

前言
深度学习的框架其实有很多,目前来说最火的还要数Pytorch、TensorFlow以及Keras。其中Pytorch比较适合学术研究,自己搞着玩,如果工业实践就不太适合了。TensorFlow由于时间比较久,学起来比较困难,不过有完整的开发、部署方案,还有大量的github项目可供参考。Keras则是TensorFlow的一个高级API,同类的还有TensorFlow的TFLearn等等。
一、End-to-End Machine Learning with TensorFlow on GCP(基于TensorFlow的机器学习)
1.什么是TensorFlow
TensorFlow是一个基于数据流编程符号数学系统,被广泛应用于各类机器学习算法的编程实现,其前身是谷歌的神经网络算法库DistBelief。Tensorflow拥有多层级结构,可部署于各类服务器、PC终端和网页并支持GPU和TPU高性能数值计算,被广泛应用于谷歌内部的产品开发和各领域的科学研究。
2.TensorFlow优点
- 易用性:有对应Python的API
- 可移植性:一套代码就可以适应单个或者多个CPU、GPU、移动设备等
- 灵活性:可以部署在树莓派、安卓、windows、ios、linux等上
- 可视化:有tensorboard提供开发的可视化界面,方便跟踪调参
- 检查点:可以通过检查点记录保存实验数据
- 自动微积分:自动求解梯度
- 庞大的社区:一年内拥有10000+的开发者,3000+的项目
- 大量基于TensorFlow的项目代码
3.搭建TensorFlow Serving集群
TensorFlow Serving也提供了Docker的方式来安装或使用,但是目前并没有提供官方镜像或者提供Dockerfile来进行自动构建。现在需要通过手工方式来构建TensorFlow Serving镜像。为了简化部署,我提供了两个预构建的TensorFlow Serving的示例镜像来进行测试。
registry.cn-hangzhou.aliyuncs.com/denverdino/tensorflow-serving : TensorFlow Serving的基础镜像
registry.cn-hangzhou.aliyuncs.com/denverdino/inception-serving : 基于上述基础镜像添加Inception模型实现的服务镜像
** 利用Docker命令启动名为 “inception-serving” 容器作为TF Serving服务器**
docker run -d --name inception-serving registry.cn-hangzhou.aliyuncs.com/denverdino/inception-serving
利用Docker命令以交互式方式启动 “tensorflow-serving” 镜像作为客户端,并定义容器link,允许在容器内部通过“serving”别名来访问“inception-serving”容器
docker run -ti --name client --link inception-serving:serving registry.cn-hangzhou.aliyuncs.com/denverdino/tensorflow-serving
** 在客户端容器,执行下面的脚本,可以方便地利用“inception-serving”服务来进行图像识别**
这里图片自己定义,网上就可以找到
# persian cat
curl http://f.hiphotos.baidu.com/baike/w%3D268%3Bg%3D0/sign=6268660aafec8a13141a50e6cf38f6b2/32fa828ba61ea8d3c85b36e1910a304e241f58dd.jpg -o 1.jpg
/serving/bazel-bin/tensorflow_serving/example/inception_client --server=serving:9000 --image=2.jpg
# garfield cat
curl http://a2.att.hudong.com/60/11/01300000010387125853110118750_s.jpg -o 1.jpg
/serving/bazel-bin/tensorflow_serving/example/inception_client --server=serving:9000 --image=2.jpg
二、Machine learning production environment(机器学习生产环境)
这里我们利用Anaconda作为生产环境
Anaconda提供了一个默认的base环境,也可以直接在base环境中开发应用程序。基于课程内容需要,我们创建tensorflow-cpu环境
conda create -n ENV_NAME python=x.x
-n表示环境名称参数,
ENV_NAME为待创建虚拟开发环境的名称,
x.x表示该环境中python的版本是多少
启动Windows命令行窗口,在窗口输入下面的命令
conda create -n tensorflow-cpu python=3.9
若出现‘conda’不是内部或外部命令,也不是可运行的程序等信息,需要配置Anaconda系统环境变量。命令执行完成,名称为tensorflow-cpu的虚拟开发环境就创建成功了。
查看当前Anaconda有哪些虚拟环境
conda env list
激活命令:命令激活环境后,才能进入该虚拟环境进行编程
conda activate ENV_NAME
退出环境命令
若需要退出当前虚拟开发环境,可以使用下面的命令:
conda deactivate
删除环境命令
该命令需谨慎使用,因为该命令会删除虚拟环境下的所有数据
conda remove -n ENV_NAME --all
安装Python依赖包
在tensorflow-cpu环境下使用pip工具软件安装numpy、matplotlib、pillow、pandas、scikit-learn。
启动Windows命令行窗口,在命令行窗口输入激活命令,激活tensorflow-cpu环境。
conda activate tensorflow-cpu
tensorflow-cpu环境激活后,使用pip工具分别安装上述Python依赖包。安装建议使用清华大学镜像站。如安装numpy命令如下:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy
pip安装matplotlib时,会自动安装pillow包。
安装tensorflow-cpu版本
tensorflow分为两个版本,一个是CPU版本,一个是GPU版本。GPU版本充分应用了图形处理器的计算引擎,缩短模型训练的时间,GPU版本需要独立显卡的支持
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorflow==2.6.0
上面的命令将在本地安装tensorflow 2.6.0版本,默认安装是cpu模式。
安装完成,需要验证tensorflow 2.6.0是否安装成功。
启动Windows命令行窗口,使用conda激活命令激活tensorflow-cpu环境,进入Python环境。
C:\Users\1>conda activate tensorflow-cpu
(tensorflow-cpu) C:\Users\1>
(tensorflow-cpu) C:\Users\1>python
>>> import tensorflow as tf
>>> print(tf.__version__)
2.6.0
三、Image Understanding with TensorFlow on GCP(通过TensorFlow进行图像处理)
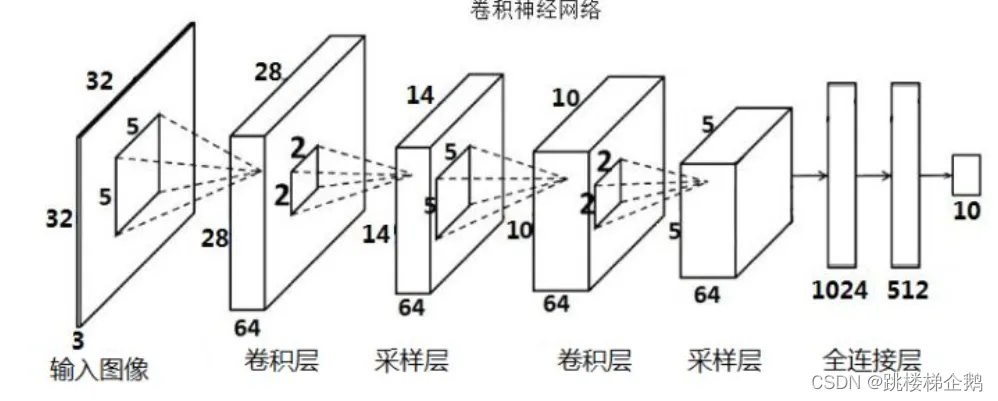
1.神经网络原理
这里的神经网络,也指人工神经网络(Artificial Neural Networks,简称ANNs),是一种模仿生物神经网络行为特征的算法数学模型,由神经元、节点与节点之间的连接(突触)所构成。
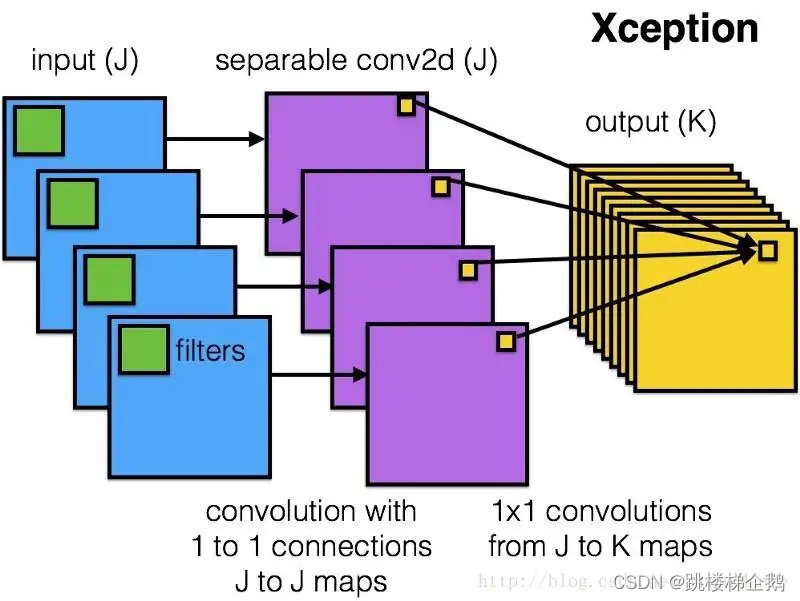
2.卷积层
卷积神经网络中每层卷积层(Convolutional layer)由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法最佳化得到的。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网路能从低级特征中迭代提取更复杂的特征。
图像分析研究的领域一般包括:
基于内容的图像检索(CBIR-Content Based Image Retrieval)
人脸识别(face recognition)
表情识别(emotion recognition)
光学字符识别(OCR-Optical Character Recognition)
手写体识别(handwriting recognition)
医学图像分析(biomedical image analysis)
视频对象提取(video object extraction)
3.池化层
既对数据进行降采样(down-sampling)操作,又可以用p范数(p-norm)作非线性映射的“卷积” p范数:||A||p=(m∑i=1n∑j=1|aij|p)1/p,p>=1p范数:||A||p=(∑i=1m∑j=1n|aij|p)1/p,p>=1
当 p→∞p→∞ 时即为最大池化
具体作用为:
- 特征不变性--使模型更关注包含一定的自由度,能容忍特征微小的位移
- 特征降维--降采样使后续操作的计算量得到减少
- 一定程度防止过拟合
池化层的作用
池化层用于进一步缩小经卷积层处理过后的节点矩阵,从而进一步减少最后交付给全连接神经网络的参数个数。虽然池化层的作用遭到过质疑,但是在大多数模型中仍然使用了池化层。
池化层的处理
池化层中有一个类似于卷积层中过滤器的设置。不过相比卷积层中过滤器的加权求和,池化层中过滤器只是简单地求相应尺寸内子节点矩阵的最大值或者平均值。
池化层与卷积层的区别
池化层中的过滤器与卷积层中过滤器最大的区别是:卷积层内的过滤器可以同时处理当前层中整个深度下的子节点矩阵,而池化层内的过滤器只能一层层深度地处理当前层的子节点矩阵。所以池化层过滤器除了像卷积层内一样在二维上从节点矩阵左上角移动至右下角以外,还会在深度上进行移动。
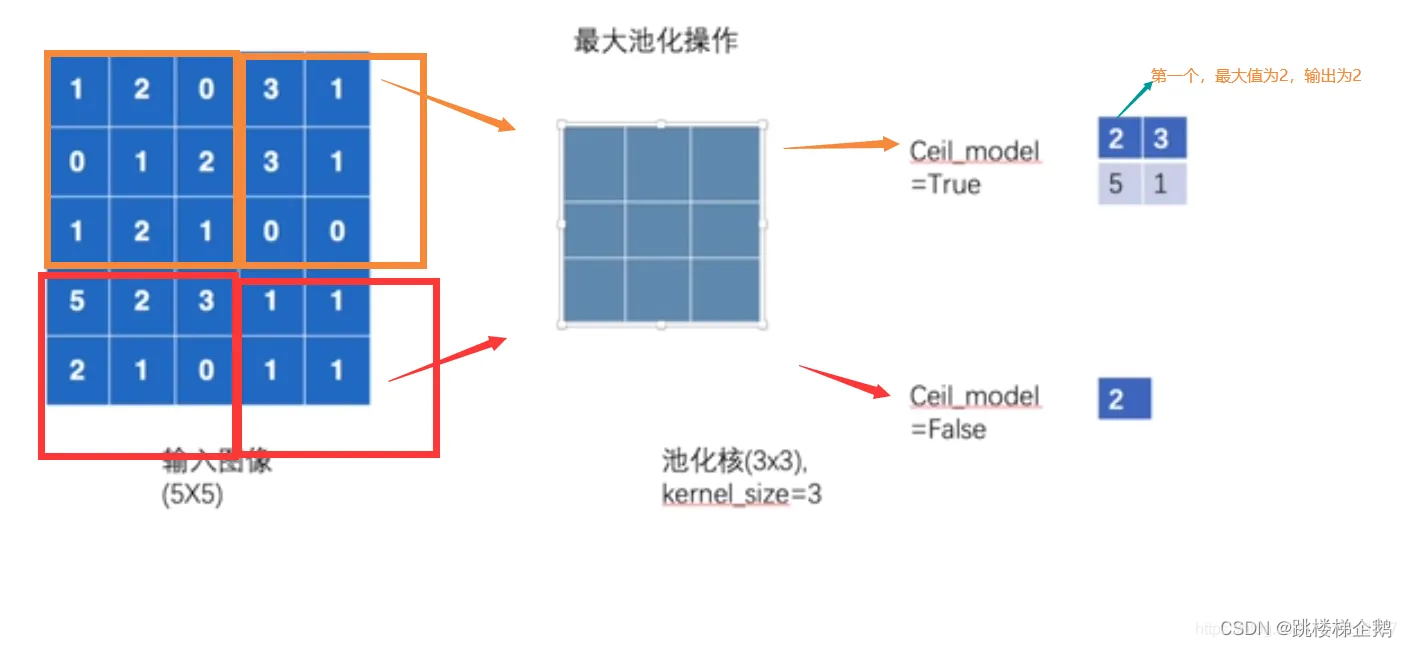
4.Tensorflow中的最大池化层
tf.nn.max_pool()最大池化
函数:
input:指需要做卷积的输入图像,它要求是一个Tensor,具有[batch, in_height, in_width, in_channels]这样的shape,具体含义是[训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数],注意这是一个4维的Tensor,要求类型为float32和float64其中之一
filter:相当于CNN中的卷积核,它要求是一个Tensor,具有[filter_height, filter_width, in_channels, out_channels]这样的shape,具体含义是[卷积核的高度,卷积核的宽度,图像通道数,卷积核个数],要求类型与参数input相同,有一个地方需要注意,第三维in_channels,就是参数input的第四维
strides:卷积时在图像每一维的步长,这是一个一维的向量,长度4
padding:string类型的量,只能是”SAME”,”VALID”其中之一,这个值决定了不同的卷积方式(后面会介绍)
use_cudnn_on_gpu:bool类型,是否使用cudnn加速,默认为true结果返回一个Tensor,这个输出,就是我们常说的feature map
实验:
这里直接附上实验代码
import tensorflow as tf
#case 2
input = tf.Variable(tf.random_normal([1,3,3,5]))
filter = tf.Variable(tf.random_normal([1,1,5,1]))
op2 = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='VALID')
#case 3
input = tf.Variable(tf.random_normal([1,3,3,5]))
filter = tf.Variable(tf.random_normal([3,3,5,1]))
op3 = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='VALID')
#case 4
input = tf.Variable(tf.random_normal([1,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,1]))
op4 = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='VALID')
#case 5
input = tf.Variable(tf.random_normal([1,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,1]))
op5 = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='SAME')
#case 6
input = tf.Variable(tf.random_normal([1,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,7]))
op6 = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='SAME')
#case 7
input = tf.Variable(tf.random_normal([1,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,7]))
op7 = tf.nn.conv2d(input, filter, strides=[1, 2, 2, 1], padding='SAME')
#case 8
input = tf.Variable(tf.random_normal([10,5,5,5]))
filter = tf.Variable(tf.random_normal([3,3,5,7]))
op8 = tf.nn.conv2d(input, filter, strides=[1, 2, 2, 1], padding='SAME')
init = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init)
print("case 2")
print(sess.run(op2))
print("case 3")
print(sess.run(op3))
print("case 4")
print(sess.run(op4))
print("case 5")
print(sess.run(op5))
print("case 6")
print(sess.run(op6))
print("case 7")
print(sess.run(op7))
print("case 8")
print(sess.run(op8))
本篇文章作为Google撰稿活动分享,感谢支持
版权归原作者 跳楼梯企鹅 所有, 如有侵权,请联系我们删除。