梯度消失与梯度爆炸产生、原理和解决方案
本文章总结了梯度消失与梯度爆炸产生、原理和解决方案。
python深度学习【transforms所有用法介绍】
python深度学习【transforms所有用法介绍】
AI:87-基于深度学习的街景图像地理位置识别
基于深度学习的街景图像地理位置识别随着深度学习技术的飞速发展,人工智能在各个领域展现出强大的潜力。其中,基于深度学习的街景图像地理位置识别成为近年来备受关注的研究方向之一。本文将深入探讨深度学习在街景图像地理位置识别中的应用,介绍相关算法和技术,并附上实际代码示例。街景图像地理位置识别是指通过分析街
Transformer中的注意力机制及代码
transformer注意力机制实现过程整理。
【自监督】系列(二)-代理任务(Pretext Task)
本系列第二弹就来学习下代理任务(pretext task),Pretext可以理解为是一种为达到特定训练任务而设计的间接任务。
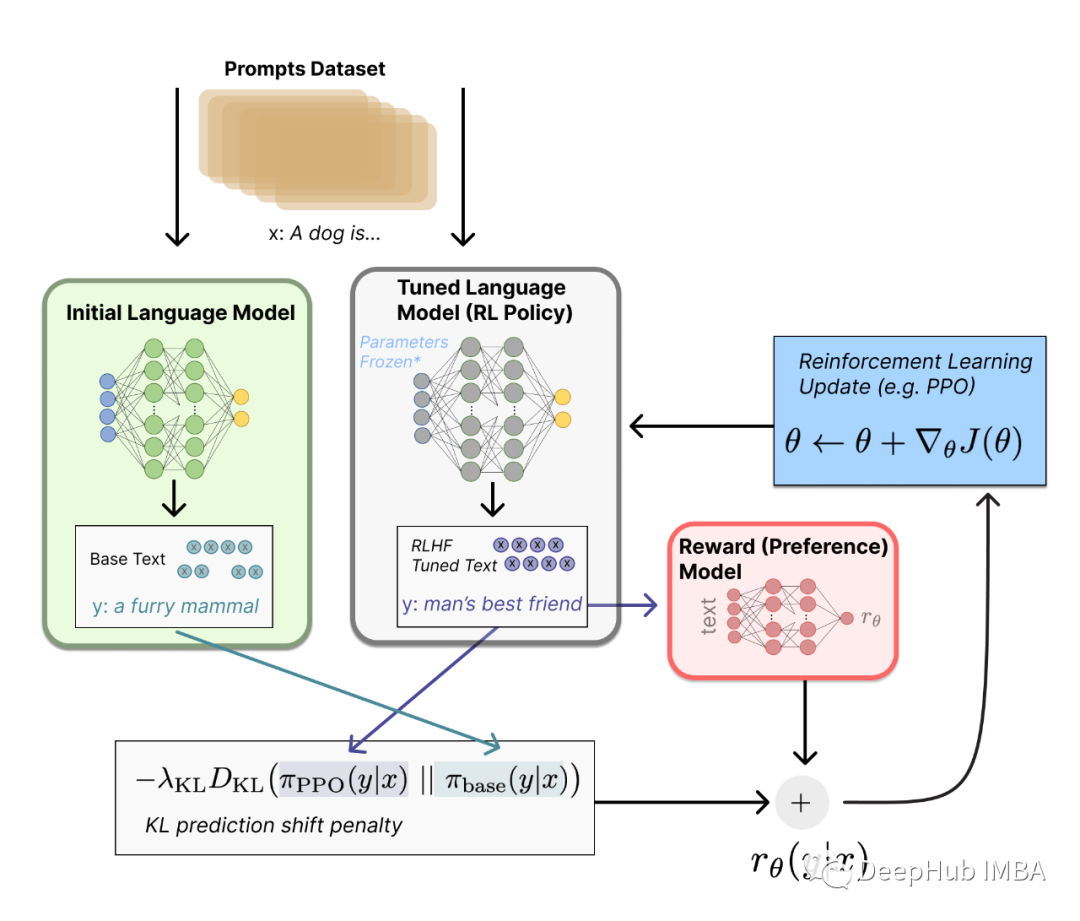
使用Huggingface创建大语言模型RLHF训练流程的完整教程
在本文中,我们将使用Huggingface来进行完整的RLHF训练。
Anaconda Navigator 无法打开解决办法
Anaconda Navigator 时不时出现打不开,或者点击图标无反应的情况。
机器学习|优化算法 | 评估方法|分类模型性能评价指标 | 正则化
机器学习|正则化|评估方法|分类模型性能评价指标|吴恩达学习笔记(哔哩哔哩视频and课堂PPT笔记梳理)
神经网络的类型分类和结构理解
神经网络按照不同的分类方式,会有多种形式的划分。第一种分类方式是按照类型来分,包含两种类型,分别为前馈神经网络和反馈神经网络。掌握神经网络层与层之间的结构后,会有助于我们对神经网络的理解,从而更好的理解参数模型,找到算法合适的参数。
人工智能 - 人脸识别:发展历史、技术全解与实战
本文全面探讨了人脸识别技术的发展历程、关键方法及其应用任务目标,深入分析了从几何特征到深度学习的技术演进。

11月推荐阅读的12篇大语言模型相关论文
现在已经是12月了,距离2024年只有一个月了,本文总结了11月的一些比较不错的大语言模型相关论文
文本识别CRNN模型介绍以及pytorch代码实现
文本识别CRNN pytorch
人工智能概论报告-基于PyTorch的深度学习手写数字识别模型研究与实践
CQUPT人工智能概论的课程大作业实践应用报告,供大家参考,如果有需要word版的可以私信我,或者在评论区留下邮箱,我会逐个发。word版是我最后提交的,已经调整统一了全文格式等。希望能给大家提供一些参考。如果起到作用请给我点个赞哦,嘿嘿嘿嘿
目标检测算法——图像去雾开源数据集汇总(速速收藏)
🎄🎄近期,小海带在空闲之余收集整理了一批图像去雾开源数据集资源供大家参考。整理不易,小伙伴们记得一键三连喔!!!🎈🎈
深度学习论文学习
高光谱图像分类
【古诗生成AI实战】之五——加载模型进行古诗生成
这部分是项目中非常激动人心的一环,因为我们将看到我们的模型如何利用先前学习的知识来创造出新的古诗文本。这是一个重要的里程碑,因为训练好的模型是我们进行文本生成的基础。* 生成文本:从初始文本(例如“天”)开始,逐字生成新的文本,直到达到指定长度(如32个字符)。在这部分内容中,我们将探讨如何使用预训
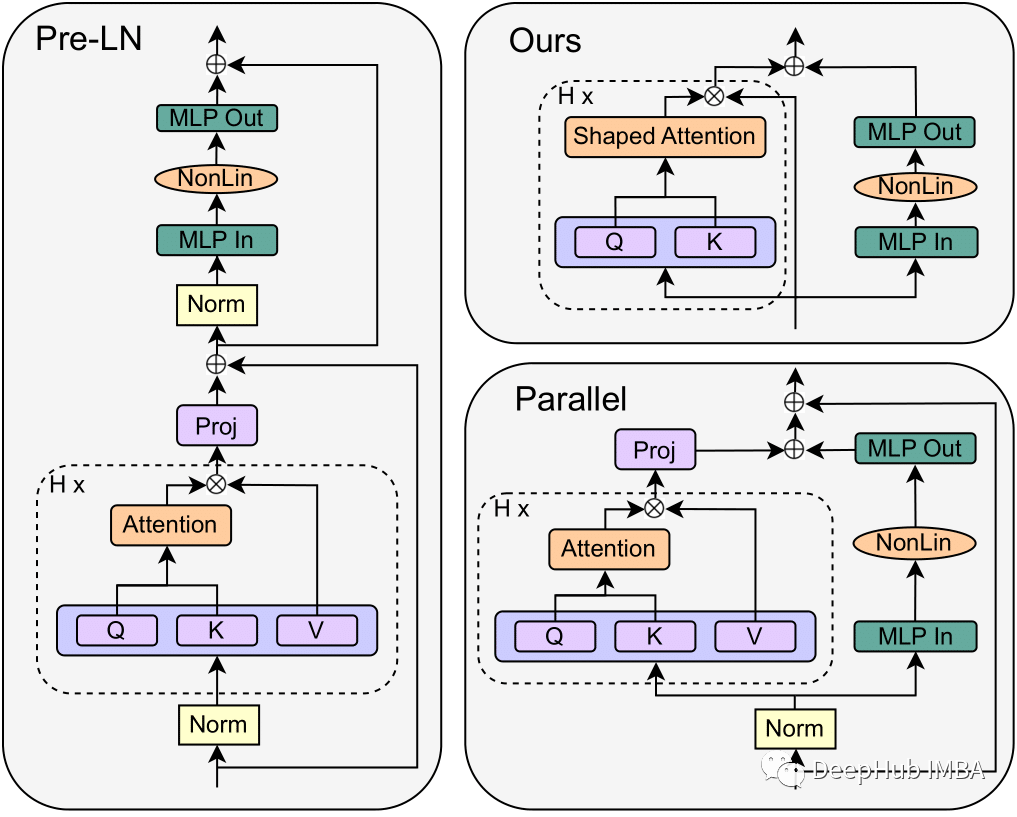
简化版Transformer :Simplifying Transformer Block论文详解
在这篇文章中我将深入探讨来自苏黎世联邦理工学院计算机科学系的Bobby He和Thomas Hofmann在他们的论文“Simplifying Transformer Blocks”中介绍的Transformer技术的进化步骤。这是自Transformer 开始以来,我看到的最好的改进。
经典神经网络论文超详细解读(三)——GoogLeNet InceptionV1学习笔记(翻译+精读+代码复现)
GoogLeNet InceptionV1论文(Going deeper with convolutions)超详细解读。翻译+总结。文末有代码复现
什么是softmax
pytroch实现softmax, softmax的理论介绍和实现softmax代码的详细讲解
机器学习可解释性一(LIME)
对于机器学习的用户而言,模型的可解释性是一种较为主观的性质,我们无法通过严谨的数学表达方法形式化定义可解释性。通常,我们可以认为机器学习的可解释性刻画了“人类对模型决策或预测结果的理解程度”,即用户可以更容易地理解解释性较高的模型做出的决策和预测。从哲学的角度来说,为了理解何为机器学习的可解释性,我



