基于VGG16的猫狗分类实战
基于VGG16的猫狗分类实战
基于Transformer的多变量风电功率预测TF2
Transformer目前大火,作为一个合格的算法搬运工自然要跟上潮流,本文基于tensorflow2框架,构建transformer模型,并将其用于多变量的风电功率负荷预测。实验结果表明,相比与传统的LSTM,该方法精度更高,缺点也很明显,该方法需要更多的数据训练效果才能超过传统方法,而且占用很高
深度学习之路:自动驾驶沙盘与人工智能专业的完美融合
探寻未来交通的深度学习之路,本文以“深度学习之路:自动驾驶沙盘与人工智能专业的完美融合”为题,详细解析了自动驾驶沙盘在人工智能专业教学与科研中的突出意义。通过结合深度学习理论与实际应用,文章展示了小车的自动驾驶原理、传感器技术,以及图像识别红绿灯、车道线等关键功能的源码。强调自动驾驶沙盘作为高校科研
图像识别与分类:实战指南
在计算机视觉中,图像识别与分类的目标是根据图像内容将其分配给一个或多个类别。数据预处理:包括缩放、裁剪、翻转等操作,以增强图像数据的多样性。特征提取:从原始图像中提取有助于识别和分类的特征。模型训练:使用监督学习算法训练模型以区分不同类别。模型评估:使用一组测试数据评估模型的性能。应用模型:将训练好

人工智能生成文本检测在实践中使用有效性探讨
本文介绍了关于如何检测ai生成文本的思路。希望这有助于理解检测人工智能生成文本背后的细节。
【强化学习入门】二.强化学习的基本概念:状态、动作、智能体、策略、奖励、状态转移、轨迹、回报、价值函数
自动驾驶中,汽车就是智能体;机器人控制中,机器人就是智能体;超级玛丽游戏中,玛丽就是智能体。当智能体做出一个动作,状态会发生变化(从旧的状态变成新的状态)。我们就可以说状态发生的转移。的含义就是,根据观测到的状态,做出动作的方案,超级玛丽游戏中,观测到的这一帧画面就是一个。强化学习的目标就是尽可能的
深度学习基础实例与总结
感知机(Perceptron),又称神经元(Neuron,对生物神经元进行了模仿)是神经网络(深度学习)的起源管法,1958年由康奈尔大学心理学教授弗兰克·罗森布拉特(Frank Rosenblatt) 提出,它可以接收多个输入信号,产生一个输出信号。其中,x1ix_1ix1i和x2x_2x2称
T5模型:打破Few-shot Learning的次元壁垒
自然语言处理(NLP)是一种用于理解人类语言的计算机科学领域。在过去的几年中,随着深度学习技术的发展,NLP领域也取得了突破性进展。在众多的NLP模型中,T5模型作为一种强大的语言生成模型,在自然语言理解、翻译和问答等任务中表现出色,成为了该领域的研究热点之一。本文将介绍T5模型的原理和优势,并结合
【图像分割】Unet系列深度讲解(FCN、UNET、UNET++)
【图像分割】Unet系列深度讲解(FCN、UNET、UNET++)
BP神经网络模型一篇入门
BP神经网络广泛应用于解决各种问题,是知名度极高的模型之一为了方便初学者快速学习,本文进行深入浅出讲解BP神经网络的基本知识通过本文,可以初步了解BP神经网络的各个核心要素,并弄清BP神经网络是什么。
【DL】第 2 章 :变分自动编码器(VAE)
在本章中,您将:了解自动编码器的架构设计如何使其完美适用于生成建模使用 Keras 从头开始构建和训练自动编码器使用自动编码器生成新图像,但了解这种方法的局限性了解变分自动编码器的架构以及它如何解决与标准自动编码器相关的许多问题使用 Keras 从头开始构建变分自动编码器使用变分自动编码器生成新图像

2023年小型计算机视觉总结
到2023年底,人工智能领域迎来了生成式人工智能的新成功:大型语言模型(llm)和图像生成模型。每个人都在谈论它,它们对小型计算机视觉应用有什么改变吗?
人脸识别 Face Recognition 入门
找论文搭配 Sci-Hub 食用更佳 💪Sci-Hub 实时更新 : https://tool.yovisun.com/scihub/公益科研通文献求助:https://www.ablesci.com/人脸识别流程:检测、对齐、(活体)、预处理、提取特征(表示)、人脸识别(验证)传统方法试图通过一
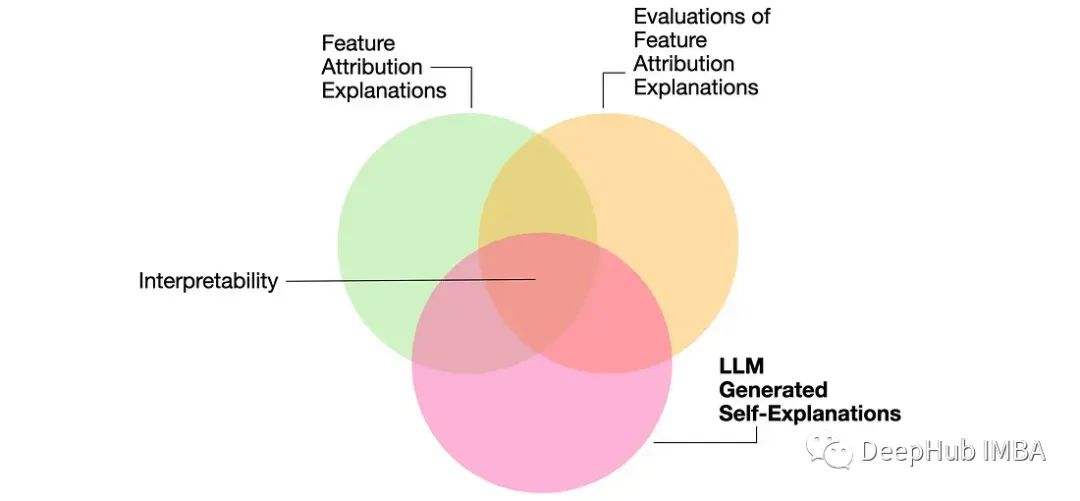
论文推荐:大型语言模型能自我解释吗?
这篇论文的研究主要贡献是对LLM生成解释的优缺点进行了调查。详细介绍了两种方法,一种是做出预测,然后解释它,另一种是产生解释,然后用它来做出预测。
人工智能、机器学习、深度学习之间的关系是什么?
人工智能(Artificial Intelligence,AI)是指通过计算机技术来实现人类的智能行为和智能思维的一种技术手段。它的传统研究方向是从人类的智能角度出发,通过模拟和实现人类的智能能力,比如语言理解、图像识别、推理、决策等。而机器学习则是人工智能的一个重要分支,是指计算机通过学习数据和样
PaDiM 原理与代码解析
文中使用马氏距离 \(M(x_{ij})\) 来计算测试图片在位置 \((i,j)\) 处的异常分数,\(M(x_{ij})\) 表示测试图片的嵌入向量 \(x_{ij}\) 和学习到的分布 \(\mathcal N(\mu_{ij},{\textstyle \sum_{ij}^{}} )\) 之
MAMBA介绍:一种新的可能超过Transformer的AI架构
屹立不倒的 Transformer 迎来了一个强劲竞争者。CMU、普林斯顿研究者发布的MAMBA架构,解决了Transformer核心注意力层无法扩展的致命bug,推理速度直接飙升了5倍!一个时代终于要结束了?
AI生成中Transformer模型
在深度学习中,有很多需要处理时序数据的任务,比如语音识别、文本理解、机器翻译、音乐生成等。Transformer模型由Vaswani等人在2017年的论文《Attention Is All You Need》中首次提出,它在自然语言处理领域引起了巨大变革。该模型摒弃了传统的循环网络结构,转而使用自注
一维pytorch注意力机制
最近在研究一维数据,发现目前网络上的注意力机制都是基于二维来构建的,对于一维的,没有查到什么可直接加在网络中的代码,因此本次文章主要介绍常用的三种注意力机制–SENet,CBAM和ECA其一维的代码。
一文总结经典卷积神经网络CNN模型
总结从1998年至今的优秀CNN模型,包括LeNet、AlexNet、ZFNet、VGG、GoogLeNet、ResNet、DenseNet、SENet、SqueezeNet、MobileNet。了解巨佬们的智慧结晶,学习算法上的思路和技巧,便于我们自己构建模型,也便于我们做迁移学习。



