pinokio让你在本地轻松跑多种AI模型的神奇浏览器
就像一个网络浏览器,Pinokio本身不会做任何事情,但随着人们围绕它构建和分享应用、工作流和API,它将变得越来越有用。订阅我们的中文简报,深入解析最新的技术突破、实际应用案例和未来的趋势。Pinokio是一个浏览器,可以让您自动且轻松地安装、运行和自动化任何AI应用和模型。再也不需要打开终端。但
torch.einsum() 用法说明
这里,j 是求和下标,i 和 k 是输出下标(有关原因的更多详细信息,请参见下面的部分)。例外情况是,如果对相同的输入操作数重复下标,在这种情况下,此操作数的标有此下标的维度必须在大小上匹配,并且操作数将被其沿这些维度的对角线替换。,它将覆盖下标未覆盖的维度,例如,对于具有 5 维的输入操作数,等式
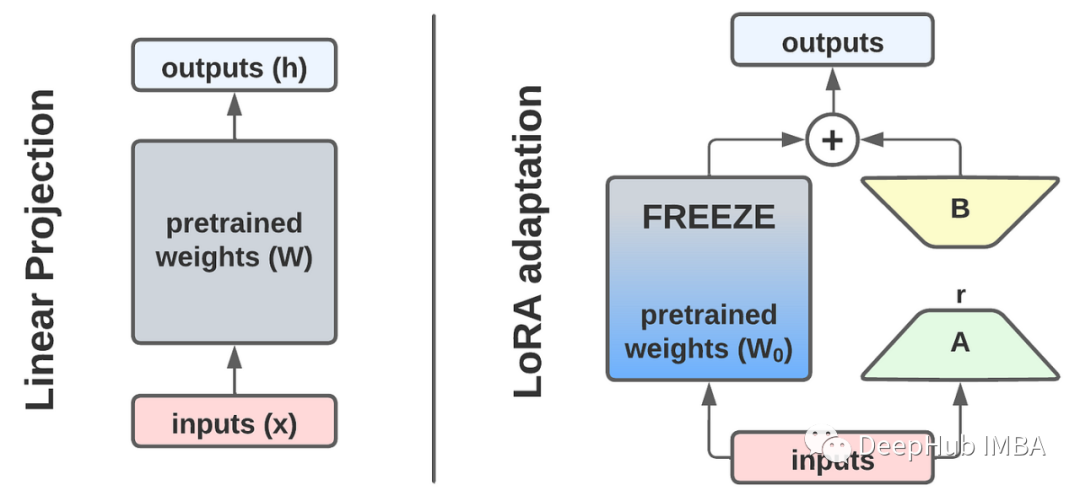
从头开始实现LoRA以及一些实用技巧
本文将首先深入研究LoRA,然后以RoBERTa模型例从头开发一个LoRA,然后使用GLUE和SQuAD基准测试对实现进行基准测试,并讨论一些技巧和改进。
【PaddleDetection】基于PaddleDetection的齿轮瑕疵检测:从模型训练到部署中的那些坑
本文的主要内容是一套利用百度飞桨深度学习平台下的目标检测套件实现目标检测任务(从模型训练到部署)的流程。本文中流程将最大限度地利用飞桨现有工具套件和API,以尽最大可能减少编程工作。本文所完成的任务来自“兴智杯”全国人工智能创新应用大赛:国产开发框架工程化应用赛,其主要内容为基于目标检测算法的齿轮瑕

2023年12月 论文推荐
12月已经过了一半了,还有2周就是2024年了,我们来推荐下这两周我发现的一些好的论文,另外再推荐2篇很好的英文文章。
17届全国大学生智能汽车竞赛 中国石油大学(华东)智能视觉组 国特开源
所有开源代码已上传到我的[GitHub仓库](https://github.com/shuoshuof/17-openmv-)。 因为寒假回家,大部分的代码都在实验室主机上。所以开源的代码大部分重新编写过,没有经过上车测试。如果发现问题,请及时给我留言或者提issue。 希望我的开
【头歌平台】人工智能-深度学习初体验
神经网络中也有神经元,这些神经元也会与其他神经元相连接,这样就形成了神经网络,而且这种网络我们称之为。如下图所示():从图可以看出,神经网络由一层一层的神经元所构成的,并且不同的层有不同的名字。其中表示用来接收数据输入的一组神经元。表示用来输出的一组神经元。表示介于输入层与输出层之间的一组神经元。
pytorch实战5——DataLoader数据集制作
DataLoader数据集制作
经典文献阅读之--Orbeez-SLAM(单目稠密点云建图)
对于现在的VSLAM而言,现在越来越多的工作开始聚焦于如何将深度学习结合到VSLAM当中,而最近的这个工作就给出了一个比较合适的方法。》这篇文章,可以轻松适应新的场景,而不需要预先训练,并实时为下游任务生成密集的地图。它成功地与隐式神经表示法(NERF)和视觉里程法相结合,实现了只需要RGB输入即可
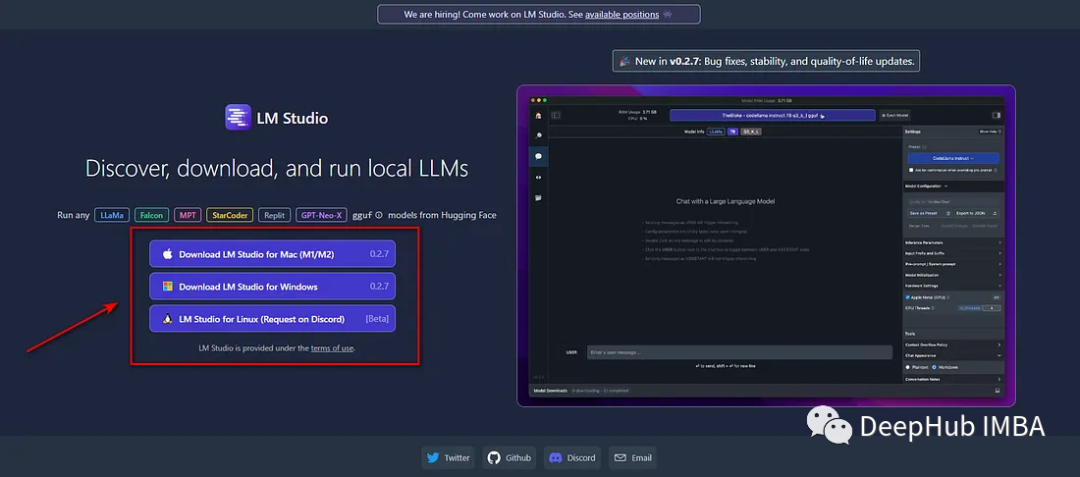
使用LM Studio在本地运行LLM完整教程
LM Studio是一个免费的桌面软件工具,它使得安装和使用开源LLM模型非常容易。
神经网络实验报告-tensorflow基础
NumPy是Python中最重要的科学计算库之一,提供了多维数组、矩阵等数值计算功能,具有良好的数据处理能力和高效的计算性能,并且拥有丰富的函数库,可以进行数据加工、处理、筛选等操作。而TensorFlow则是一个由Google开发的机器学习框架,可以用来构建和训练神经网络等深度学习模型,提供灵活的
BERT+TextCNN实现医疗意图识别项目
BERT+TextCNN实现医疗意图识别项目
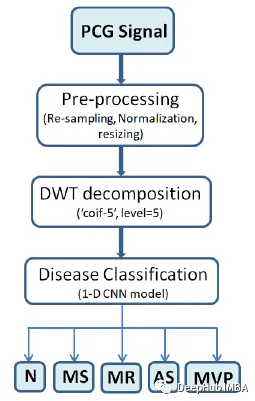
一种用于心音分类的轻量级1D-CNN+DWT网络
利用离散小波变换(DWT)得到的多分辨率域特征对1D-CNN模型进行心音分类训练。
2.树莓派4B 64位操作系统 从零搭建深度学习项目运行环境
树莓派的系统烧录树莓派的基础配置树莓派的开机连接树莓派的文件传输树莓派的软件安装树莓派的运行环境树莓派的系统备份测试运行现有模型。
通道信息,空间信息,通道注意力以及空间注意力
通道信息,空间信息,通道注意力以及空间注意力
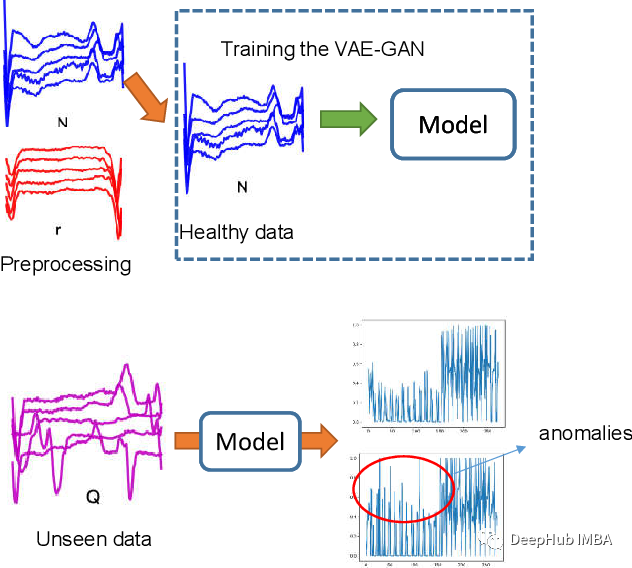
使用GAN进行异常检测
GAN是一种深度学习模型,可以学习生成与给定数据集相似的真实数据样本。这一特性表明它们可以成功地用于异常检测
Pytorch学习笔记(5):torch.nn---网络层介绍(卷积层、池化层、线性层、激活函数层)
Pytorch学习笔记(5):torch.nn---网络层介绍(卷积层、池化层、线性层、激活函数层)
深度学习算法:探索人工智能的前沿
深度学习,作为人工智能领域的瑰宝,已经在过去的几年里引起了广泛关注。这一领域的快速发展为解决复杂的问题提供了新的工具和方法。本文将深入探讨深度学习算法的核心概念、应用领域以及未来发展趋势,以期为读者提供对这一领域的全面理解。
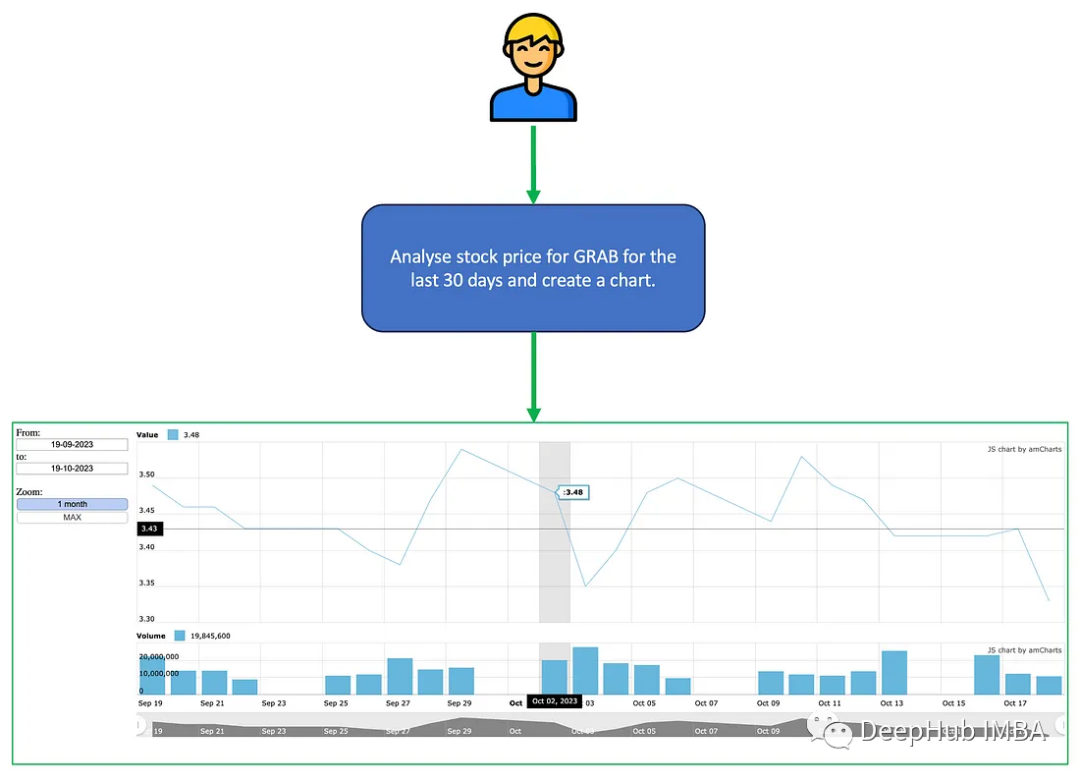
AutoGen多代理对话项目示例和工作流程分析
在这篇文章中,我将介绍AutoGen的多个代理的运行。这些代理将能够相互对话,协作评估股票价格,并使用AmCharts生成图表。
GAN(Generative Adversarial Nets (生成对抗网络))
②部分,此时判别器D的输入为G(z),为假图像,但是我们期望的是生成器的效果好,即尽可能的瞒过D,也就是期望D(G(z))尽可能大,越大表示D判定假图像为真实数据的概率越大,也就表明生成器G生成的图像效果好,可以成功的骗过D。在训练的时候,D(G(z))越大越接近于1,y越小,生成器生成的假图越被判



