Designify——AI优化图像设计,自动去背景、调整构图、添加视觉效果,创建高质量的设计图像
Designify是一款强大的 AI 驱动图像设计工具,适合需要快速生成高质量图片的用户。通过自动化背景移除、图像优化和智能裁剪等功能,它大大简化了图像处理的流程,尤其适合电商、广告和社交媒体的图像需求。虽然对一些高级用户来说其定制功能可能不够精细,但对于大部分需要快速完成设计任务的场景,Desig
【智能流体力学】ANSYS Fluent计算流体力学原理、仿真过程分析方法介绍
计算流体动力学(CFD)是研究流体流动、传质、传热、化学反应及相关现象的一门科学。它通过对质量守恒、动量守恒和能量守恒等基本方程的计算,来预测和分析这些现象。CFD能够为工程师和科学家提供流体流动行为的详细信息,从而帮助在设计和优化过程中做出更科学的决策。CFD的基本原理质量守恒(Continuit
可解释性:走向透明与可信的人工智能
随着人工智能的不断发展,模型的可解释性已经成为了一个不可忽视的问题。尽管深度学习模型具有强大的预测能力,但其“黑盒”特性限制了其在一些高风险领域的应用。通过采用LIME、SHAP等可解释性方法,我们不仅能够提高模型的透明度,还能够增强模型的可靠性与公平性。
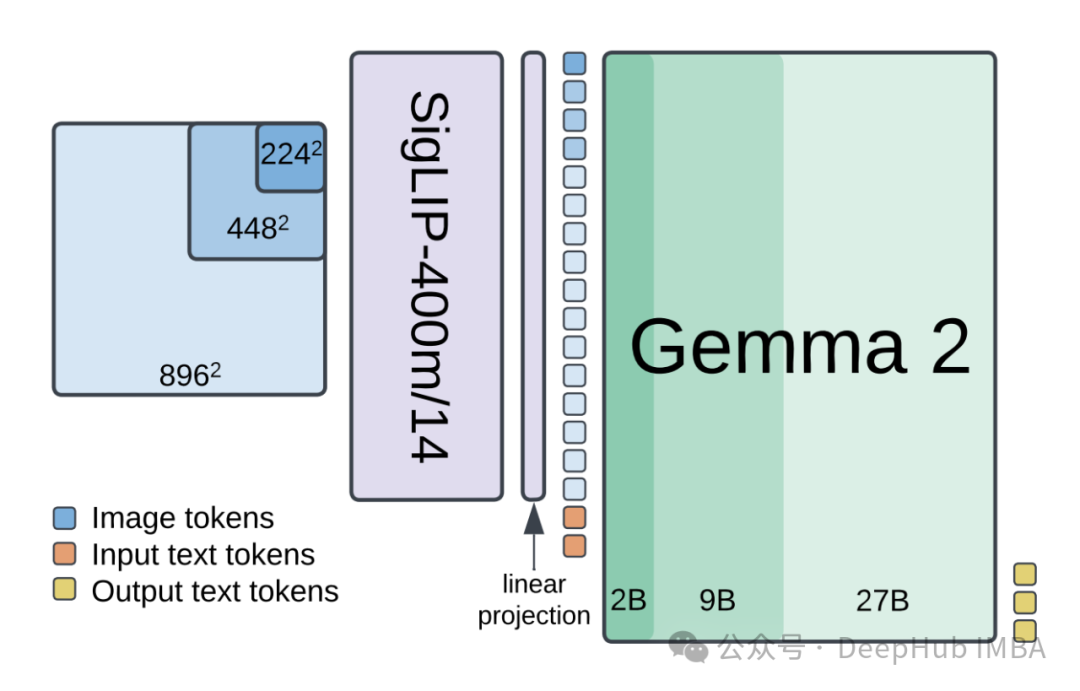
使用PaliGemma2构建多模态目标检测系统:从架构设计到性能优化的技术实践指南
本文详细阐述了如何利用PaliGemma2构建高性能的多模态目标检测系统。
AI生成图像模型的原理与优化技术-从对抗学习到高质量图像生成【附核心实战代码】
在本文中,我们探讨了AI生成图像模型(AIGC)的前沿技术,从生成原理到高质量图像生成的优化策略进行了深入分析。生成原理介绍了生成对抗网络(GAN)、变分自编码器(VAE)和扩散模型的基本概念和工作原理。这些模型通过学习数据分布,能够生成具有真实感的图像。模型训练讨论了模型训练中的关键步骤,包括数据
sliding window attention
同时,这种方式并不是意味着当前token只能获取到前window_size个token的信息,因为当前token前面的window_size个token也都是能够获取到前面的信息的,因此只要网络达到一定的深度,这样的sliding window attention是可行的,并不会损失太多信息。sli
“水刊之王”,发表直通车几乎全收,计算机人工智能四大水榜sci
今天给大家推荐计算机人工智能五大水榜sci
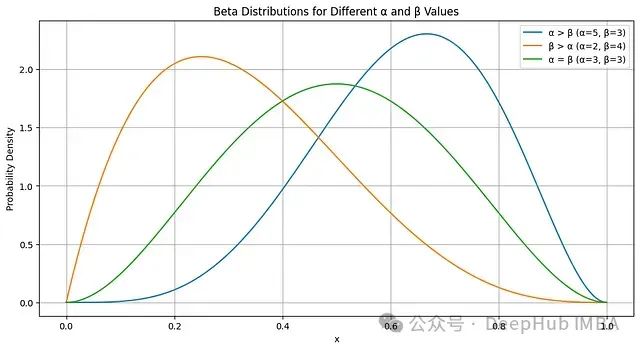
Beta分布与汤普森采样:智能决策系统概率采样的理论基础
Beta分布是二项分布和伯努利分布的共轭先验。当先验采用Beta分布,似然函数为二项分布或伯努利分布时,后验分布仍然是Beta分布。
【AI学习】Mamba学习(十八):S6的硬件感知设计
对于S6模型的硬件感知设计,尤其是所谓的并行扫描,看论文没有看清楚,查了相关博客,再进行一下梳理。
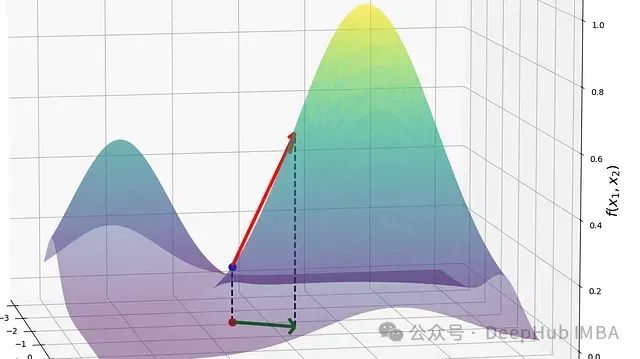
从方向导数到梯度:深度学习中的关键数学概念详解
本文将系统探讨方向导数与梯度的理论基础,并阐述二者的内在联系
YOLO 训练异常终止、断电、服务器关机,恢复训练,训练过程中调整训练周期
对于训练一个新的YOLO模型或者是跑原模型,在训练过程中总会遇到误触或是异常操作导致训练终止,肯定不想重新开始训练
【植物识别】Python+深度学习+人工智能+CNN卷积神经网络+算法模型训练+TensorFlow
植物识别系统,使用Python作为主要编程语言开发,通过收集常见的6中植物树叶(‘广玉兰’, ‘杜鹃’, ‘梧桐’, ‘樟叶’, ‘芭蕉’, ‘银杏’)图片作为数据集,然后使用TensorFlow搭建ResNet50算法网络模型,通过对数据集进行处理后进行模型迭代训练,得到一个识别精度较高的H5模型
《人工智能(AI)和深度学习简史》
FLUX.1 (2024):Black Forest Lab 推出了FLUX.1,这是一个先进的扩散模型,用于AI图像生成,具有出色的速度、质量和对提示的响应能力。1969年,XOR问题暴露了感知器(单层神经网络)的局限性。• GPT (2018):生成式预训练Transformer(Gene
华为昇腾310P AI 智能计算模组规格书
PCIe Gen4.0 ,兼容 3.0/2.0/1.0 XGE、SATA、USB 等接口。基于昇腾310P 模组设计的 AI 智能产品,可根据实际应用需求,可应用于机器人、无人机、无人。领域,有着极高的性价比,具有超强算力、 超高能效、高性能特征检索、安全启动等优势。支持 I2C、 UART、 CA
ORCA:基于持续批处理的LLM推理性能优化技术详解
ORCA系统创新性地提出了持续批处理概念,通过引入迭代级调度和选择性批处理机制,有效解决了大语言模型批处理中的关键技术挑战。
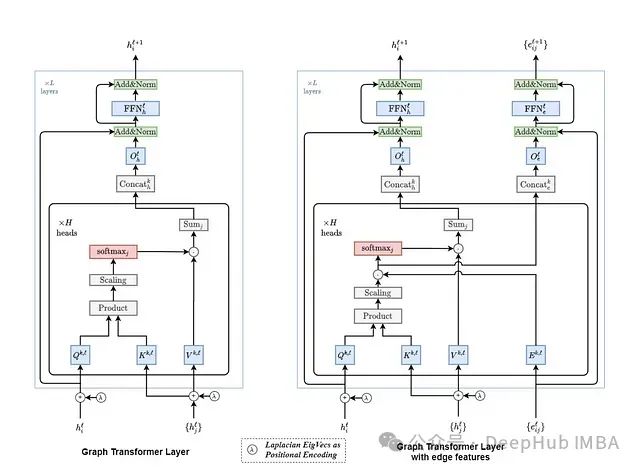
深入解析图神经网络:Graph Transformer的算法基础与工程实践
本文不仅是对Graph Transformer技术的深入解析,更是一份从理论到实践的完整技术指南,为那些希望在图神经网络领域深入发展的技术人员提供了宝贵的学习资源。
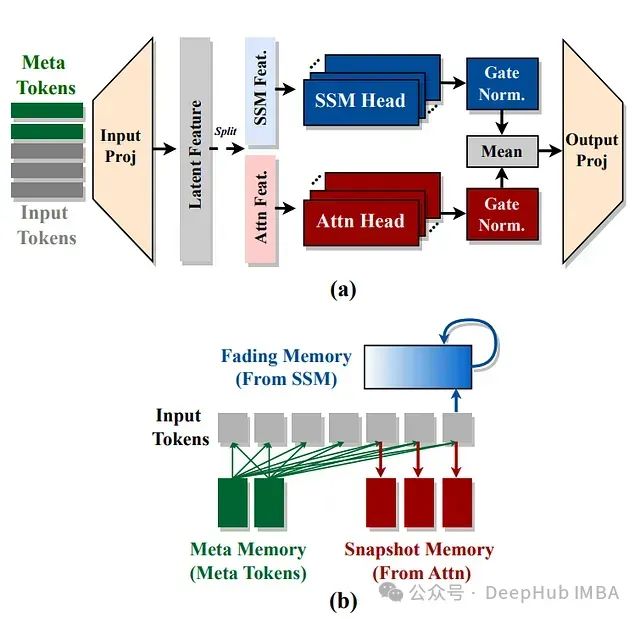
Hymba: 结合注意力头和SSM头的创新型语言模型方案
NVIDIA提出了Hymba架构,通过在同一层中结合注意力头和SSM头,以实现两种架构优势的互补。
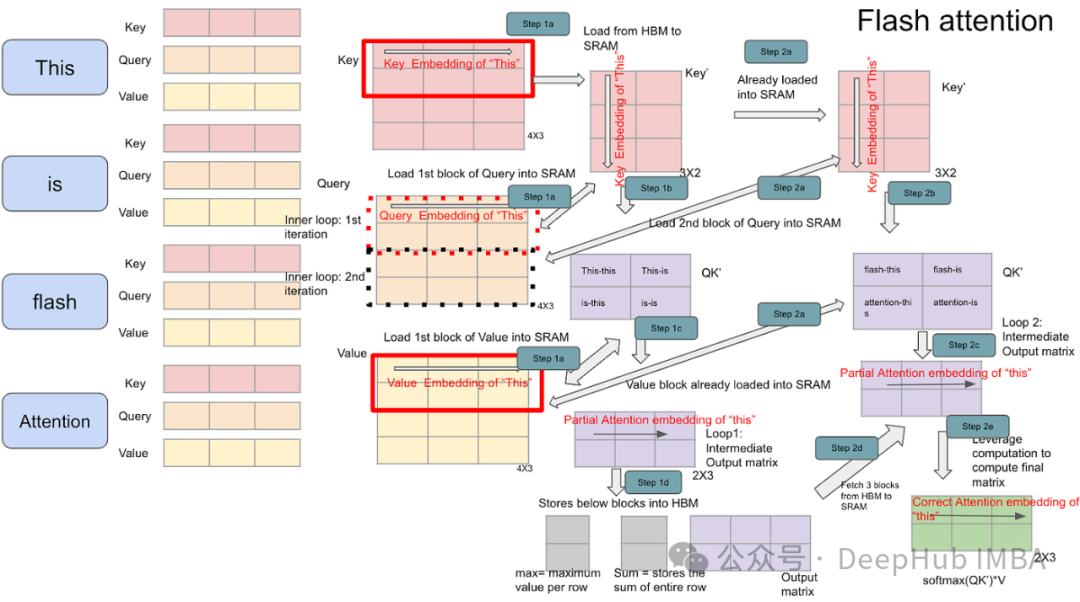
Transformer模型变长序列优化:解析PyTorch上的FlashAttention2与xFormers
本文将进一步探讨变长输入序列这一挑战——这是真实世界数据(如文档、代码、时间序列等)的固有特征。
【人工智能】Transformers之Pipeline(二十七):蒙版生成(mask-generation)
本文对transformers之pipeline的蒙版生成(mask-generation)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以基于pipeline使用文中的2行代码极简的使用多模态中的蒙版生成(mask-generation)模型。



