文中,我们将介绍最流行的浮点格式,创建一个简单的神经网络,并了解它是如何工作的。
2023知识追踪最新综述来自顶刊!!!——《Knowledge Tracing:A Survey》
2023知识追踪最新综述——《Knowledge Tracing:A Survey》,文章发表在ACM Computing Survey上
【人工智能】《大模型十问》—— 我们认为大模型值得探索的十个问题
看过有些评论说,大模型出现后NLP没什么好做的了。在我看来,在像大模型这样的技术变革出现时,虽然有很多老的问题解决了、消失了,同时我们认识世界、改造世界的工具也变强了,会有更多全新的问题和场景出现,等待我们探索。所以,不论是自然语言处理还是其他相关人工智能领域的学生,都应该庆幸技术革命正发生在自己的
OpenMMLab-AI实战营第二期——2-1.人体关键点检测与MMPose
关键点提取,属于模式识别人体姿态估计的下游任务:行为识别(比如:拥抱。。下游任务:CG和动画,这个是最常见的应用下游任务:人机交互(手势识别,依据收拾做出不同的响应,比如:HoloLens会对五指手势(3D)做出不同的反应)自顶向下方法自底向上方法单阶段方法基于Transformer的方法。
TCN(时间卷积网络)实现时间序列预测(PyTorch版)
本专栏整理了《深度学习时间序列预测案例》,内包含了各种不同的基于深度学习模型的时间序列预测方法,例如LSTM、GRU、CNN(一维卷积、二维卷积)、LSTM-CNN、BiLSTM、Self-Attention、LSTM-Attention、Transformer等经典模型,包含项目原理以及源码,每一

使用ExLlamaV2在消费级GPU上运行Llama2 70B
在本文中,我将展示如何使用ExLlamaV2以混合精度量化模型。我们将看到如何将Llama 2 70b量化到低于3位的平均精度。



