
NHWC和NCHW是卷积神经网络(cnn)中广泛使用的数据格式。它们决定了多维数据,如图像、点云或特征图如何存储在内存中。
- NHWC(样本数,高度,宽度,通道):这种格式存储数据通道在最后,是TensorFlow的默认格式。
- NCHW(样本数,通道,高度,宽度):通道位于高度和宽度尺寸之前,经常与PyTorch一起使用。
NHWC和NCHW之间的选择会影响内存访问、计算效率吗?本文将从模型性能和硬件利用率来尝试说明这个问题。
卷积作为GEMM
GEneral Matrix to Matrix Multiplication (通用矩阵的矩阵乘法)
卷积可以使用基于变换的方法来实现,如快速傅立叶变换,它将卷积转换为频域的元素乘法,或者使用无变换的方法,如矩阵乘法,其中输入和滤波器(卷积核)被平面化并使用矩阵操作组合以计算输出特征映射。
但是:fft是内存密集型的,因为它们需要额外的内存来存储转换后的矩阵。并且fft的计算成本很高,特别是在时域和频域之间来回转换数据时,涉及操作开销。
而卷积运算的一般矩阵乘法是这样的。每个接受域按列堆叠,得到特征映射变换矩阵。同时还将滤波器矩阵逐行平摊和叠加,形成滤波器变换矩阵。滤波变换和特征映射变换矩阵经过矩阵乘法运算,形成扁平化的输出矩阵。这里的变换矩阵是一个中间矩阵,只是数值重排,与频域变换没有关系。
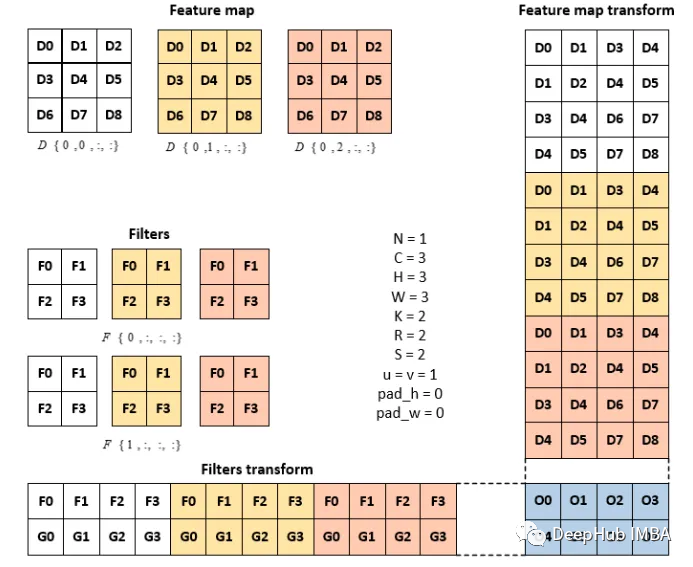
N -特征图的批量大小,C -输入通道,h -输入高度,W -输入宽度,
k -输出通道,r -滤波器高度,s -滤波器宽度,p -输出高度,q -输出宽度
特征映射变换矩阵和滤波变换矩阵被认为是中间矩阵,其维数大于特征映射本身。feature map的尺寸= C × H × W, (3x3x3) feature map transform的尺寸= CRS × NPQ (12x4)
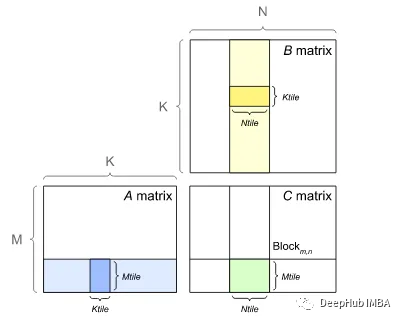
GEMM的GPU实现:
GPU为了避免内存预感使用了隐式GEMM。在隐式GEMM中,不是形成Transform矩阵,而是对每个列和行进行动态索引。最终的输出直接存储在输出张量对应的索引中。
由SMs(流多处理器)组成的GPU主要用于执行并行计算。在上面的隐式GEMM中,每个矩阵乘法可以分成更小的矩阵乘法或块。然后每个块都由SMs同时处理,以加快过程。
有了上面的计算过程,还需要存储张量,下面我们看看张量是如何在GPU中存储的。
张量通常以跨行格式存储在GPU中,其中元素在内存布局中以非连续的方式存储。这种跨行存储方法提供了以各种模式(如NCHW或NHWC格式)排列张量的灵活性,优化了内存访问和计算效率。
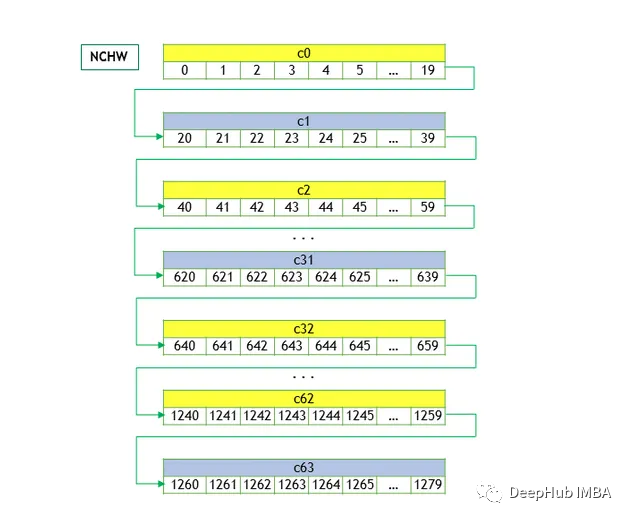
下图中所示的给定张量,我们可以用NCHW和NHWC的行主格式表示它们,行主存储通过顺序存储每一行来安排内存中的张量元素。

NCHW
这里W是最动态的维度。同一通道中的元素存储在一起,然后是下一个通道中的元素。
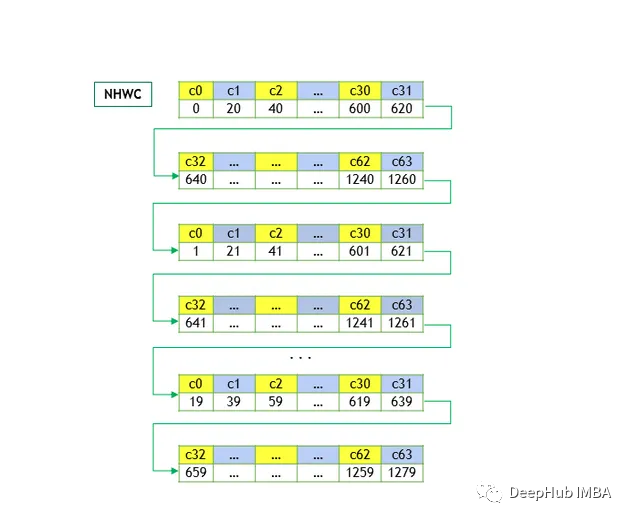
NHWC
这里C是动态的维度。所有通道中来自相同空间位置的元素依次存储,然后是来自下一个空间位置的元素,从而优化对每个通道内空间数据的访问。
GPU上的内存吞吐量
GPU是高度并行的处理器,当数据访问以合并方式完成时,它们工作得最好,这意味着它们喜欢以连续的、有组织的方式读取数据。当每个线程在二级缓存中查找数据时,如果是缓存命中(请求内存的内容在缓存中可用),则内存访问速度很快。如果是缓存丢失(缓存命中的否定),那么GPU接近DRAM来获取请求的内存地址的内容,这是一个耗时的操作。
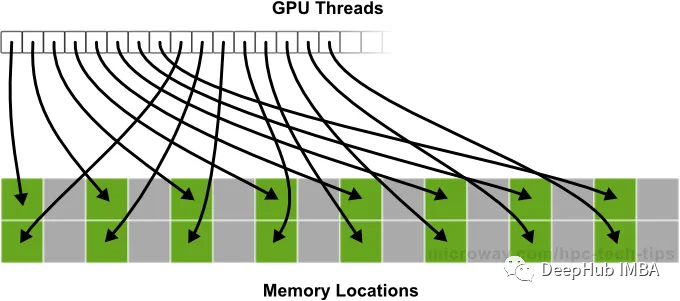
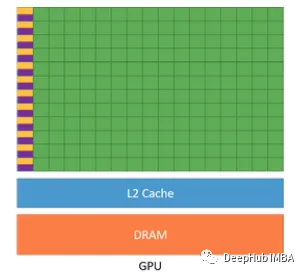
当GPU需要访问存储在内存中的数据时,它会在“事务”中这样做。根据GPU配置,每个事务访问32/128字节的信息。访问的信息保留在缓存中。当另一个GPU线程请求内存访问时,它首先检查缓存。如果数据在缓存中不可用,那么请求将被转发到DRAM。
GPU工作原理十分复杂,我们不想也没有时间在这里详细解释,所以将其简单概括为:
合并内存事务发生在GPU访问连续块中的内存时。如果GPU需要读取连续存储在内存中的32字节数据,它将执行单个合并内存事务来一次检索所有32字节。非合并内存事务发生在GPU需要访问未连续存储在内存中的数据时。在这种情况下,GPU将需要执行多个事务来检索所有必要的数据
在GEMM的情况下,无论滤波器的高度和宽度如何,我们都可以确保读取给定空间位置的所有通道信息。例如,如果我们的输入特征是128 x 128 x 32。无论使用1x1还是3x3内核,我们都可以读取位置(1,1)的所有通道。
如果使用NCHW,它将属于单个通道的所有元素存储在一起,我们将不得不跨到位置a[0], a[16384], a[32,768]……直到位置a[16384x31]进行1x1卷积。这些位置不是连续的,并且肯定会导致缓存丢失,从而导致内存读取期间的额外开销。在每个事务期间读取的其余数据也不被使用,也称为非合并内存事务。
当使用NHWC格式表示张量时,访问位置是a[0],a[1]…,a[127],它们是连续的,并且肯定是缓存命中。第一次访问a[0]会导致缓存丢失和从DRAM获取32/128字节数据的事务。当访问a[1]时,这将是保存事务的缓存命中。即使在一定数量的位置之后缓存丢失导致来自DRAM的事务,事务本身将携带连续内存位置的连续数据,可以在访问进一步位置时缓存命中,称为合并内存事务。
NHWC减少了张核gpu的内存访问瓶颈,从而优化了性能,与NCHW相比,这似乎是一个更好的选择。
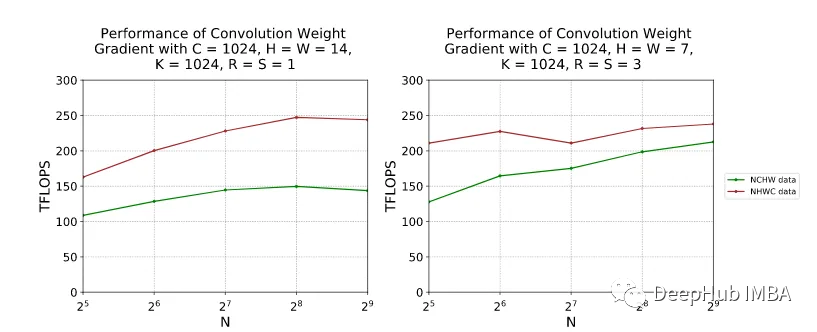
以下是NVIDIA A100-SXM4-80GB, CUDA 11.2, cuDNN 8.1下NCHW和NHCW的TFLOPS的性能条款。我们看到NHWC在两种设置下的TFLOPS方面表现更好。为了简单起见,在这里没有进入NC/xHWx布局,这是NHWC的一个变体,为NVIDIA张量核心操作准备。
那么为什么Pytorch还要使用NCHW呢?
官方论坛的一个帖子可以作为参考:
https://discuss.pytorch.org/t/why-does-pytorch-prefer-using-nchw/83637
另外就是TensorFlow 的官网也说过这么一段话,也可以作为参考
Most TensorFlow operations used by a CNN support both NHWC and NCHW data format. On GPU, NCHW is faster. But on CPU, NHWC is sometimes faster.
参考资料
- https://docs.nvidia.com/deeplearning/performance/dl-performance-convolutional/index.html#imp-gemm-dim
- https://docs.nvidia.com/deeplearning/cudnn/developer-guide/index.html
- https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html
- https://leimao.github.io/blog/CUDA-Convolution-Tensor-Layouts/
- https://www.microway.com/hpc-tech-tips/avoiding-gpu-memory-performance-bottlenecks/
- https://stackoverflow.com/questions/44280335/how-much-faster-is-nchw-compared-to-nhwc-in-tensorflow-cudnn
作者:Deepika