
目录
本教程主要讲解,如何在CPU平台上,使用MindSpore进行数据并行分布式训练,以提高训练效率。
完整的样例代码:distributed_training_cpu
目录结构如下:
bash └─sample_code ├─distributed_training_cpu │ resnet.py │ resnet50_distributed_training.py │ run.sh
其中,resnet.py和resnet50_distributed_training.py是训练网络定义脚本,run.sh是分布式训练执行脚本。
如果你对MindSpore感兴趣,可以关注昇思MindSpore社区
一、环境准备
1.进入ModelArts官网
云平台帮助用户快速创建和部署模型,管理全周期AI工作流,选择下面的云平台以开始使用昇思MindSpore,获取安装命令,安装MindSpore2.0.0-alpha版本,可以在昇思教程中进入ModelArts官网
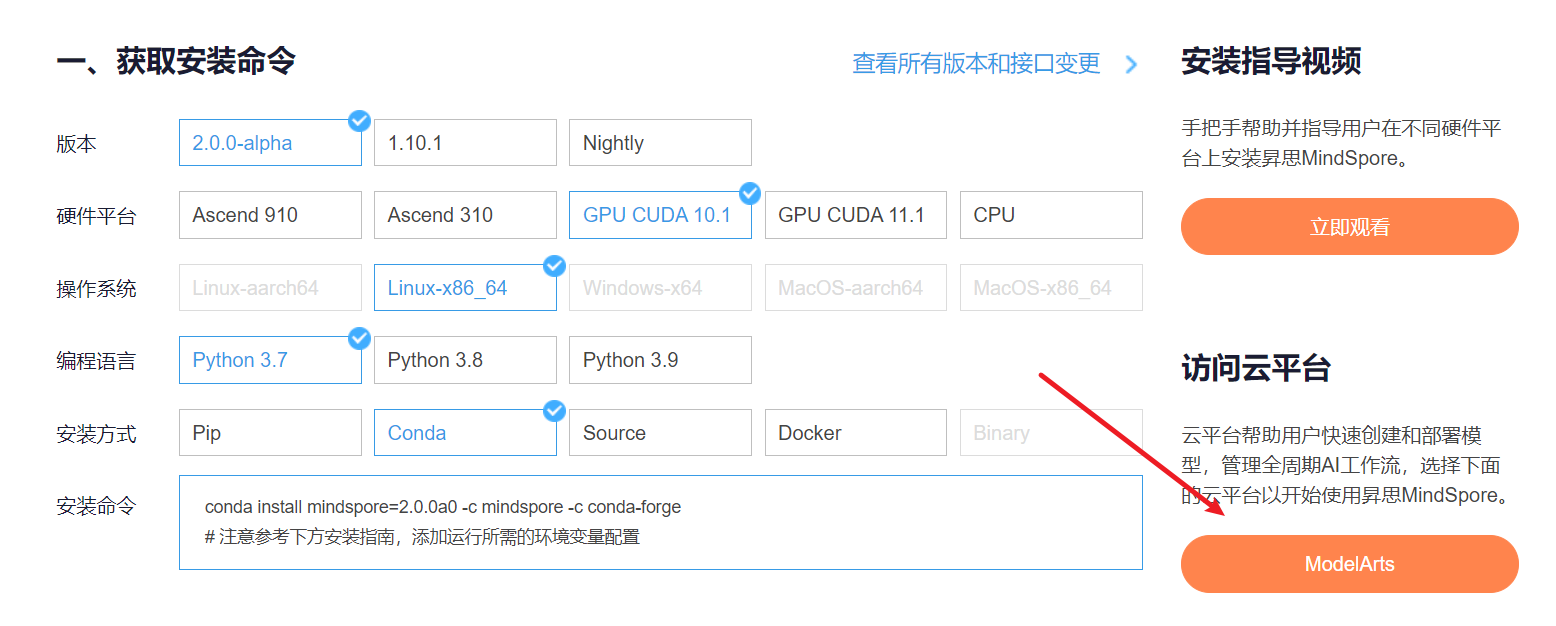
选择下方CodeLab立即体验
等待环境搭建完成
2.使用ModelArts体验实例
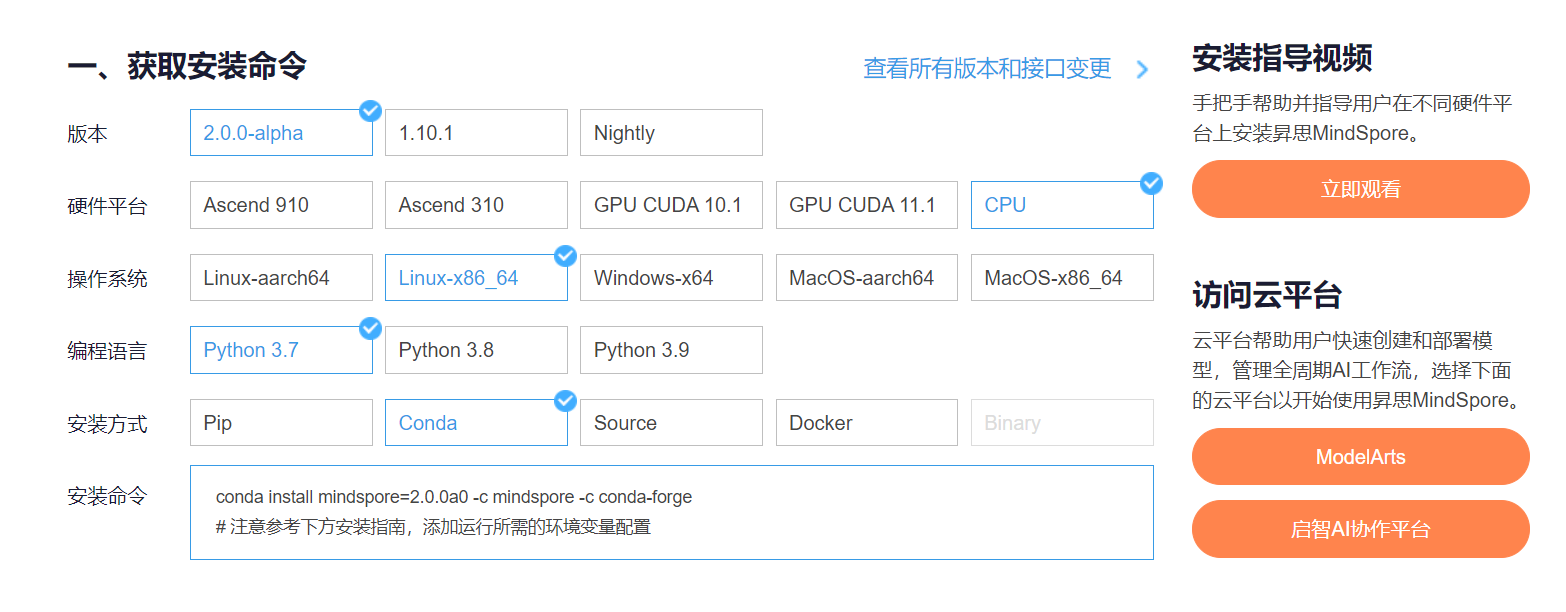
进入昇思MindSpore官网,点击上方的安装

获取安装命令
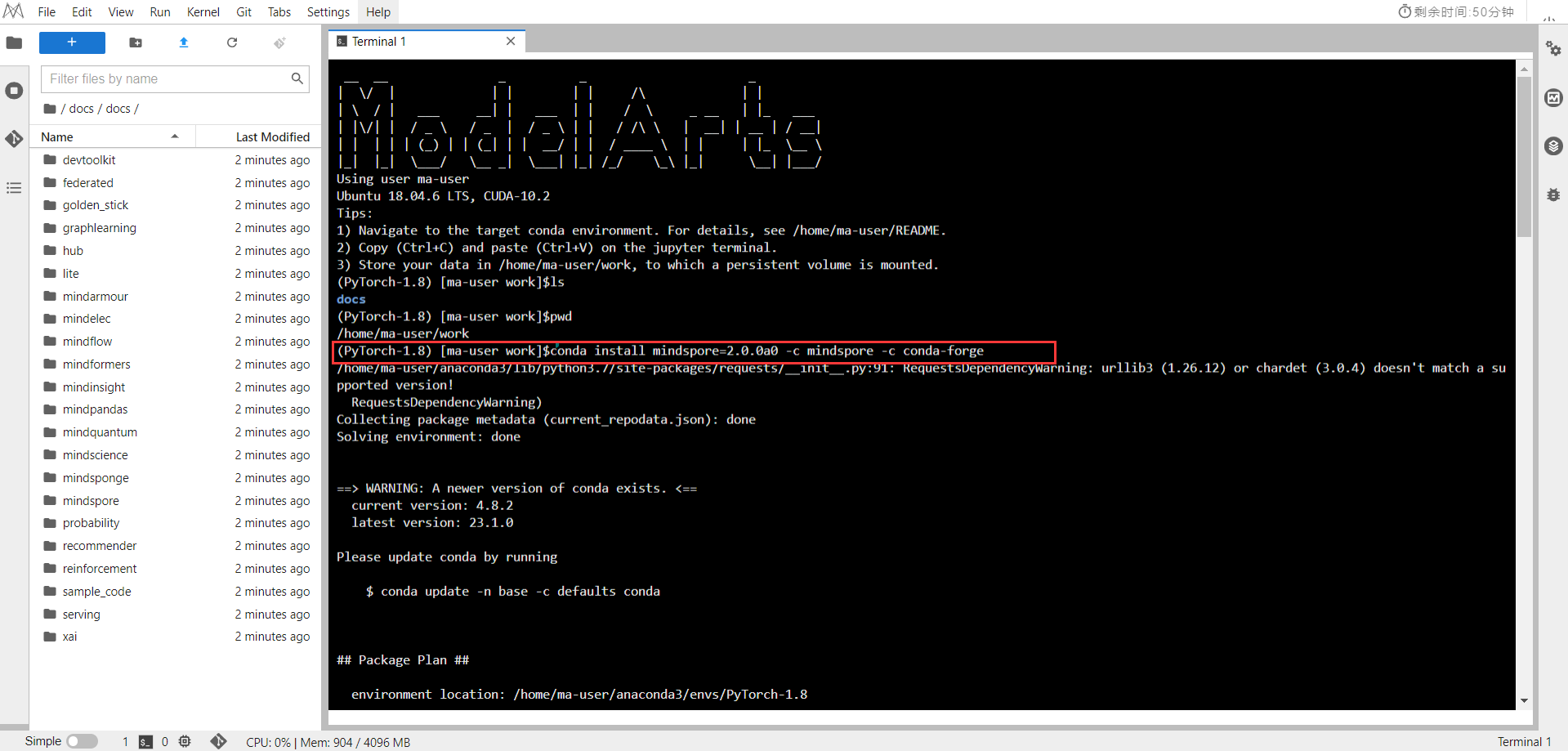
在ModelArts中打开一个Terminal,输入安装命令
conda installmindspore=2.0.0a0 -c mindspore -c conda-forge
再点击侧边栏中的Clone a Repository,输入
https://gitee.com/mindspore/docs.git
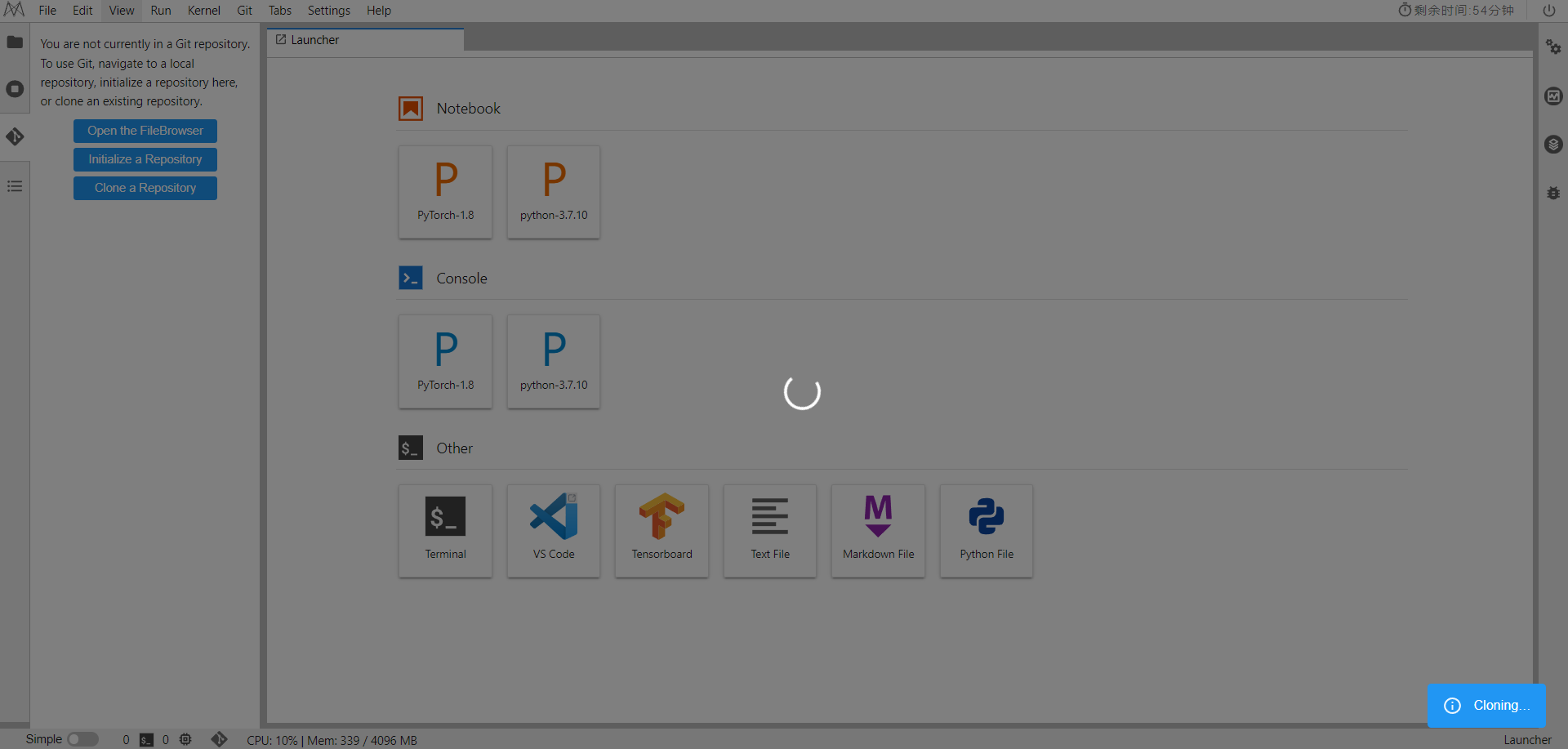
可以看到docs项目导入成功
二、准备环节
1.下载数据集
本样例采用CIFAR-10数据集,由10类32*32的彩色图片组成,每类包含6000张图片,其中训练集共50000张图片,测试集共10000张图片。
将下载的数据集上传到,解压后文件夹为
cifar-10-batches-bin
。
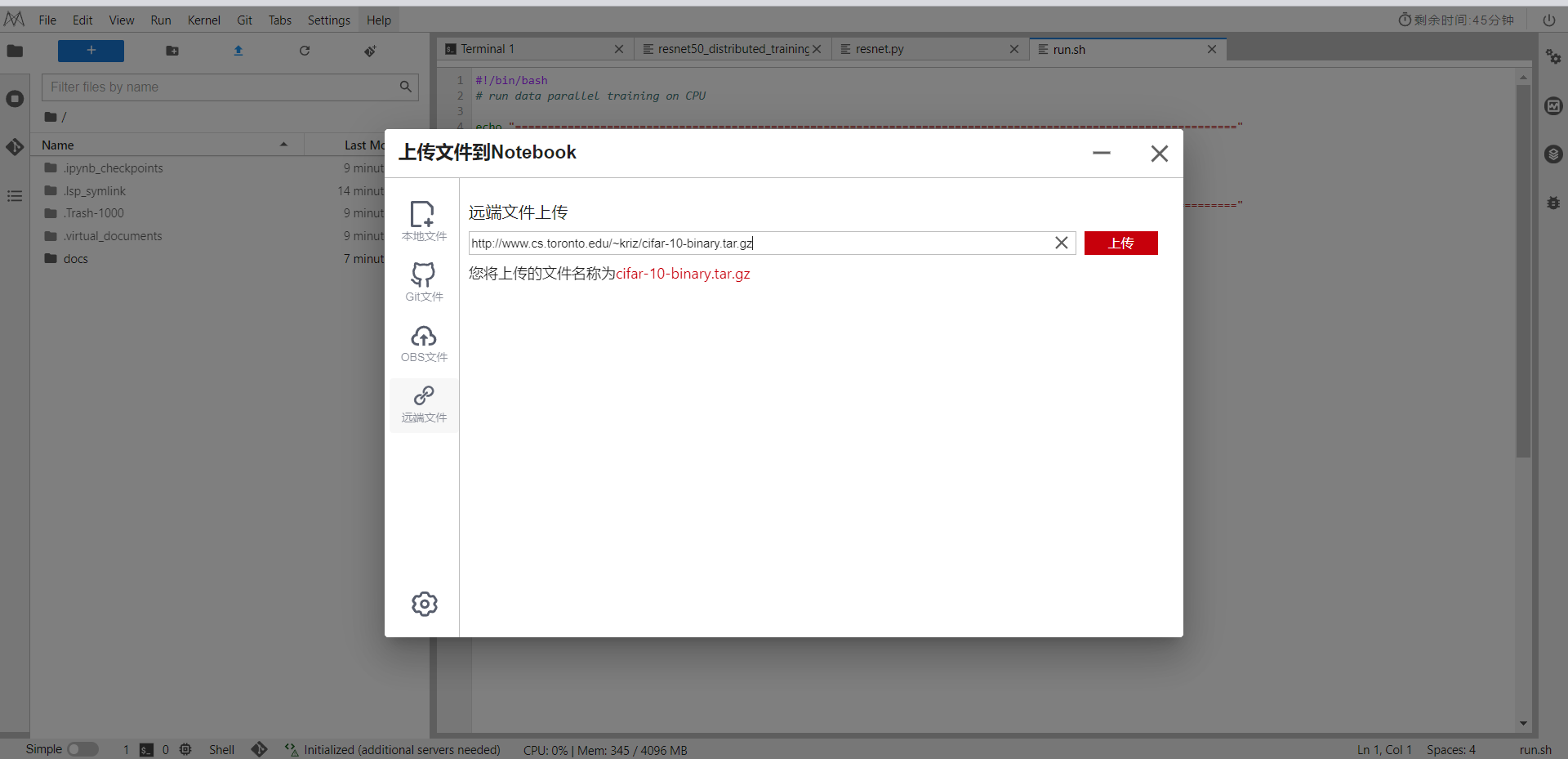
tar -zxvf cifar-10-binary.tar.gz

注意:如果你使用的是ModelArts,接下来介绍内容都无需配置,可以跳到 五、启动训练,直接开始训练模型
2.配置分布式环境
CPU上数据并行主要分为单机多节点和多机多节点两种并行方式(一个训练进程可以理解为一个节点)。在运行训练脚本前,需要搭建组网环境,主要是环境变量配置和训练脚本里初始化接口的调用。
环境变量配置如下:
exportMS_WORKER_NUM=8# Worker numberexportMS_SCHED_HOST=127.0.0.1 # Scheduler IP addressexportMS_SCHED_PORT=6667# Scheduler portexportMS_ROLE=MS_WORKER # The role of this node: MS_SCHED represents the scheduler, MS_WORKER represents the worker
其中,
- MS_WORKER_NUM:表示worker节点数,多机场景下,worker节点数是每机worker节点之和。
- MS_SCHED_HOST:表示scheduler节点ip地址。
- MS_SCHED_PORT:表示scheduler节点服务端口,用于接收worker节点发送来的ip和服务端口,然后将收集到的所有worker节点ip和端口下发给每个worker。
- MS_ROLE:表示节点类型,分为worker(MS_WORKER)和scheduler(MS_SCHED)两种。不管是单机多节点还是多机多节点,都需要配置一个scheduler节点用于组网。
训练脚本里初始化接口调用如下:
import mindspore as ms
from mindspore.communication import init
ms.set_context(mode=ms.GRAPH_MODE, device_target="CPU")
ms.set_auto_parallel_context(parallel_mode=ms.ParallelMode.DATA_PARALLEL, gradients_mean=True)
ms.set_ps_context(enable_ssl=False)
init()
其中,
- ms.set_context(mode=context.GRAPH_MODE, device_target=“CPU”):指定模式为图模式(CPU上PyNative模式下不支持并行),设备为CPU。
- ms.set_auto_parallel_context(parallel_mode=ParallelMode.DATA_PARALLEL, gradients_mean=True):指定数据并行模式,gradients_mean=True表示梯度归约后会进行一个求平均,当前CPU上梯度归约仅支持求和。
- ms.set_ps_context:配置安全加密通信,可通过ms.set_ps_context(enable_ssl=True)开启安全加密通信,默认为False,关闭安全加密通信。
- init:节点初始化,初始化完成表示组网成功。
三、加载数据集
分布式训练时,数据集是以数据并行的方式导入的。下面我们以CIFAR-10数据集为例,介绍以数据并行方式导入CIFAR-10数据集的方法,data_path是指数据集的路径,即cifar-10-batches-bin文件夹的路径。
样例代码如下
import mindspore as ms
import mindspore.dataset as ds
import mindspore.dataset.vision as vision
import mindspore.dataset.transforms as transforms
from mindspore.communication import get_rank, get_group_size
def create_dataset(data_path, repeat_num=1, batch_size=32):
"""Create training dataset"""
resize_height =224
resize_width =224
rescale =1.0 / 255.0shift=0.0# get rank_id and rank_size
rank_size = get_group_size()
rank_id = get_rank()
data_set = ds.Cifar10Dataset(data_path, num_shards=rank_size, shard_id=rank_id)# define map operations
random_crop_op = vision.RandomCrop((32,32),(4,4,4,4))
random_horizontal_op = vision.RandomHorizontalFlip()
resize_op = vision.Resize((resize_height, resize_width))
rescale_op = vision.Rescale(rescale, shift)
normalize_op = vision.Normalize((0.4465,0.4822,0.4914),(0.2010,0.1994,0.2023))
changeswap_op = vision.HWC2CHW()
type_cast_op = transforms.TypeCast(ms.int32)
c_trans =[random_crop_op, random_horizontal_op]
c_trans +=[resize_op, rescale_op, normalize_op, changeswap_op]# apply map operations on images
data_set = data_set.map(operations=type_cast_op, input_columns="label")
data_set = data_set.map(operations=c_trans, input_columns="image")# apply shuffle operations
data_set = data_set.shuffle(buffer_size=10)# apply batch operations
data_set = data_set.batch(batch_size=batch_size, drop_remainder=True)# apply repeat operations
data_set = data_set.repeat(repeat_num)return data_set
与单机不同的是,在构造Cifar10Dataset时需要传入num_shards和shard_id参数,分别对应worker节点数和逻辑序号,可通过框架接口获取,如下:
- get_group_size:获取集群中worker节点数。
- get_rank:获取当前worker节点在集群中的逻辑序号。
数据并行模式加载数据集时,建议对每卡指定相同的数据集文件,若是各卡加载的数据集不同,可能会影响计算精度。
四、定义模型
数据并行模式下,网络定义与单机写法一致,可参考ResNet网络样例脚本。
优化器、损失函数及训练模型定义可参考训练模型定义。
完整训练脚本代码参考样例,下面列出训练启动代码。
import os
import mindspore as ms
import mindspore.nn as nn
from mindspore import train
from mindspore.communication import init
from resnet import resnet50
def train_resnet50_with_cifar10(epoch_size=10):
"""Start the training"""
loss_cb = train.LossMonitor()
data_path = os.getenv('DATA_PATH')
dataset = create_dataset(data_path)
batch_size =32
num_classes =10
net = resnet50(batch_size, num_classes)
loss = SoftmaxCrossEntropyExpand(sparse=True)
opt = nn.Momentum(filter(lambda x: x.requires_grad, net.get_parameters()), 0.01, 0.9)
model = ms.Model(net, loss_fn=loss, optimizer=opt)
model.train(epoch_size, dataset, callbacks=[loss_cb], dataset_sink_mode=True)if __name__ =="__main__":
ms.set_context(mode=ms.GRAPH_MODE, device_target="CPU")
ms.set_auto_parallel_context(parallel_mode=ms.ParallelMode.DATA_PARALLEL, gradients_mean=True)
ms.set_ps_context(enable_ssl=False)
init()
train_resnet50_with_cifar10()
脚本里create_dataset和SoftmaxCrossEntropyExpand接口引用自distributed_training_cpu,
resnet50接口引用自ResNet网络样例脚本。
五、启动训练
在CPU平台上,以单机8节点为例,执行分布式训练。
进入到
/home/ma-user/work/docs/docs/sample_code/distributed_training_cpu
目录下

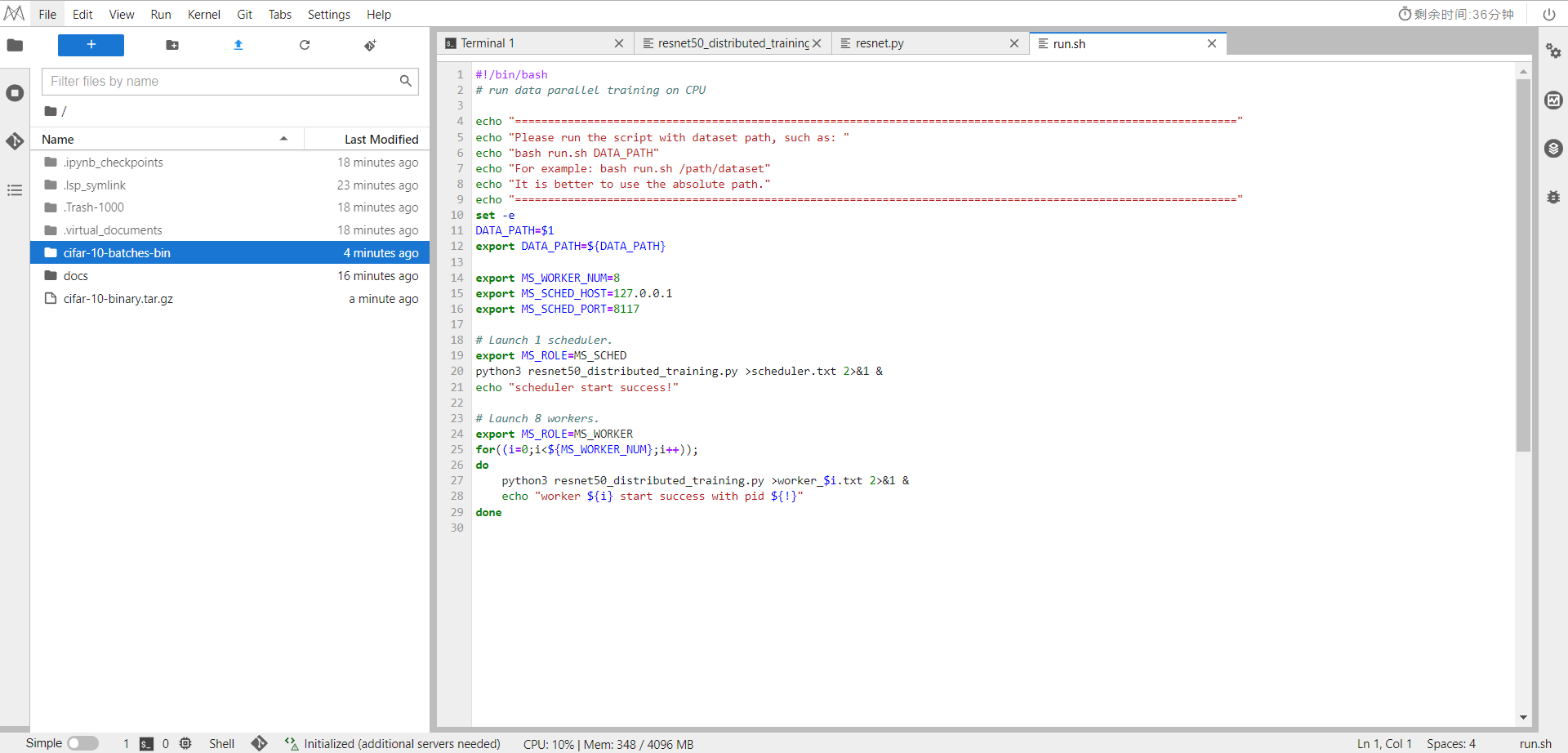
通过以下shell脚本启动训练,指令bash run.sh /dataset/cifar-10-batches-bin,可以看到已经训练成功了
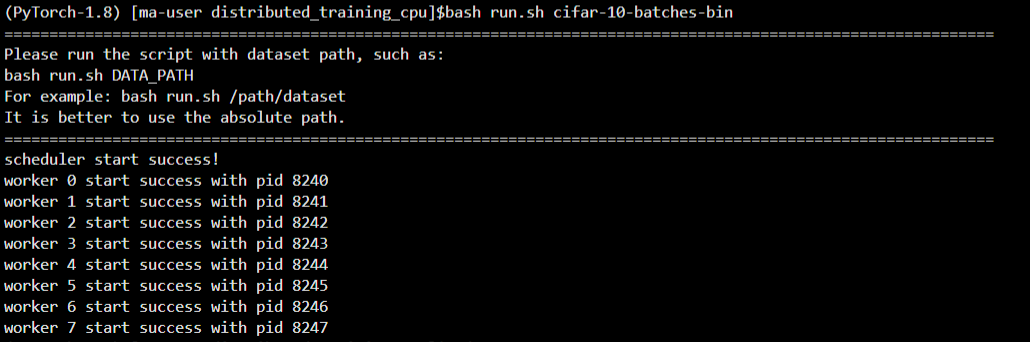
(PyTorch-1.8)[ma-user distributed_training_cpu]$bash run.sh cifar-10-batches-bin
==============================================================================================================
Please run the script with dataset path, such as:
bash run.sh DATA_PATH
For example: bash run.sh /path/dataset
It is better to use the absolute path.
==============================================================================================================
scheduler start success!
worker 0 start success with pid 8240
worker 1 start success with pid 8241
worker 2 start success with pid 8242
worker 3 start success with pid 8243
worker 4 start success with pid 8244
worker 5 start success with pid 8245
worker 6 start success with pid 8246
worker 7 start success with pid 8247
#!/bin/bash# run data parallel training on CPUecho"=============================================================================================================="echo"Please run the script with dataset path, such as: "echo"bash run.sh DATA_PATH"echo"For example: bash run.sh /path/dataset"echo"It is better to use the absolute path."echo"=============================================================================================================="set -e
DATA_PATH=$1exportDATA_PATH=${DATA_PATH}exportMS_WORKER_NUM=8exportMS_SCHED_HOST=127.0.0.1
exportMS_SCHED_PORT=8117# Launch 1 scheduler.exportMS_ROLE=MS_SCHED
python3 resnet50_distributed_training.py >scheduler.txt 2>&1&echo"scheduler start success!"# Launch 8 workers.exportMS_ROLE=MS_WORKER
for((i=0;i<${MS_WORKER_NUM};i++));do
python3 resnet50_distributed_training.py >worker_$i.txt 2>&1&echo"worker ${i} start success with pid ${!}"done
其中,resnet50_distributed_training.py为定义的训练脚本。
对于多机多节点场景,需要在每个机器上按照这种方式,启动相应的worker节点参与训练,但scheduler节点只有一个,只需要在其中一个机器上(即MS_SCHED_HOST)启动即可。
定义的MS_WORKER_NUM值,表示需要启动相应数量的worker节点参与训练,否则组网不成功。
虽然针对scheduler节点也启动了训练脚本,但scheduler主要用于组网,并不会参与训练。
训练一段时间,打开worker_0日志,训练信息如下:
(PyTorch-1.8)[ma-user distributed_training_cpu]$tail -f worker_0.txt
……
epoch: 1 step: 1, loss is 1.4686084
epoch: 1 step: 2, loss is 1.3278534
epoch: 1 step: 3, loss is 1.4246798
epoch: 1 step: 4, loss is 1.4920032
epoch: 1 step: 5, loss is 1.4324203
epoch: 1 step: 6, loss is 1.432581
epoch: 1 step: 7, loss is 1.319618
版权归原作者 Yeats_Liao 所有, 如有侵权,请联系我们删除。