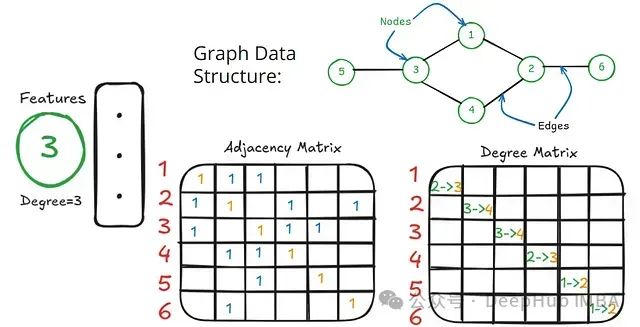
图卷积网络入门:数学基础与架构设计
本文系统地阐述了图卷积网络的架构原理。通过简化数学表述并聚焦于矩阵运算的核心概念,详细解析了GCN的工作机制。
顶会新热门:小波变换×Transformer,效率翻倍的AI图像去噪神奇组合
小波变换与Transformer的结合主要探讨如何利用小波变换的多尺度特性来增强Transformer在处理信号和图像数据时的表现。具体来说,小波变换能够有效提取信号中的局部特征,并在时间和频率域上提供信息,这对于处理复杂的信号(如图像和音频)非常有用。结合小波变换的Transformer可以在保持
人工智能深度学习的经典视觉项目实战之目标追踪(DeepSort,卡尔曼滤波)算法解读
4)如果满足3)的所有线的数量=n,则找到了最优分配,算法结束,否则(例是3行3列矩阵,但满足的线只有2,则3不等以2)进入5)。1)第一个核心模块就是前面求解x1与v1的公式(其中用到的状态转移矩阵),即x1=x+v*t+(1/2)*u*t,v1=v+ut转为通用矩阵形式 g=Ax+B*u,另外一
训练过程训练集的准确率都低于验证集和测试集的准确率可能的原因
需要综合考虑以上原因,通过逐步调整训练策略和超参数设置,找到最佳的训练方法,以提升训练集上的准确率,确保模型在所有数据集上的表现更加均衡和一致。
时间序列中多维度、多变量、多元、多尺度
这样的数据集就是一个多维时间序列,其中每个维度代表着一个气象变量,而时间是序列的主要维度。多变量时间序列是指一个时间序列数据集包含多个解释变量(x1,x2,x3...)和一个相应变量(y1)来表示,这些变量在时间上是相关的。多元时间序列是指一个时间序列数据集包含多个观测变量(如y1,y2,y3...
OpenCV与AI深度学习 | PaddleOCR 2.9 发布, 正式开源文本图像智能分析利器
飞桨低代码开发工具 PaddleX,依托于 PaddleOCR 的先进技术,支持了 OCR 领域的低代码全流程开发能力。通过低代码全流程开发,可实现简单且高效的模型使用、组合与定制。这将显著减少模型开发的时间消耗,降低其开发难度,大大加快模型在行业中的应用和推广速度。
【AI-20】训练服务器和推理服务器
(一)任务排队与优先级管理。(二)性能监控与优化。(三)便于管理和维护。
丹摩征文活动 | SD3+ComfyUI模型图文部署:AI工程师的实践与探索
在丹摩智算平台上部署SD3+ComfyUI图文模型的过程中,我感受到了极高的效率和便捷性,尤其是在处理图文生成任务时表现尤为出色。作为一名AI工程师,我对平台的计算能力和操作简便性有着严格的要求,而丹摩智算正好满足了这些需求。丹摩智算平台的界面用户友好,功能布局合理,使得整个部署过程非常直观。即使是
人工智能-深度学习-学习笔记
人工智能当前的发展呈现出加速和深化的趋势,特别是在深度学习领域。技术革新与应用拓展并行推进,深度学习算法和模型结构不断创新,为处理复杂数据提供了强有力的工具,使得AI在图像识别、语音处理、自然语言理解等方面取得显著进展,并广泛应用于金融、医疗、教育、交通等多个行业。同时,数据驱动和算力提升成为AI发
OPT 大语言模型(Large Language Model)结构
大语言模型follow GPT的做法,其基本组成结构是Decoder-only的Transformer block,多个Transformer Block堆叠在一起;不同数量、不同Head、不同隐藏层维度构成了不同参数量的大模型(也即模型跟着的后缀,比如,6.7B);预训练模型参数的数据类型(大模型
AI 翻唱
So-vits-svc 4.1 训练模型全过程。UVR:用于人声歌声分离,降噪。Slicer-gui(Audio-Slicer):用于音频裁剪。So-vits-svc 4.1:训练模型。Adobe Audition:后期音频编辑。
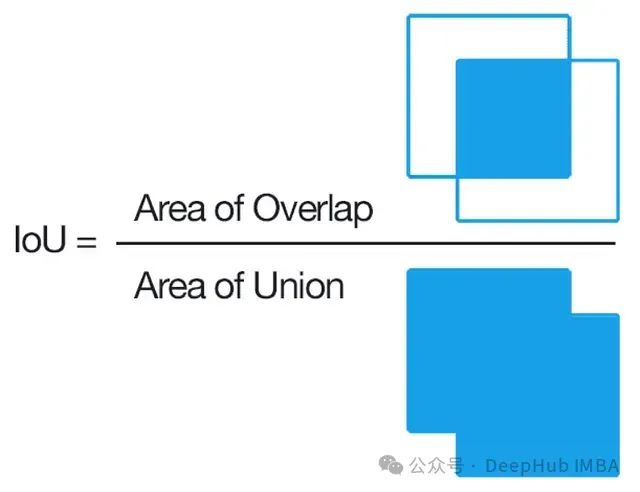
IoU已经out了,试试这几个变体:GIoU、DIoU和CIoU介绍与对比分析
GIoU、DIoU和CIoU这三个变体都有各自的独到之处,它们在一定程度上弥补了普通IoU在处理不重叠、距离较远或形状差异较大的边界框时的不足。
AI4Science(2024年4月总结):物理驱动及数据驱动深度学习方法用于科学计算问题
本文主要介绍,用于科学计算问题中的物理驱动和数据驱动的深度学习方法。通过方法算例,对现有方法总结。时间是2024年4月。
GaussDB高智能--库内AI引擎:模型管理&数据集管理
从模型管理与数据集管理两方面,对GaussDB的库内AI引擎进行了详细解读
【循环神经网络】:教AI写周杰伦风格的歌词
只会python基础,也能让AI写歌词
【人工智能】PyTorch、TensorFlow 和 Keras 全面解析与对比:深度学习框架的终极指南
本文将为你一一解答。为了更直观地了解三大框架的使用方式,下面我们将通过一个简单的手写数字识别(MNIST)任务,演示如何使用 PyTorch、TensorFlow 和 Keras 构建和训练一个基本的神经网络模型。通过以上简单的示例,我们可以看到,虽然三大框架在具体实现上有所不同,但总体流程相似,都
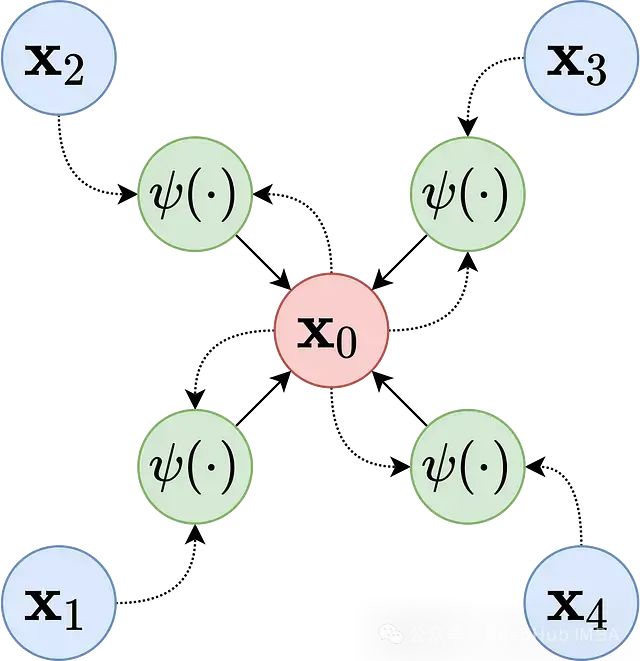
图神经网络在欺诈检测与蛋白质功能预测中的应用概述
本文将深入探讨GNNs在欺诈检测和生物信息学领域的应用机制与技术原理。
【AI知识点】余弦相似度(Cosine Similarity)
余弦相似度(Cosine Similarity)是一种用于衡量两个向量在方向上的相似程度的指标。它主要用于文本分析、自然语言处理(NLP)、推荐系统等任务中,能够衡量两个向量之间的相似性,而不受向量的长度(模)影响。
基于LIDC-IDRI肺结节肺癌数据集的人工智能深度学习分类良性和恶性肺癌(Python 全代码)全流程解析(三)
混淆矩阵(Confusion Matrix)是一种用于评估分类模型性能的表格,它将模型预测的结果与实际的类别标签进行比较,从而展现模型的分类准确性。对测试集的真实标签(y_true)和模型预测得到的二元分类结果(y_pred)进行评估,通过输出分类报告(classification_report)来
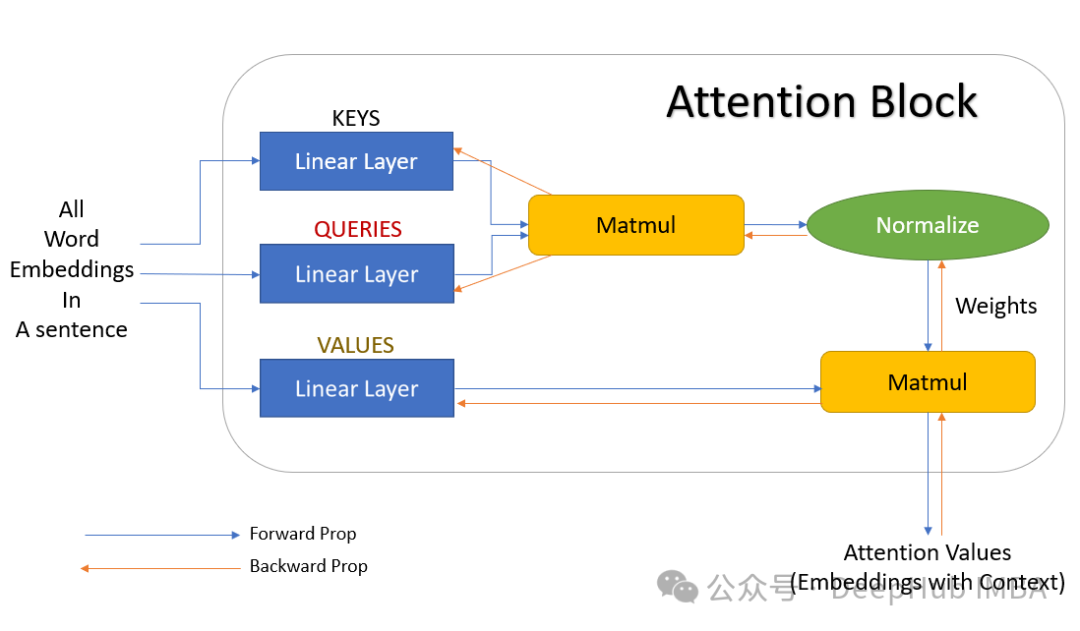
优化注意力层提升 Transformer 模型效率:通过改进注意力机制降低机器学习成本
本文将深入探讨在 PyTorch 生态系统中优化注意力层的多种技术路径,并将重点聚焦于那些在降低计算成本的同时能够保持注意力层精度的创新方法。



