深入解析Cursor: AI辅助编程的核心技术揭秘
作为开发者,你是否好奇过AI是如何理解和生成代码的?今天,让我们一起揭开Cursor这款强大AI编程助手的神秘面纱,深入探讨其背后的核心技术原理。从先进的语言模型到智能的上下文分析,从海量的训练数据到持续的更新机制,本文将为你全面解析Cursor的技术内幕,助你更好地驾驭这个AI编程利器!
docker部署本地词向量模型
会先去下载 docker 镜像,然后运行容器。特别要强调的是:model 的路径可不是随便写的。在我的这个例子中,启动 docker 时,映射的路径是。,因此 model 的路径必须以/data 开头,不然的话是找不到模型的。,大家可以参考我的路径来调整 model 和 volume 变量的值。
《人工智能深度学习的基本路线图》
《人工智能深度学习的基本路线图》
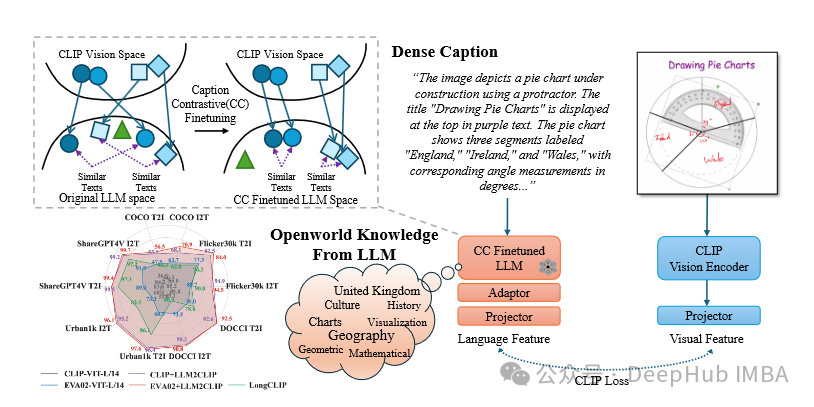
LLM2CLIP:使用大语言模型提升CLIP的文本处理,提高长文本理解和跨语言能力
LLM2CLIP 为多模态学习提供了一种新的范式,通过整合 LLM 的强大功能来增强 CLIP 模型。
【AI知识点】近似最近邻搜索(ANN, Approximate Nearest Neighbor Search)
近似最近邻搜索(ANN) 是一种为了提升高维数据相似性搜索效率的技术,它在牺牲一定精度的前提下,大大提升了搜索速度。它被广泛应用于推荐系统、图像检索、文本相似性搜索等实际场景。常见的ANN算法包括局部敏感哈希(LSH)、图嵌入法(如HNSW)、矢量量化(VQ)等,它们通过不同的方式优化搜索过程,解决
ai文件太大怎么降低图片分辨率
通过本文介绍的方法,你应该已经掌握了如何有效地管理和控制AI文件大小的知识。记住,合理规划项目结构、恰当地运用各种编辑技巧以及始终保持警惕的态度是成功的关键所在。希望这些信息对你有所帮助!
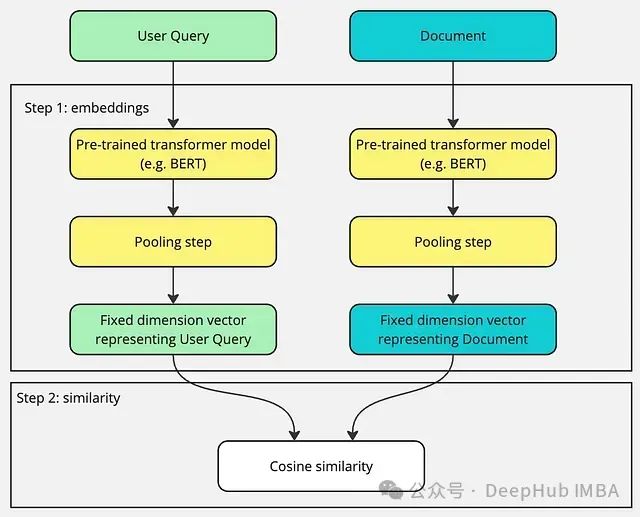
解读双编码器和交叉编码器:信息检索中的向量表示与语义匹配
在信息检索领域(即从海量数据中查找相关信息),双编码器和交叉编码器是两种至关重要的工具。它们各自拥有独特的工作机制、优势和局限性。本文将深入探讨这两种核心技术。
【AI学习】Mamba学习(十二):深入理解S4模型
HiPPO A矩阵在线性代数意义上是高度非正规的,这阻碍了传统算法技术的应用。因此,尽管 LSSL 表明 SSM 具有很强的性能,但它们目前作为通用序列建模解决方案在计算上是不切实际的。S4将HiPPO 矩阵A分解为正规矩阵和低秩矩阵的和,使得A可以被稳定地对角化;利用Woodbury identi
利用Blackbox AI让编程更轻松
随着人工智能技术的发展,AI已经成为工作中不可缺少的工具之一。由于训练集、调教等方面的差别,不同的AI适用的工作也不尽相同。在编程辅助方面,已经有一系列比较成熟的平台,但它们一方面价格昂贵,另一方面功能比较单一。AI聊天是所有人工智能软件的基础功能,我们接下来测试一下它的准确性。现在很多AI模型都有
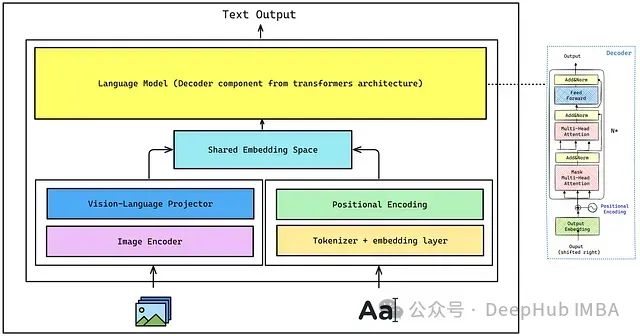
使用Pytorch构建视觉语言模型(VLM)
本文将介绍 VLM 的核心组件和实现细节,可以让你全面掌握这项前沿技术。我们的目标是理解并实现能够通过指令微调来执行有用任务的视觉语言模型。

使用 PyTorch-BigGraph 构建和部署大规模图嵌入的完整教程
本文深入探讨了使用 PyTorch-BigGraph (PBG) 构建和部署大规模图嵌入的完整流程,涵盖了从环境设置、数据准备、模型配置与训练,到高级优化技术、评估指标、部署策略以及实际案例研究等各个方面。
什么是AI神经网络?
在当今的科技时代,人工智能(AI)已经深入到我们生活的各个方面,而神经网络则是推动这一发展的重要技术之一。总之,AI神经网络是人工智能领域的重要组成部分,它的强大能力正在改变我们的生活方式。无论你是技术爱好者,还是普通用户,了解神经网络的基本原理都能帮助你更好地理解这个快速发展的科技世界。随着计算能
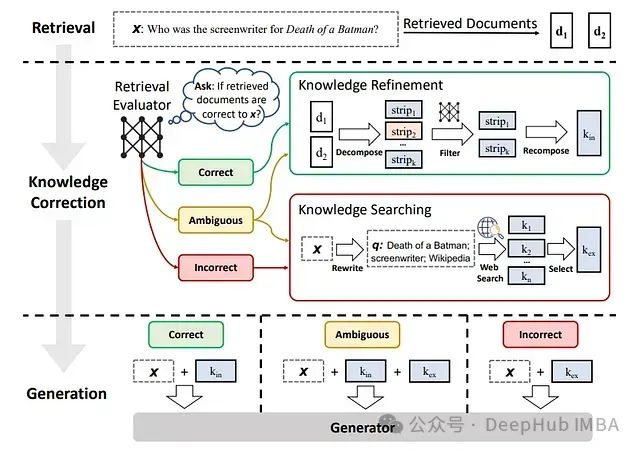
25 个值得关注的检索增强生成 (RAG) 模型和框架
本文深入探讨 25 种先进的 RAG 变体,每一种都旨在优化检索和生成过程的特定方面。从标准实现到专用框架,这些变体涵盖了成本限制、实时交互和多模态数据集成等问题,展示了 RAG 在提升 NLP 能力方面的多功能性和潜力。
【AI知识点】内部协变量偏移(Internal Covariate Shift)
内部协变量偏移(Internal Covariate Shift) 是深度学习中的一个概念,它描述了在神经网络训练过程中,每一层的输入分布随着训练过程的变化而变化的现象。这种现象会增加训练的难度,导致网络收敛变慢,甚至可能影响模型的最终性能。
OpenCV与AI深度学习 | 实战 | YOLO11自定义数据集训练实现缺陷检测 (标注+训练+预测 保姆级教程)
本文将手把手教你用YOLO11训练自己的数据集并实现缺陷检测。
【有啥问啥】大模型内容水印技术简介
随着生成式大模型(如GPT-4)的广泛应用,如何识别和追踪这些模型生成的内容成为了一个重要课题。大模型内容水印(Large Model Content Watermarking)应运而生,旨在为生成内容嵌入标记,以实现来源追踪、版权保护和内容审核等目的。本文将详细解释大模型内容水印的原理、作用,介绍
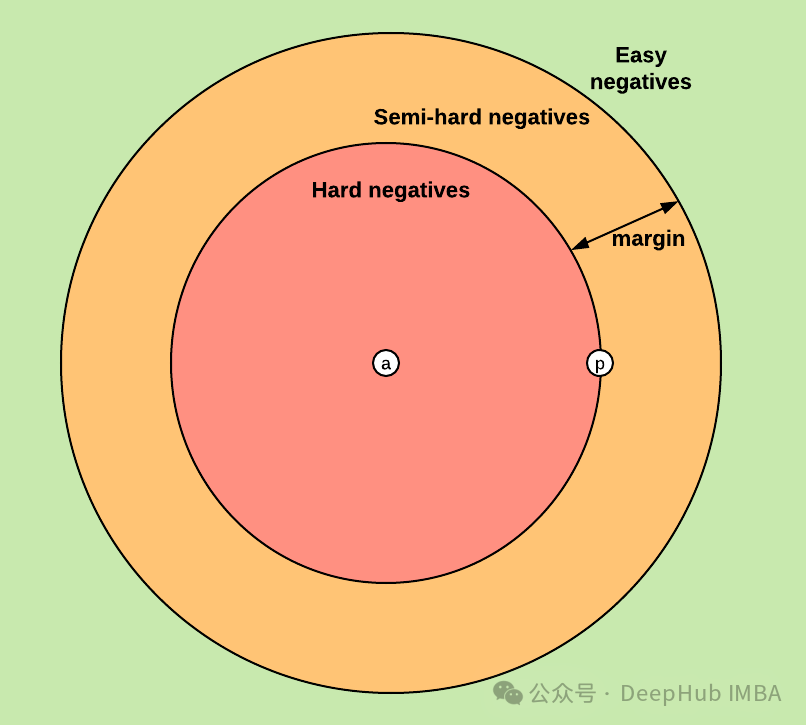
利用PyTorch的三元组损失Hard Triplet Loss进行嵌入模型微调
本文介绍如何使用 PyTorch 和三元组边缘损失 (Triplet Margin Loss) 微调嵌入模型,并重点阐述实现细节和代码示例
AI基础知识
必会知识
使用Amazon SageMaker JumpStart微调Meta Llama 3.1模型以进行生成式AI推理
还可以在SageMaker JumpStart上找到微调其他变体Meta Llama 3.1模型(8B和70B基础和指令)的代码([GitHub仓库](https://github.com/aws/amazon-sagemaker-examples/blob/default/ generati
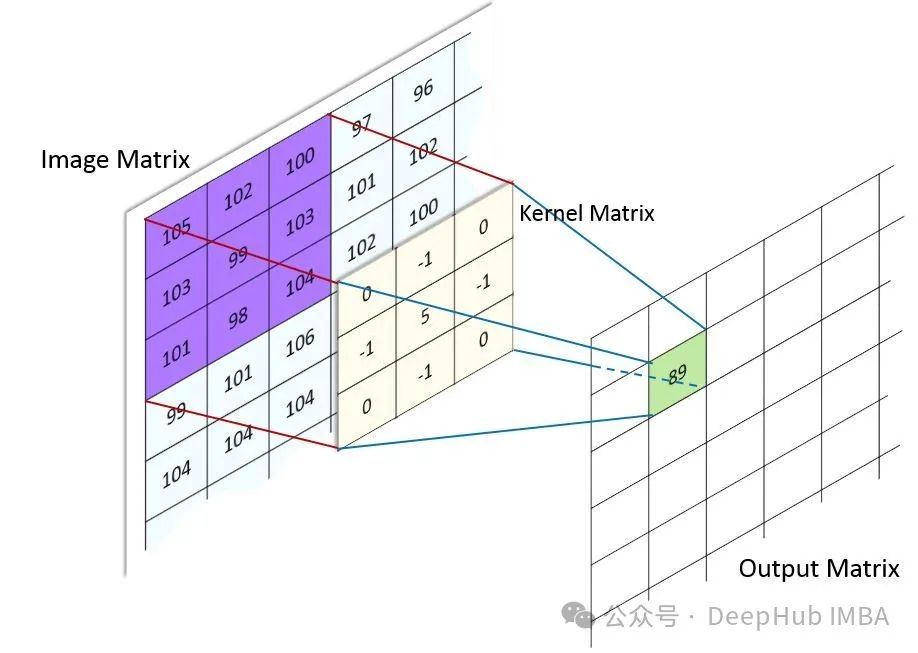
为什么卷积现在不火了:CNN研究热度降温的深层原因分析
纵观近年的顶会论文和研究热点,我们不得不承认一个现实:CNN相关的研究论文正在减少,曾经的"主角"似乎正逐渐淡出研究者的视野。



