
在计算机视觉领域有两个主要的自监督模型:CLIP和DINOv2。CLIP彻底改变了图像理解并且成为图片和文字之间的桥梁,而DINOv2带来了一种新的自监督学习方法。
在本文中,我们将探讨CLIP和DINOv2的优势和它们直接微妙的差别。我们的目标是发现哪些模型在图像相似任务中真正表现出色。
CLIP
使用CLIP计算两幅图像之间的相似性是一个简单的过程,只需两步即可实现:提取两幅图像的特征,然后计算它们的余弦相似度。
我们先创建虚拟环境并安装包
#Start by setting up a virtual environment
virtualenv venv-similarity
source venv-similarity/bin/activate
#Install required packages
pip install transformers Pillow torch
接下来进行图像相似度的计算:
import torch
from PIL import Image
from transformers import AutoProcessor, CLIPModel
import torch.nn as nn
device = torch.device('cuda' if torch.cuda.is_available() else "cpu")
processor = AutoProcessor.from_pretrained("openai/clip-vit-base-patch32")
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32").to(device)
#Extract features from image1
image1 = Image.open('img1.jpg')
with torch.no_grad():
inputs1 = processor(images=image1, return_tensors="pt").to(device)
image_features1 = model.get_image_features(**inputs1)
#Extract features from image2
image2 = Image.open('img2.jpg')
with torch.no_grad():
inputs2 = processor(images=image2, return_tensors="pt").to(device)
image_features2 = model.get_image_features(**inputs2)
#Compute their cosine similarity and convert it into a score between 0 and 1
cos = nn.CosineSimilarity(dim=0)
sim = cos(image_features1[0],image_features2[0]).item()
sim = (sim+1)/2
print('Similarity:', sim)


上面两个相似的图像,获得的相似度得分达到了96.4%
DINOv2
使用DINOv2计算两幅图像之间的相似度的过程与CLIP的过程类似。使用DINOv2需要与前面提到的相同的软件包集,而不需要任何额外的安装:
from transformers import AutoImageProcessor, AutoModel
from PIL import Image
import torch.nn as nn
device = torch.device('cuda' if torch.cuda.is_available() else "cpu")
processor = AutoImageProcessor.from_pretrained('facebook/dinov2-base')
model = AutoModel.from_pretrained('facebook/dinov2-base').to(device)
image1 = Image.open('img1.jpg')
with torch.no_grad():
inputs1 = processor(images=image1, return_tensors="pt").to(device)
outputs1 = model(**inputs1)
image_features1 = outputs1.last_hidden_state
image_features1 = image_features1.mean(dim=1)
image2 = Image.open('img2.jpg')
with torch.no_grad():
inputs2 = processor(images=image2, return_tensors="pt").to(device)
outputs2 = model(**inputs2)
image_features2 = outputs2.last_hidden_state
image_features2 = image_features2.mean(dim=1)
cos = nn.CosineSimilarity(dim=0)
sim = cos(image_features1[0],image_features2[0]).item()
sim = (sim+1)/2
print('Similarity:', sim)
上面CLIP示例中相同的图像对,DINOv2获得的相似性得分为93%。
两个模型都可以给出图像的相似性,下面我们来进行深入的研究。
使用COCO数据集进行测试
这里使用来自COCO数据集验证集的图像来比较CLIP和DINOv2产生的结果。
流程如下:
- 遍历数据集以提取所有图像的特征。
- 将嵌入存储在FAISS索引中。
- 提取输入图像的特征。
- 检索前三个相似的图像。
1、特征提取和创建索引
import torch
from PIL import Image
from transformers import AutoProcessor, CLIPModel, AutoImageProcessor, AutoModel
import faiss
import os
import numpy as np
device = torch.device('cuda' if torch.cuda.is_available() else "cpu")
#Load CLIP model and processor
processor_clip = AutoProcessor.from_pretrained("openai/clip-vit-base-patch32")
model_clip = CLIPModel.from_pretrained("openai/clip-vit-base-patch32").to(device)
#Load DINOv2 model and processor
processor_dino = AutoImageProcessor.from_pretrained('facebook/dinov2-base')
model_dino = AutoModel.from_pretrained('facebook/dinov2-base').to(device)
#Retrieve all filenames
images = []
for root, dirs, files in os.walk('./val2017/'):
for file in files:
if file.endswith('jpg'):
images.append(root + '/'+ file)
#Define a function that normalizes embeddings and add them to the index
def add_vector_to_index(embedding, index):
#convert embedding to numpy
vector = embedding.detach().cpu().numpy()
#Convert to float32 numpy
vector = np.float32(vector)
#Normalize vector: important to avoid wrong results when searching
faiss.normalize_L2(vector)
#Add to index
index.add(vector)
def extract_features_clip(image):
with torch.no_grad():
inputs = processor_clip(images=image, return_tensors="pt").to(device)
image_features = model_clip.get_image_features(**inputs)
return image_features
def extract_features_dino(image):
with torch.no_grad():
inputs = processor_dino(images=image, return_tensors="pt").to(device)
outputs = model_dino(**inputs)
image_features = outputs.last_hidden_state
return image_features.mean(dim=1)
#Create 2 indexes.
index_clip = faiss.IndexFlatL2(512)
index_dino = faiss.IndexFlatL2(768)
#Iterate over the dataset to extract features X2 and store features in indexes
for image_path in images:
img = Image.open(image_path).convert('RGB')
clip_features = extract_features_clip(img)
add_vector_to_index(clip_features,index_clip)
dino_features = extract_features_dino(img)
add_vector_to_index(dino_features,index_dino)
#store the indexes locally
faiss.write_index(index_clip,"clip.index")
faiss.write_index(index_dino,"dino.index")
2、图像相似度搜索
import faiss
import numpy as np
import torch
from transformers import AutoImageProcessor, AutoModel, AutoProcessor, CLIPModel
from PIL import Image
import os
#Input image
source='laptop.jpg'
image = Image.open(source)
device = torch.device('cuda' if torch.cuda.is_available() else "cpu")
#Load model and processor DINOv2 and CLIP
processor_clip = AutoProcessor.from_pretrained("openai/clip-vit-base-patch32")
model_clip = CLIPModel.from_pretrained("openai/clip-vit-base-patch32").to(device)
processor_dino = AutoImageProcessor.from_pretrained('facebook/dinov2-base')
model_dino = AutoModel.from_pretrained('facebook/dinov2-base').to(device)
#Extract features for CLIP
with torch.no_grad():
inputs_clip = processor_clip(images=image, return_tensors="pt").to(device)
image_features_clip = model_clip.get_image_features(**inputs_clip)
#Extract features for DINOv2
with torch.no_grad():
inputs_dino = processor_dino(images=image, return_tensors="pt").to(device)
outputs_dino = model_dino(**inputs_dino)
image_features_dino = outputs_dino.last_hidden_state
image_features_dino = image_features_dino.mean(dim=1)
def normalizeL2(embeddings):
vector = embeddings.detach().cpu().numpy()
vector = np.float32(vector)
faiss.normalize_L2(vector)
return vector
image_features_dino = normalizeL2(image_features_dino)
image_features_clip = normalizeL2(image_features_clip)
#Search the top 5 images
index_clip = faiss.read_index("clip.index")
index_dino = faiss.read_index("dino.index")
#Get distance and indexes of images associated
d_dino,i_dino = index_dino.search(image_features_dino,5)
d_clip,i_clip = index_clip.search(image_features_clip,5)
3、结果
使用四种不同的图像作为输入,搜索产生了以下结果:




如果肉眼判断,DINOv2表现出稍好的性能。
使用DISC21数据集进行测试
为了量化CLIP和DINOv2的差别,我们选择了专门为图像相似性搜索创建的DISC21数据集。由于它的实际大小为350GB,我们将使用150,000个图像子集。
在参数方面,我们将计算:
- 准确率:正确预测的图像与图像总数的比率。
- top -3准确率:在前三幅相似图像中找到正确图像的次数占图像总数的比例。
- 计算时间:处理整个数据集所需的时间。
结果如下:
特征提取:CLIP:每秒70.7个图像,DINOv2:每秒69.7个图像,2者的计算密集度都差不多。
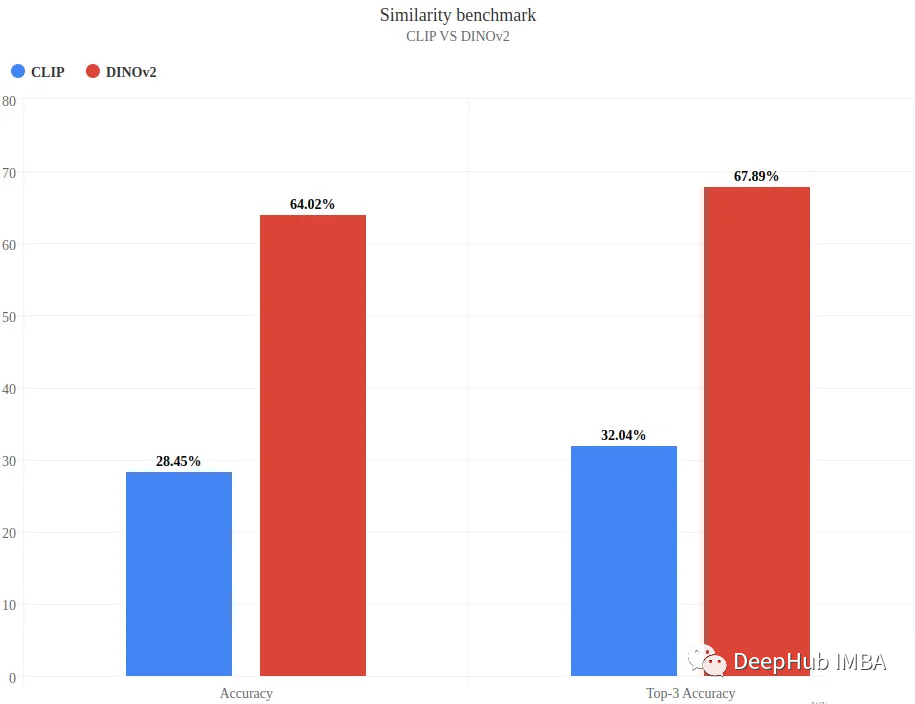
准确率和前三名的准确率
两种模型都正确地预测了图像

所有模型都找不到正确的图像

只有CLIP预测正确的图像,DINOv2的top3

只有DINOv2预测正确的图像

结果分析
DINOv2明显的胜出,他在这个个非常具有挑战性的数据集上实现了64%的准确率。相比之下,CLIP只有28.45%。
在计算效率方面两种模型表现出非常相似的特征提取时间。
这里DINOv2大幅领先的一个原因是MetaAI使用DISC21数据集作为其模型的基准,这肯定会给DINOv2带来有利的优势。但是我们可以看到在COCO数据集上的测试中显示了有趣的细微差别:DINOv2在识别图像中的主要元素方面表现出更高的能力,而CLIP在专注于输入图像中的特定细节方面表现得很熟练(看看 bus那个图像,CLIP找出的全部是红色的车,这可能是因为它与文本对齐时包含了颜色)
还有一个问题就是CLIP和DINOv2之间嵌入维数的差异。CLIP的嵌入维数为512,而DINOv2的嵌入维数为768。所以可能也是差异的原因,但是如果使用更大的CLIP模型,执行的速度应该不会这么快了。
总结
DINOv2在图像相似任务中表现出卓越的准确性,展示了其实际应用的潜力。CLIP虽然值得称赞,但相比之下就显得不足了。CLIP在需要关注小细节的场景中特别有用。两种模型都表现出相似的计算效率,如果只针对于图像的单模态,DINOv2应该是一个不错的选择。
作者:JeremyK