GPU服务器安装显卡驱动、CUDA和cuDNN
gpu服务器中容器调用显卡运算
深度学习模型组件系列二:最常用的特征提取器
深度学习模型组件的特折提取器
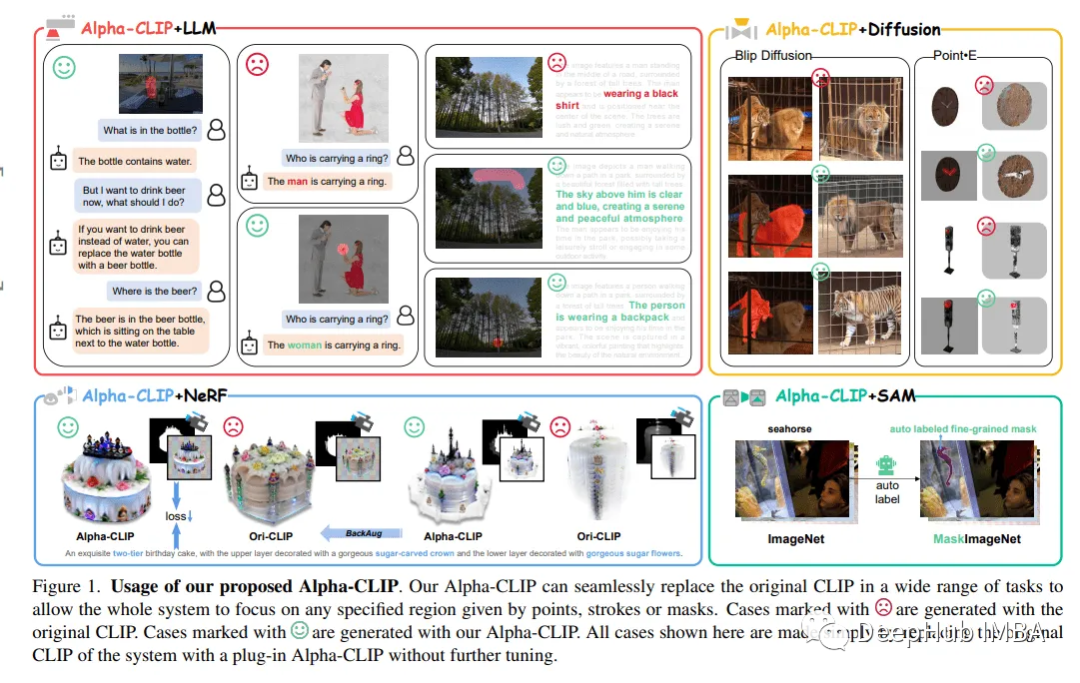
CLIP的升级版Alpha-CLIP:区域感知创新与精细控制
Alpha-CLIP不仅保留了CLIP的视觉识别能力,而且实现了对图像内容强调的精确控制,使其在各种下游任务中表现出色。
深度学习模型的参数、计算量和推理速度统计
在没有过拟合的情况下,相同模型结构下,一般模型的参数量和计算量与最终的性能成正比,在比较不同模型性能时,最好能保持模型参数量和计算量在相同水平下,因此相应参数的统计很重要。这里只进行理论计算,最终的效果(内存和速度)还和网络结构,代码实现方式、应用的平台性能等条件有关系,例如使用GEMM实现CNN时
Wav2Vec & HuBert 自监督语音识别模型
自监督预训练语言模型,wav2vec, wav2vec2.0,HUBert
AI:90-基于深度学习的自然灾害损害评估
基于深度学习的自然灾害损害评估自然灾害如地震、飓风、洪水和火灾常常带来严重的人员伤亡和财产损失。快速、准确的自然灾害损害评估对于有效的救援和恢复工作至关重要。在过去,这种评估通常是由人工进行的,费时费力且容易出错。然而,现代技术和深度学习的出现为自然灾害损害评估带来了全新的可能性。
水果分割论文、代码和数据集汇总
果园、分割、算法
经典神经网络论文超详细解读(六)——DenseNet学习笔记(翻译+精读+代码复现)
DenseNet论文(《Densely connected convolutional networks》)超详细解读。翻译+总结。文末有代码复现
目标检测评价指标
检测精度指标:IoU、TP、TN、FP、FN、查准率、查全率、F1-Score、ROC曲线、P-R曲线、AP、mAP以及MS COCO评价指标和PASCAL VOC的评价指标的理解;检测速度指标:FPS、FLOPS和FLOPs
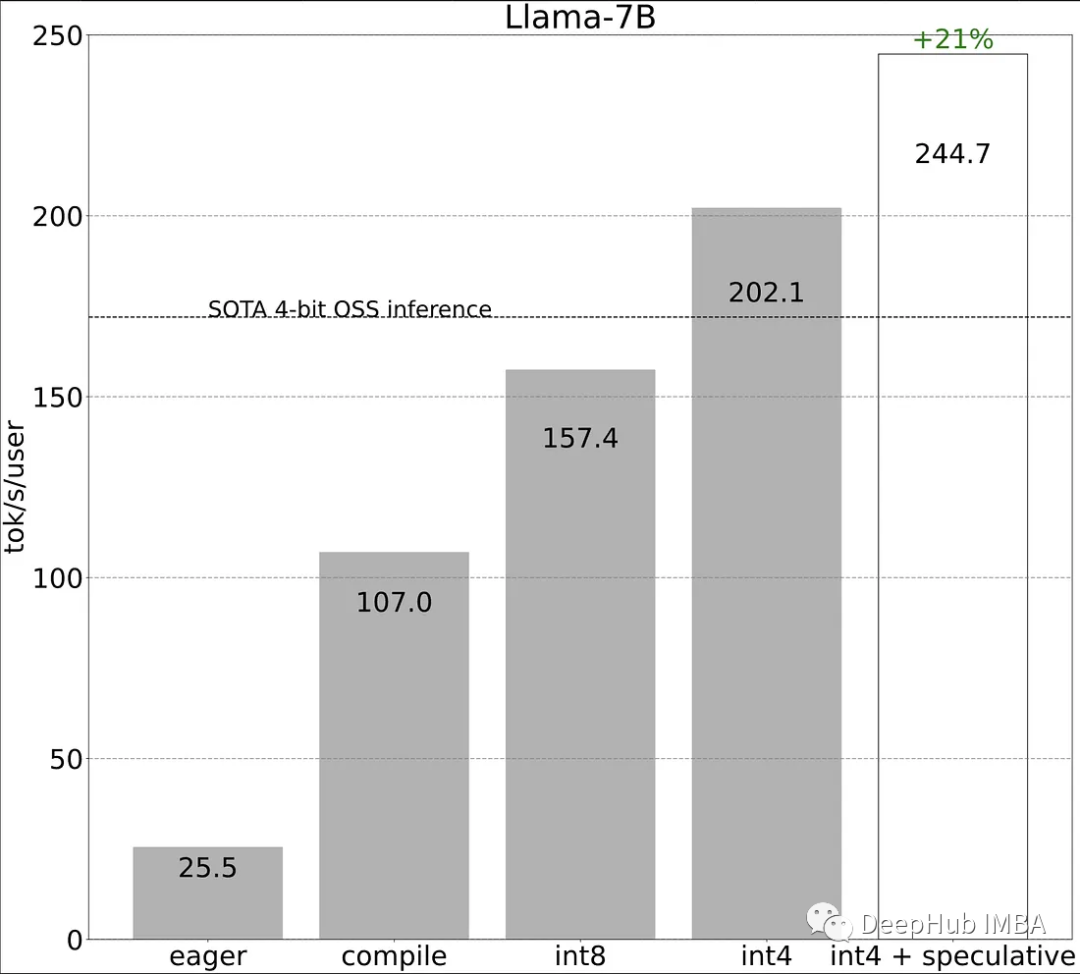
使用PyTorch II的新特性加快LLM推理速度
Pytorch团队提出了一种纯粹通过PyTorch新特性在的自下而上的优化LLM方法
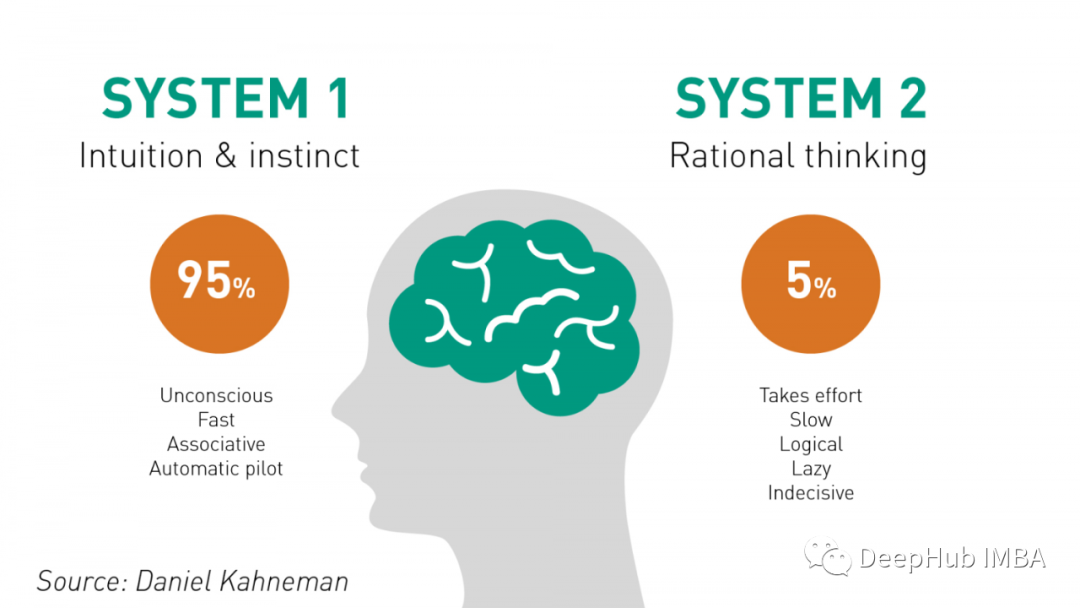
System 2 Attention:可以提高不同LLM问题的推理能力
S2A是LLM推理方法发展的一个重要里程碑。该方法与人类推理非常相似,避免了干扰。我们应该期待S2A在最近几个月成为推理研究的重要基线。
【边缘注意:深度多尺度特征】
仅供自己参考
【PyTorch】切记:GeForce RTX 3090 显卡仅支持 CUDA 11 以上的版本!
得知 PyTorch 1.7.0 开始才支持 CUDA 11,所以要使用 GPU 训练的话,必须安装 PyTorch 1.7.0 及以上版本。前不久给新来的 2台 8 张 GeForce RTX 3090 服务器配置了深度学习环境(配置教程参考。原来是 GeForce RTX 3090 显卡仅支持
Pytorch 中 expand和repeat
在中,如果要改变某一个tensor的维度,可以利用view、expand、repeat、transpose和permute等方法,这里对这些方法的一些容易混淆的地方做个总结。expand和repeat函数是pytorch中常用于进行张量数据复制和维度扩展的函数,但其工作机制差别很大,本文对这两个函
深度学习中的学习率设置技巧与实现详解
深度学习中的学习率是一个非常重要的超参数,对模型的训练和结果影响极大。在深度学习模型中,学习率决定了参数更新的步长,因此合理设置学习率对于优化算法的收敛速度、模型的训练效果以及泛化性能都有很大的影响。本文将介绍深度学习中的学习率设置技巧,包括常用的学习率衰减方法、自适应学习率方法以及学习率预热等。
Vit极简原理+pytorch代码
Vit比它爹Transformer步骤要简单的多,需要注意的点也要少得多,最令人兴奋的是它在代码中没有令人头疼的MASK,还有许多简化的操作,容我慢慢道来。
语义分割之RandLANet深度解读
语义分割任务是计算机视觉里的一个比较基础的任务,其相比于物体检测任务主要有以下几个优点:输出的结果是稠密的,是针对于所有像素点的K分类问题,物体检测任务只输出前景类物体的信息忽略了背景点的信息在自动驾驶任务中可以实现可行驶区域的识别,大部分区域都是以背景的形式存在,而这些背景同样是非行驶区域可以输出
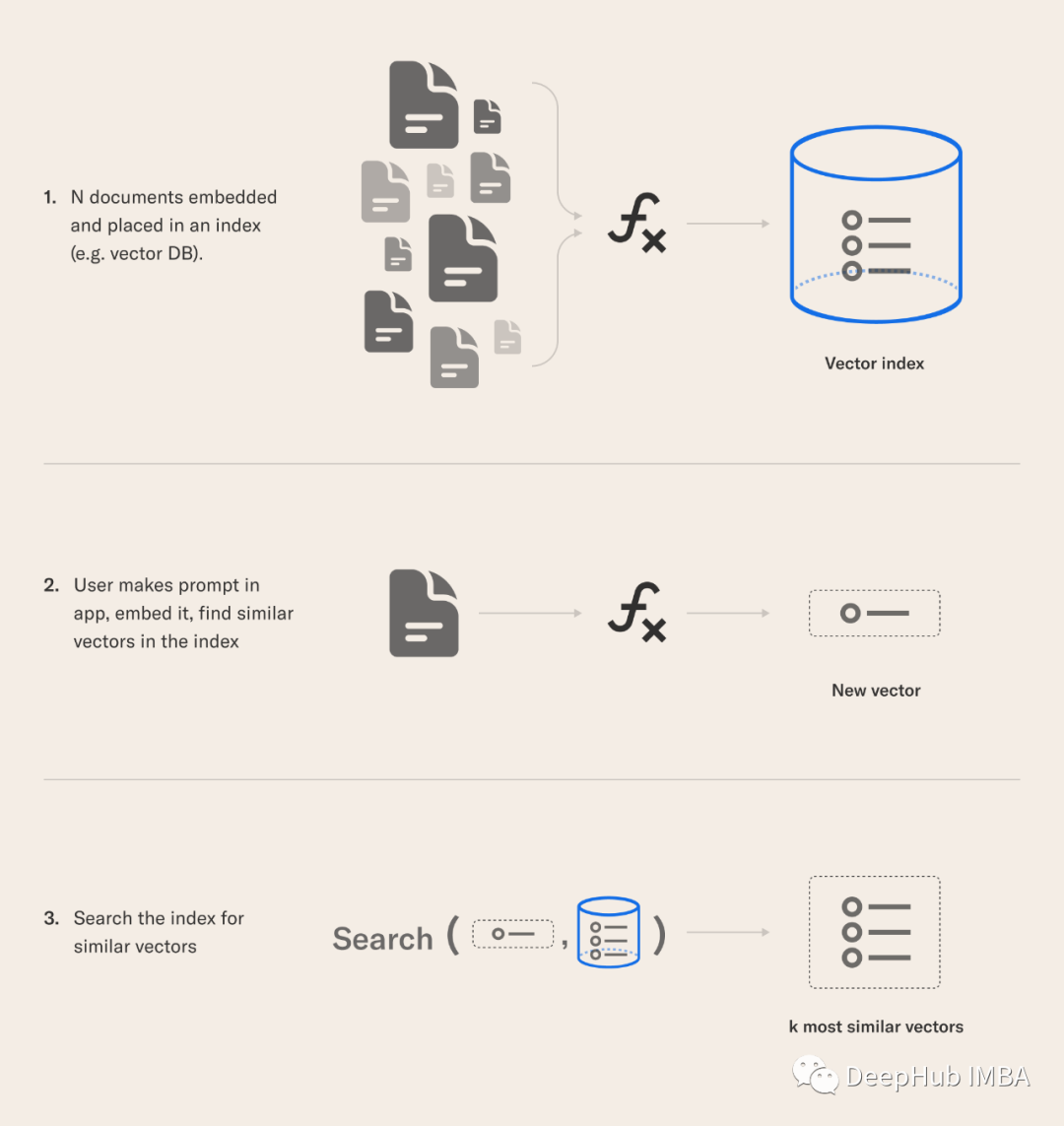
RAG应用程序的12种调优策略:使用“超参数”和策略优化来提高检索性能
本文从数据科学家的角度来研究检索增强生成(retrieve - augmented Generation, RAG)管道。讨论潜在的“超参数”,这些参数都可以通过实验来提高RAG管道的性能。
2023-2024年最全的人工智能深度学习毕业设计选题大全
这两年开始计算机毕业设计要求越来越高,有的题目甚至专业的老师和研究生也难以应对。为了各位同学以最少的精力通过毕设,为各位分享一些优质的毕业设计选题方向。深度学习,计算机视觉,目标检测,图像分割,图像分类,卷积神经网络具体课题如下:手写数字识别,手写字母识别,图片识别,水果识别,花卉识别,手势识别,安



