
实验原理
LDA(Linear Discriminant Analysis)线性判别分析是一种监督学习的线性分类算法,它可以将一个样本映射到一条直线上,从而实现对样本的分类。LDA的目标是找到一个投影轴,使得经过投影后的两类样本之间的距离最大,而同一类样本之间的距离最小。
LDA的过程可以分为以下几步:
1.计算每个类别的均值向量。
2.计算类内散度矩阵(Within-class scatter matrix)。类内散度矩阵是各类别中所有样本与各自均值向量之差的协方差矩阵之和。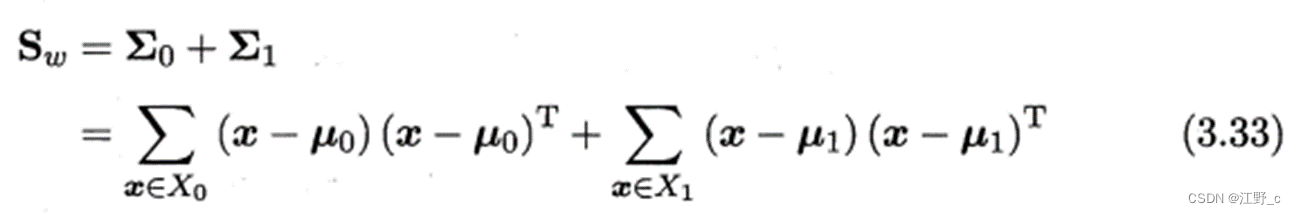
3.计算类间散度矩阵(Between-class scatter matrix)。类间散度矩阵是各类别均值向量之差的协方差矩阵。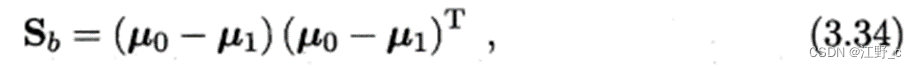
4.通过对类内散度矩阵进行奇异值分解,得到类内散度矩阵的逆矩阵。
5.计算投影向量w。通过将类间散度矩阵与类内散度矩阵的逆矩阵相乘,得到投影向量w,使得样本经过投影后不同类别之间的距离最大。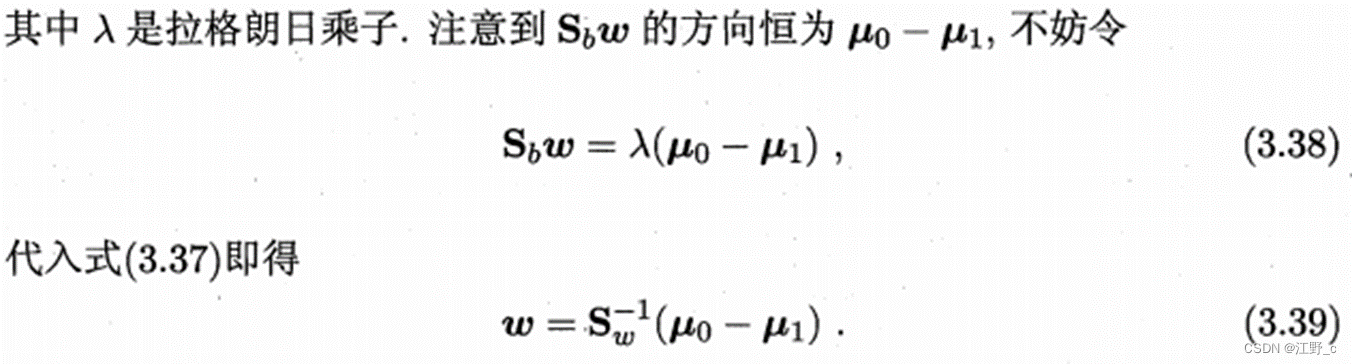
6.通过计算样本与投影向量w的点积,将样本映射到一条直线上。
7.根据映射后的样本值进行分类。
实验目的
本实验旨在使用线性判别分析(LDA)来对数据集进行分类,通过划分训练集和测试集,训练模型并得出模型的投影方向,进而计算测试集的准确率acc。同时,希望能够通过可视化方式展示数据的分析结果,从而更好地理解数据集的特征和模型分类的结果。
实验内容
- 划分数据集
index = random.sample(range(748), 748)train = df.iloc[index[:600], :]train = np.array(train)test = df.iloc[index[600:], :]test = np.array(test)- **random.sample(range(748), 748)**:生成一个长度为748的随机数列,其中包含了0~747之间的所有整数,且每个整数在数列中仅出现一次。- **train = df.iloc[index[:600], :]**:从数据集df中,根据前600个随机数的下标,选出对应的行作为训练集train。- **train = np.array(train)**:将训练集转换成numpy数组类型。- **test = df.iloc[index[600:], :]**:从数据集df中,根据从第601个随机数开始到最后一个随机数的下标,选出对应的行作为测试集test。- **test = np.array(test)**:将测试集转换成numpy数组类型。 - 定义计算类内散度矩阵
def cov(self, X, Y=None): # X = (X - np.mean(X, axis=0)) / np.std(X, axis=0) X = X - np.mean(X, axis=0) return np.dot(X.T, X) - 计算
w``````def fit(self, X): x0 = X[X[:, -1] == 0] x0 = x0[:, :-1] x1 = X[X[:, -1] == 1] x1 = x1[:, :-1] sigma0 = self.cov(x0) sigma1 = self.cov(x1) Sw = sigma1 + sigma0 # 求均值差 u0, u1 = np.mean(x0, axis=0), np.mean(x1, axis=0) mean_diff = u0 - u1 # 奇异值分解的方法 # 对类内散度矩阵进行奇异值分解 U, S, V = np.linalg.svd(Sw) # # # # 计算类内散度矩阵的逆 Sw_ = np.dot(np.dot(V.T, np.linalg.pinv(np.diag(S))), U.T) # # # # 计算w self.w = Sw_.dot(mean_diff)在代码中,首先根据标签将数据集分为两类,然后计算每个类别的协方差矩阵sigma0和sigma1,将它们相加得到总的类内散度矩阵Sw。接着计算两个类别的均值差mean_diff。为了得到最优的投影方向w,需要计算Sw的逆矩阵,然后将其乘以mean_diff得到w。这里使用了奇异值分解的方法计算Sw的逆矩阵。最终,训练得到的模型中包含了投影方向w,可以用于将新的数据点映射到低维空间中进行分类。 - 得到投影
def getY(self, X): res = [] for i in range(X.shape[0]): item = X[i, :].dot(self.w.T) res.append(item) return res- 函数名为 **getY**,接受一个参数 **X**,表示要对其进行预测的数据集,类型为 Numpy 数组。- 在函数内部,首先创建一个空列表 **res**,用于保存预测结果。- 然后,通过一个for循环遍历数据集X的每一行。- 对于每一行,调用训练好的模型的权重向量 **self.w**,计算其与该行数据的点积(即内积),得到一个标量值,表示该行数据的投影结果。将该值添加到res列表中。- 最后,函数返回res列表,其中保存了对每个数据样本的预测结果。 - 预测
def predict(self, x): res = [] # x = (x - np.mean(x, axis=0)) / np.std(x, axis=0) for i in range(x.shape[0]): item = x[i, :].dot(self.w.T) res.append(int(1 * (item < 0))) return res对于每个输入的样本x,通过将其投影到已学习的线性判别函数(通过线性判别分析得到的投影方向w)上,得到其在这个方向上的分量。如果分量小于0,就认为其属于类别0,否则属于类别1。这里将bool类型的结果通过int()函数转换成0或1来表示所属的类别。最终返回一个预测类别的列表。 - 选取最优参数应用于测试集
for i in range(100): # 划分训练集和测试集 index = random.sample(range(748), 748) train = df.iloc[index[:600], :] train = np.array(train) test = df.iloc[index[600:], :] test = np.array(test) # 拟合训练 lda = LDA() try: lda.fit(train) except: print("无法求逆") continue # 测试集测试 predata = lda.predict(test[:, :-1]) acc = (test[predata == test[:, -1]]).shape[0] / test.shape[0] # print(acc) res.append(acc) wlist.append(lda.w) print("最佳准确率:", max(res), '\t', "最低准确率:", min(res), '\t', "平均准确率:", np.mean(res)) print(res.index(max(res))) lda2 = LDA() lda2.w = wlist[res.index(max(res))] index = random.sample(range(748), 748) test = df.iloc[index[600:], :] test = np.array(test) res = lda2.getY(test[:, :-1]) predata = lda.predict(test[:, :-1]) acc = (test[predata == test[:, -1]]).shape[0] / test.shape[0] print("测试集准确率为:", acc)1. 对数据集进行100次随机划分,每次划分将前600个样本作为训练集,后148个样本作为测试集;2. 对每次划分后的训练集进行线性判别分析拟合;3. 使用拟合的模型对测试集进行预测,并计算测试集准确率;4. 记录每次测试的准确率和投影方向 w;5. 打印最佳准确率、最低准确率、平均准确率,并输出最佳准确率对应的投影方向;6. 选取最佳准确率对应的投影方向,使用该模型对另一个随机划分的测试集进行预测,并计算准确率。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JRUvjQMw-1680400273008)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/1ebdd3ea-7041-46f7-be6e-2ad4d249305c/Untitled.png)]](https://img-blog.csdnimg.cn/0f912f9917194479ad135a4ae9f05552.png)
- 将结果可视化
low0 = [i for i in res if i < 0] up0 = [i for i in res if i > 0] plt.scatter(low0, low0) plt.scatter(up0, up0) plt.show()![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ssw25FKj-1680400169633)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/116268e5-83e1-4919-b08c-aab2c348ac6e/Untitled.png)]](https://img-blog.csdnimg.cn/e9430238a24a44cca2853d73bb4a029e.png)
完整代码
import random
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
classLDA():
def __init__(self):
# 初始化权重矩阵
self.w = None
# 计算类内散度矩阵
def cov(self,X,Y=None):
# X=(X- np.mean(X, axis=0))/ np.std(X, axis=0)X=X- np.mean(X, axis=0)return np.dot(X.T,X)
# 得到投影
def getY(self,X):
res =[]for i inrange(X.shape[0]):
item =X[i,:].dot(self.w.T)
res.append(item)return res
# 计算W
def fit(self,X):
x0 =X[X[:,-1]==0]
x0 = x0[:,:-1]
x1 =X[X[:,-1]==1]
x1 = x1[:,:-1]
sigma0 = self.cov(x0)
sigma1 = self.cov(x1)
Sw = sigma1 + sigma0
# 求均值差
u0, u1 = np.mean(x0, axis=0), np.mean(x1, axis=0)
mean_diff = u0 - u1
# 奇异值分解的方法
# 对类内散度矩阵进行奇异值分解
U,S,V= np.linalg.svd(Sw)
# # # # 计算类内散度矩阵的逆
Sw_ = np.dot(np.dot(V.T, np.linalg.pinv(np.diag(S))),U.T)
# # # # 计算w
self.w = Sw_.dot(mean_diff)
# 直接矩阵求逆的方法
Sw = np.mat(Sw)
# self.w = Sw.I.dot(mean_diff)
# 预测
def predict(self, x):
res =[]
# x =(x - np.mean(x, axis=0))/ np.std(x, axis=0)for i inrange(x.shape[0]):
item = x[i,:].dot(self.w.T)
res.append(int(1*(item <0)))return res
if __name__ =='__main__':
df = pd.read_csv('./data/blood_data.txt', header=None, index_col=None)
res =[]
wlist =[]
# 进行100轮训练,选取最优的参数
for i inrange(100):
# 划分训练集和测试集
index = random.sample(range(748),748)
train = df.iloc[index[:600],:]
train = np.array(train)
test = df.iloc[index[600:],:]
test = np.array(test)
# 拟合训练
lda =LDA()try:
lda.fit(train)except:print("无法求逆")continue
# 测试集测试
predata = lda.predict(test[:,:-1])
acc =(test[predata == test[:,-1]]).shape[0]/ test.shape[0]
# print(acc)
res.append(acc)
wlist.append(lda.w)print("最佳准确率:",max(res),'\t',"最低准确率:",min(res),'\t',"平均准确率:", np.mean(res))print(res.index(max(res)))
lda2 =LDA()
lda2.w = wlist[res.index(max(res))]
index = random.sample(range(748),748)
test = df.iloc[index[600:],:]
test = np.array(test)
res = lda2.getY(test[:,:-1])
predata = lda.predict(test[:,:-1])
acc =(test[predata == test[:,-1]]).shape[0]/ test.shape[0]print("测试集准确率为:", acc)
low0 =[i for i in res if i <0]
up0 =[i for i in res if i >0]
plt.scatter(low0, low0)
plt.scatter(up0, up0)
plt.show()
本文转载自: https://blog.csdn.net/qq_51544319/article/details/129908953
版权归原作者 江野_c 所有, 如有侵权,请联系我们删除。
版权归原作者 江野_c 所有, 如有侵权,请联系我们删除。