人工智能 -- 神经网络
但我们并不知道他的分析过程是怎样的,它是如何判断里面是否有猫的。就像当我们教小孩子认识猫时,我们拿来一些白猫,告诉他这是猫,拿来一些黑猫,告诉他这也是猫,他脑子里会自己不停地学习猫的特征。最后我们拿来一些花猫,问他,他会告诉你这也是猫。而人工神经网络则不同,它的内部是一个黑盒子,就像我们人类的大脑一
[log_softmax]——深度学习中的一种激活函数
具体来说,在模型训练过程中,[log_softmax]可以被当作是损失函数的一部分,用于计算预测值与真实值之间的距离。在深度学习中,我们需要将神经网络的输出转化为预测结果,而由于输出值并非总是代表着概率,因此我们需要使用激活函数将其转化为概率值。总结来说,[log_softmax]是深度学习中非常重
人工智能 - 图像分类:发展历史、技术全解与实战
在本文中,我们深入探讨了图像分类技术的发展历程、核心技术、实际代码实现以及通过MNIST和CIFAR-10数据集的案例实战。文章不仅提供了技术细节和实际操作的指南,还展望了图像分类技术未来的发展趋势和挑战。
(HGNN) Hypergraph Neural Networks
提出了一个用于数据表示学习的超图神经网络(HGNN)框架,它可以在超图结构中编码高阶数据相关性。面对在实际实践中学习复杂数据表示的挑战,我们建议将这种数据结构合并到超图中,这在数据建模上更加灵活,特别是在处理复杂数据时。该方法设计了一种来处理表示学习过程中的数据相关性。这样,传统的超图学习过程就可以
深入探讨机器学习中的过拟合现象及其解决方法
真正喜欢的人和事都值得我们去坚持。
MiniGPT-4开源了,史无前例的AI图片内容分析,甚至能用于逻辑验证码推理识别
MiniGPT-4 仅使用一个投影层将来自 BLIP-2 的冻结视觉编码器与冻结 LLM(小羊驼)对齐。我们用两个阶段训练 MiniGPT-4. 第一个传统的预训练阶段是使用 4 个 A100 在 10 小时内使用大约 500 万个对齐的图像-文本对进行训练。在第一阶段之后,小羊驼能够理解图像。但小

使用Accelerate库在多GPU上进行LLM推理
本文将使用多个3090将llama2-7b的推理扩展在多个GPU上
Facebook AI团队的DETR模型代码复现
5.开始训练,Facebook AI 团队训练了 300 个 epoch,这里推荐修改 为 100,修改自己数据集位置 train2017 和 val2017 以及标注文件的路径,修改自己权重文件路径,开始训练, 训练完成之后会在output生成自己的训练模型 check 什么文件,记住他的路径。这
粒子群算法优化策略总结
非线性递减惯性权重,前期w取值较大,具有较强的全局搜索能力,后期w取值较小,具有较强的局部搜索能力,而非线性递增惯性权重则与之相反,前期w取值较小,具有较强的局部搜索能力,后期w取值较大,具有较强的全局搜索能力。混沌Sine映射作为一种经典的混沌映射,具有良好的遍历性等优点,增加了算法的随机性,使算
图卷积网络(Graph Convolution Network,GCN)
在图神经网络出现之前,一般的神经网络只能对常规的欧式数据进行处理,其特点就是节点有固定的排列规则和顺序,如2维网格和1维序列。近几年来,将深度学习应用到处理和图结构数据相关的任务中越来越受到人们的关注。图神经网络的出现使其在上述任务中取得了重大突破,比如在社交网络、自然语言处理、计算机视觉甚至生命科
深度学习——制作自己的VOC图像分割数据集
labelme主要是制作语义分割数据集(ImageSets,JPEGImages,SegmentationClass,SegmentationObject几个文件夹),labelImg主要是制作目标检测数据集(主要是Annoations中的xml文件),最后把两个合在一起就可以使用maskR-CNN
DETR(DEtection TRansformer)要点总结
DETR翻译过来就是检测transformer,是Detection Transformers的缩写。这是一个将2017年大火的transformer结构首次引入目标检测领域的模型,是transformer模型步入目标检测领域的开山之作。利用transformer结构的自注意力机制为各个目标编码,依
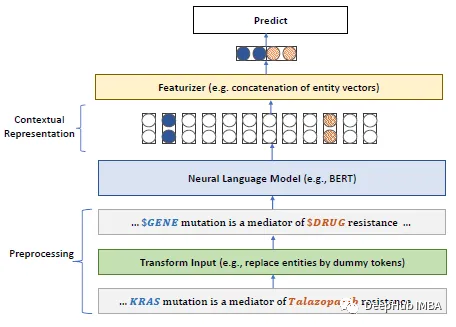
PubMedBERT:生物医学自然语言处理领域的特定预训练模型
语言模型并不一定就是最优的解决方案,“小”模型也有一定的用武之地
RuntimeError: stack expects each tensor to be equal size ??
RuntimeError: stack expects each tensor to be equal size
MNIST数据集ubyte格式数据解析
MNIST数据集格式解析
上采样,下采样,卷积,反卷积,池化,反池化,双线性插值【基本概念分析】
然而,确实有一些缩放方法能够增加图像的信息,从而使得缩放后的图像质量超过原图质量的。在右边的等式中的字母f(Q11)、f(Q12)、f(Q21)、f(Q22)、x1、x2、x都是已知的,求出的f(x,y1)与f(x,y2)即为R1、R2的像素值。那么就从左上角到右下角,生成卷积之后的矩阵的大小是(5
多模态技术综述
多模态机器学习是对计算机算法的研究,通过使用多模态数据集来学习和提高性能。多模式深度学习是一个机器学习子领域,旨在训练人工智能模型来处理和找到不同类型的数据(模式)之间的关系,通常是图像、视频、音频和文本。通过组合不同的模式,深度学习模型可以更普遍地理解其环境,因为一些线索只存在于某些模式中。想象一
Tensorflow在pycharm中安装不上怎么办
Tensorflow在pycharm中安装不上怎么办
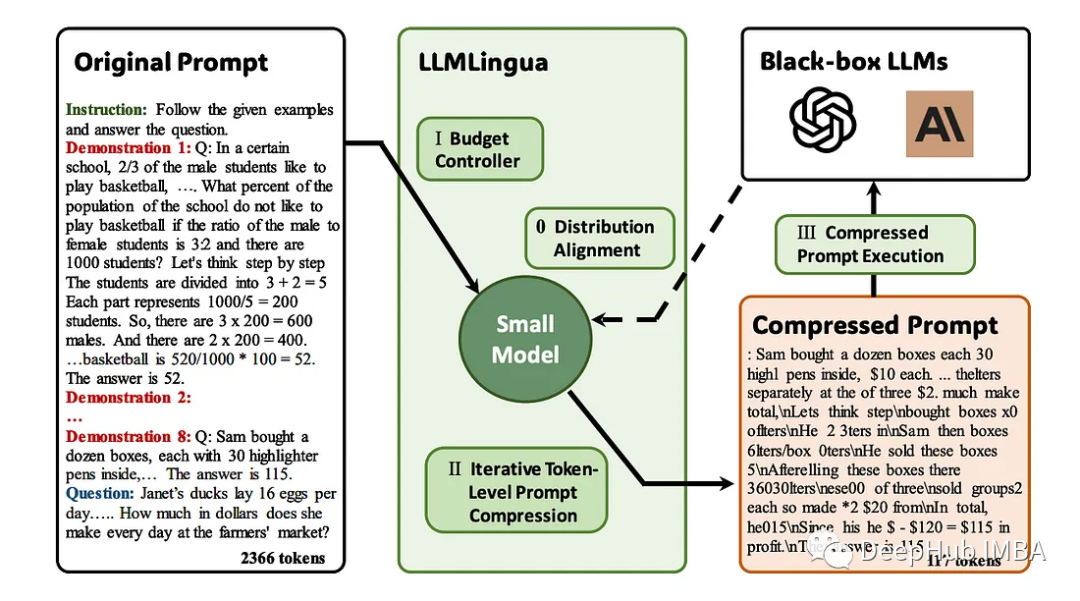
LLMLingua:集成LlamaIndex,对提示进行压缩,提供大语言模型的高效推理
大型语言模型(llm)的出现刺激了多个领域的创新。但是在思维链(CoT)提示和情境学习(ICL)等策略的驱动下,提示的复杂性不断增加,这给计算带来了挑战。
pytorch:参数pin_memory=True和non_blocking=True的作用
参数pin_memory=True和non_blocking=True的作用



