2022数学建模国赛C题思路分析
2022国赛数学建模C题思路分析
【2022高教社杯数学建模】C题:古代玻璃制品的成分分析与鉴别方案及代码实现(已经更新完毕)
【2022高教社杯数学建模】C题:古代玻璃制品的成分分析与鉴别方案及代码实现(1)对表1中,统计风化程度与玻璃类型、纹饰、颜色的关系,作出柱状图可视化或者饼状图(2)利用文物采样点结合表1和表2,对不同玻璃类型,再划分有无风化,对化学成分统计,即四种情况求均值求出风化前后的差值(3)线性回归,求风化

使用阈值调优改进分类模型性能
在本文中将演示如何通过阈值调优来提高模型的性能。
《白皮书》:身边的人脸安全事件及背后的三类攻击手段
所涉收集人脸数据,能通过人脸识别信息解决精准营销,抓取的人脸数据信息累计上亿。顶象《人脸识别安全白皮书》共有8章73节,系统对人脸识别的组成、人脸识别的内在缺陷、人脸识别的潜在安全隐患、人脸识别威胁产生的原因、人脸识别安全保障思路、人脸识别安全解决方案、国家对人脸识别威胁的治理等进行了详细介绍及重点
CLIP,GLIP论文解读,清晰明了
CLIP:Contrastive Language-Image Pre-training,论文名称:Learning Transferable Visual Models From Natural Language Supervision。GLIP论文名称:Grounded Language-Im
2022年高教社杯国赛E题思路——小批量物料的生产安排
某电子产品制造企业面临以下问题:在多品种小批量的物料生产中,事先无法知道物料的实际需求量。企业希望运用数学方法,分析已有的历史数据,建立数学模型,帮助企业合理地安排物料生产。请对附件中的历史数据进行分析,选择 6 种应当重点关注的物料(可从物料需求出现的频数、数量、趋势和销售单价等方面考虑),建立物
Code For Better 谷歌开发者之声 ——Tensorflow与深度学习
TensorFlow 是由 Google 团队开发的深度学习框架之一,它是一个完全基于 Python 语言设计的开源的软件。
一文速学-时间序列分析算法之移动平均模型(MA)详解+Python实例代码
有一段时间没有继续更新时间序列分析算法了,传统的时间序列预测算法已经快接近尾声了。按照我们系列文章的讲述顺序来看,还有四个算法没有提及:平稳时间序列预测算法都是大头,比较难以讲明白。但是这个系列文章如果从头读到尾,细细品味研究的话,会发现时间序列预测算法从始至终都在做一件事,也就是如何更好的利用到历
Python 实现 AI 拟声: 5秒内克隆您的声音并生成任意语音内容
🌍 中文 支持普通话并使用多种中文数据集进行测试:aidatatang_200zh, magicdata, aishell3, biaobei, MozillaCommonVoice, data_aishell 等🤩 PyTorch 适用于 pytorch,已在 1.9.0 版本(最新于 202
A9.2022年全国数学建模竞赛 C题-玻璃制品的成分分析与鉴别-赛题分析与讨论
1. 2022年C题(玻璃制品的成分分析与鉴别)2.1 基本分析:分类问题+聚类问题+预测问题2.2 聚类问题参考例程Kmeans 聚类例程:2.3 分类问题参考例程分类问题 Python 例程1:LinearSVC 使用例程分类问题 Python 例程2:NuSVC 使用例程3. 参考文献
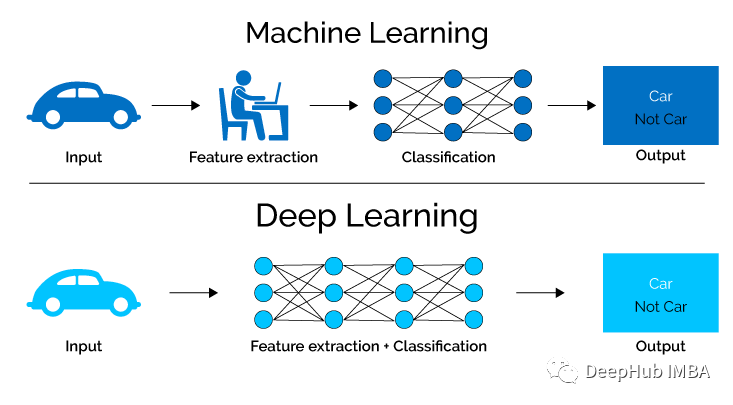
最基本的25道深度学习面试问题和答案
如果你最近正在参加深度学习相关的面试工作,那么这些问题会对你有所帮助。
保障人脸安全!顶象发布《人脸识别安全白皮书》
此后分别是娱乐10%、医疗7%、电商零售6%、出行3%、政务2%、其他2%。该白皮书共有8章73节,系统对人脸识别的组成、人脸识别的内在缺陷、人脸识别的潜在安全隐患、人脸识别威胁产生的原因、人脸识别安全保障思路、人脸识别安全解决方案、国家对人脸识别威胁的治理等进行了详细介绍及重点分析。人脸识别是基于
Part 11:Pandas的索引index所具备的四大性能
把数据存储于普通的column列也能用于数据查询,那使用index有什么好处?当s1+s2中遇到另一方没有找到相同的索引时,会显示NaN,无法进行算术操作时。Categoricallndex,基于分类数据的Index,提升性能;Datetimelndex,时间类型索引,强大的日期和时间的方法支持;%
【机器学习】Logistic 分类回归算法 (二元分类 & 多元分类)
一、线性回归能用于分类吗?二、二元分类2.1假设函数2.1.1例子一2.1.2例子二2.2拟合logistic回归参数\thetaθ三、logistic代价函数3.1 y = 1的图像3.2 y = 0的图像四、 代价函数与梯度下降4.1 线性回归与logistic回归的梯度下降规则相同吗?五、高级
图像处理那些算法
1)旋转借助矩阵运算来实现图像的旋转功能2)平移借助矩阵运算来实现图像的旋转功能3)对称借助矩阵运算来实现图像的对称功能水平镜像变换:垂直镜像变换:借助 get (gca, ‘currentPoint’)获取鼠标点击的位置,从而得到鼠标按下和松开的两个位置的坐标。将这两个点的位置提取出来去截取图片。
Python 3.14 将比 C++ 更快🤭
使用外推法证明Python 3.14 将比 C++ 更快🤭
拿下Transformer
对于每一个x向量,网络又可以通过乘WQ,WK,WV衍生出三个向量Q1,K1,V1向量。对于所有的Xi来说,其乘的WQ,WK,WV都是一模一样的(即权重是共享的)。Self attention所作的内容,总结一下就是一个包含三个参数矩阵WQ,WK,WV的模块,输出为m个Context vector,并
YOLOv7(目标检测)入门教程详解---环境安装
零基础入门yolov7 从环境安装到推理训练,再到c++实现yolov7
基于蒲公英优化算法的函数寻优算法
文献[1]模拟蒲公英种子依靠风的长距离飞行过程提出了一种新的群体智能仿生优化算法,称为蒲公英优化(Dandelion Optimizer, DO)算法,用于解决连续优化问题。与其他自然启发元启发式算法相似,DO在种群初始化的基础上进行种群进化和迭代优化。在提出的DO算法中,假设每个蒲公英种子代表一个
【31】GPU(下):为什么深度学习需要使用GPU?
GPU发展历史:1.加速卡(顶点处理仍在CPU完成,图像渲染受制于CPU的性能);2.带有顶点处理功能的显卡:NVidia推出GeForce 256 显卡;3.可编程管线(Programable Function Pipeline)的引入:2001年的Direct3D 8.0【微软第一次引入】;4.



