
使用Torch Compile提高大语言模型的推理速度
在本文中,我们将探讨torch.compile的工作原理,并测量其对LLMs推理性能的影响。
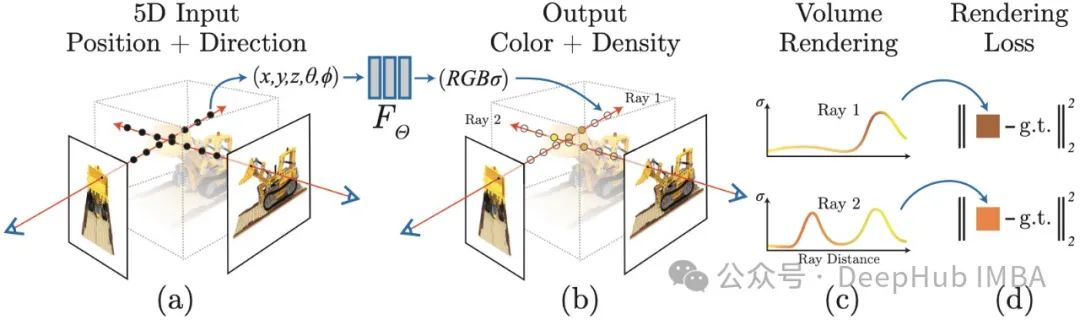
神经辐射场(NeRF)实战指南:基于PyTorch的端到端实现
本文将系统性地引导读者使用PyTorch构建完整的神经辐射场(NeRF)处理流程。从图像加载到高质量三维场景渲染,文章将详细讨论实现过程中的关键技术点和优化策略。
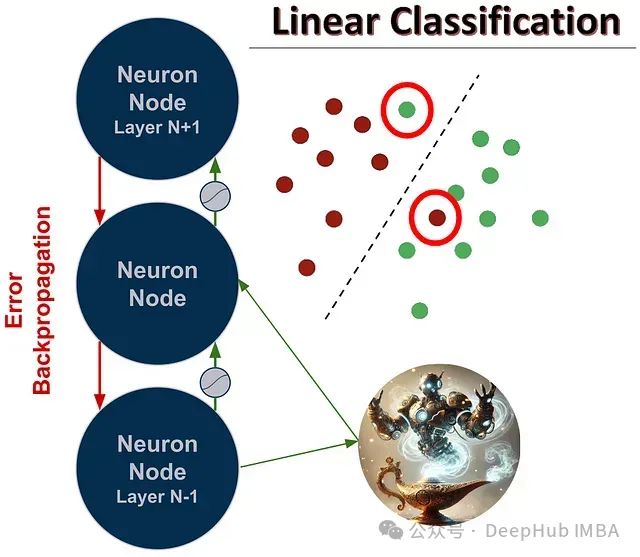
Perforated Backpropagation:神经网络优化的创新技术及PyTorch使用指南
Perforated Backpropagation技术代表了深度学习基础构建模块的重要革新,通过仿生学习机制重塑了人工神经元的计算范式。
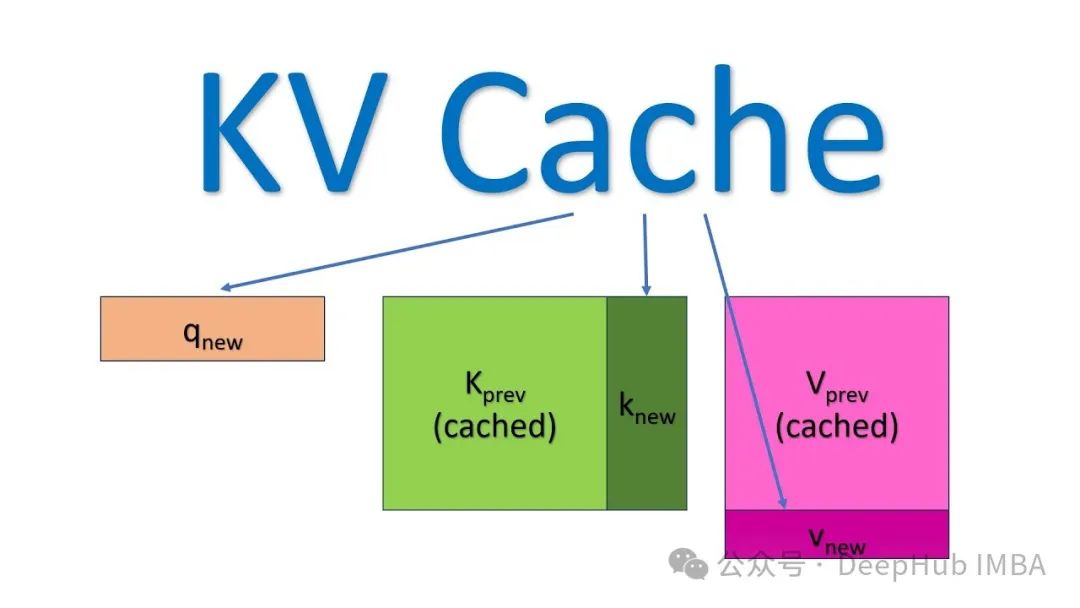
加速LLM大模型推理,KV缓存技术详解与PyTorch实现
本文详细阐述了KV缓存的工作原理及其在大型语言模型推理优化中的应用,文章不仅从理论层面阐释了KV缓存的工作原理,还提供了完整的PyTorch实现代码,展示了缓存机制与Transformer自注意力模块的协同工作方式。
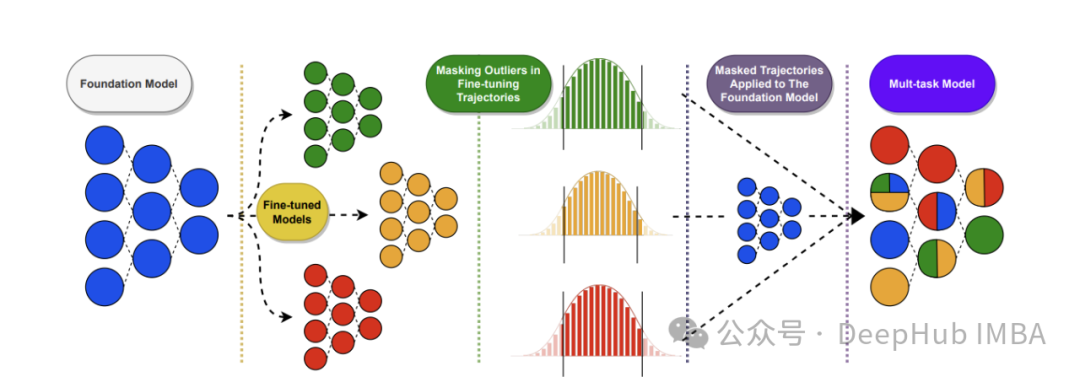
零训练成本优化LLM: 11种LLM权重合并策略原理与MergeKit实战配置
本文系统介绍了11种先进的LLM权重合并策略,从简单的线性权重平均到复杂的几何映射方法,全面揭示了如何在零训练成本下优化大语言模型性能。
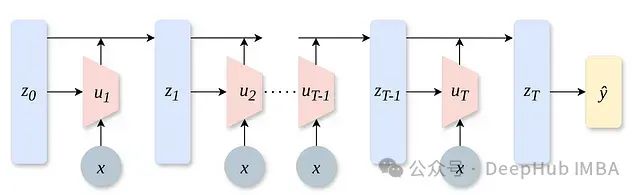
NoProp:无需反向传播,基于去噪原理的非全局梯度传播神经网络训练,可大幅降低内存消耗
NoProp的核心技术基于扩散模型的概念,通过训练网络的每一层**对注入噪声的目标标签实施去噪操作**,从而彻底重新构想了深度学习的基础训练范式。
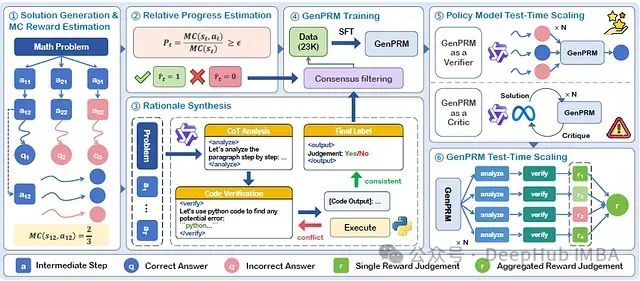
GenPRM:思维链+代码验证,通过生成式推理的过程奖励让大模型推理准确率显著提升
论文提出了GenPRM,一种创新性的生成式过程奖励模型。该模型在评估每个推理步骤前,先执行显式的思维链(Chain-of-Thought, CoT)推理并实施代码验证,从而实现对推理过程的深度理解与评估。
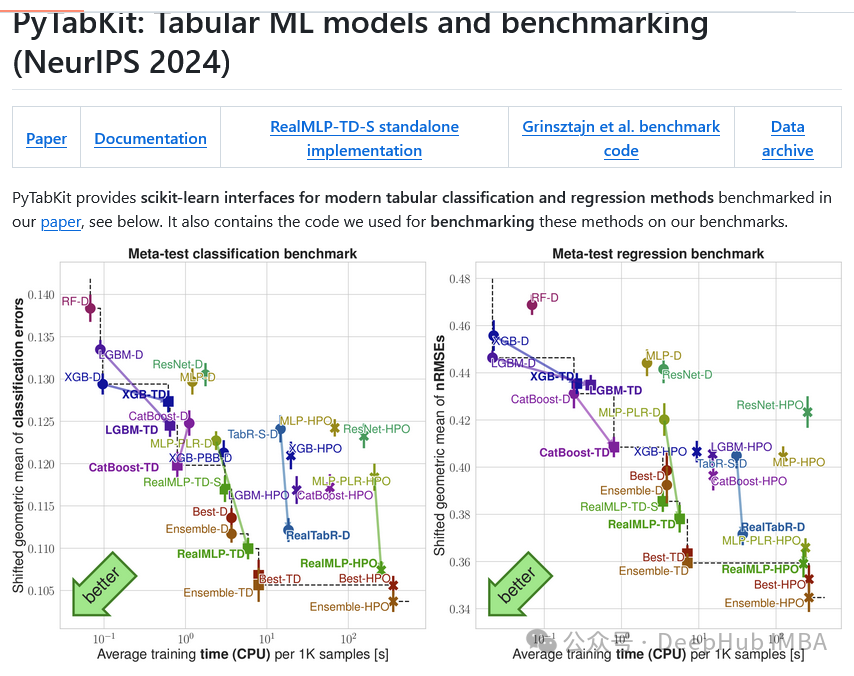
PyTabKit:比sklearn更强大的表格数据机器学习框架
**PyTabKit** 专为表格数据的分类和回归任务设计,集成了 **RealMLP** 等先进技术以及优化的梯度提升决策树(GBDT)超参数配置,为表格数据处理提供了新的技术选择。
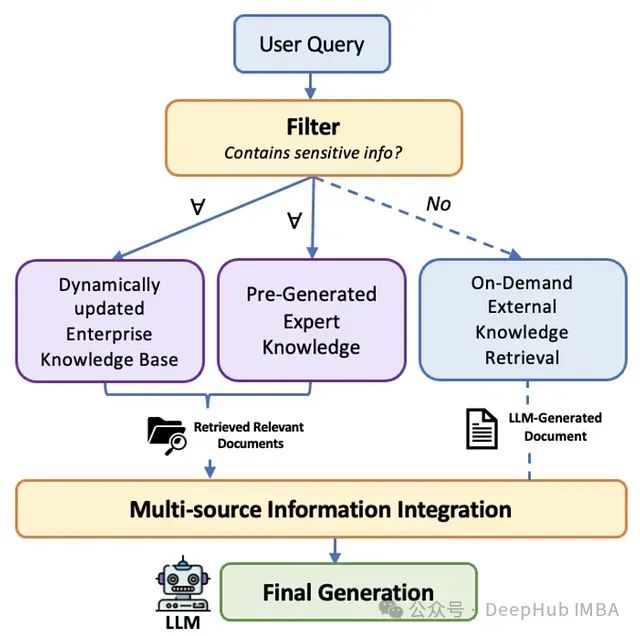
SecMulti-RAG:兼顾数据安全与智能检索的多源RAG框架,为企业构建不泄密的智能搜索引擎
本文深入剖析SecMulti-RAG框架,该框架通过集成内部文档库、预构建专家知识以及受控外部大语言模型,并结合保密性过滤机制,为企业提供了一种平衡信息准确性、完整性与数据安全性的RAG解决方案,同时有效控制部署成本。
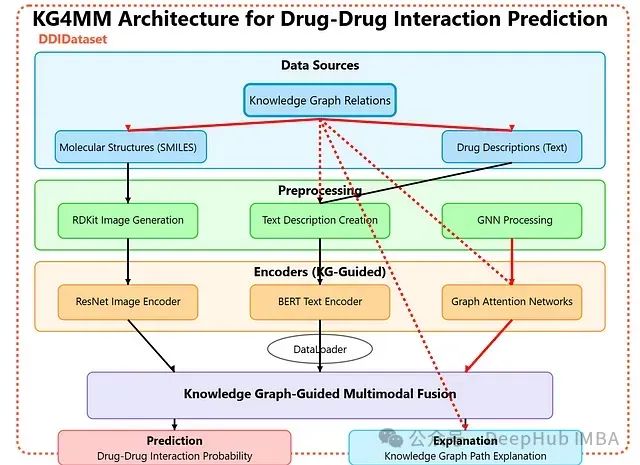

CLIMB自举框架:基于语义聚类的迭代数据混合优化及其在LLM预训练中的应用
CLIMB通过在语义空间中嵌入并聚类大规模数据集,并结合小型代理模型与性能预测器,迭代搜索最优数据混合比例。

10招立竿见影的PyTorch性能优化技巧,让模型训练速度翻倍
本文基于对多种模型架构、不同PyTorch版本和容器环境的实证测试,系统总结了PyTorch性能调优的关键技术,旨在帮助开发者构建高效、可扩展的深度学习应用。
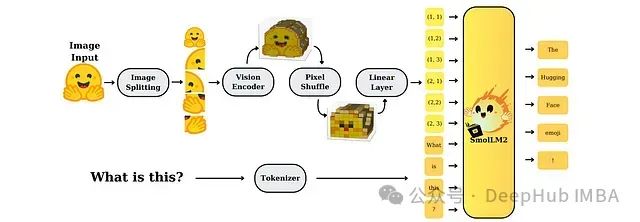
SmolVLM:资源受限环境下的高效多模态模型研究
SmolVLM是专为资源受限设备设计的一系列小型高效多模态模型。尽管模型规模较小,但通过精心设计的架构和训练策略,SmolVLM在图像和视频处理任务上均表现出接近大型模型的性能水平,为实时、设备端应用提供了强大的视觉理解能力。

从零开始用Pytorch实现LLaMA 4的混合专家(MoE)模型
我们将使用Pytorch逐步从零开始实现一个简化版的LLaMA 4 MoE模型。通过详细的代码实现和解释,我们将深入理解MoE架构的关键组件及其工作原理。
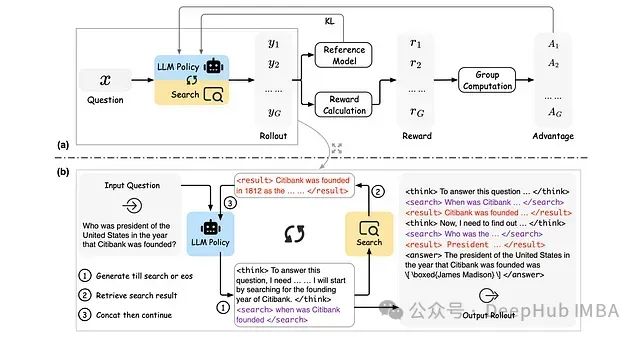
ReSearch:基于强化学习的大语言模型推理搜索框架
ReSearch是一种创新性框架,通过强化学习技术训练大语言模型执行"推理搜索",无需依赖推理步骤的监督数据。
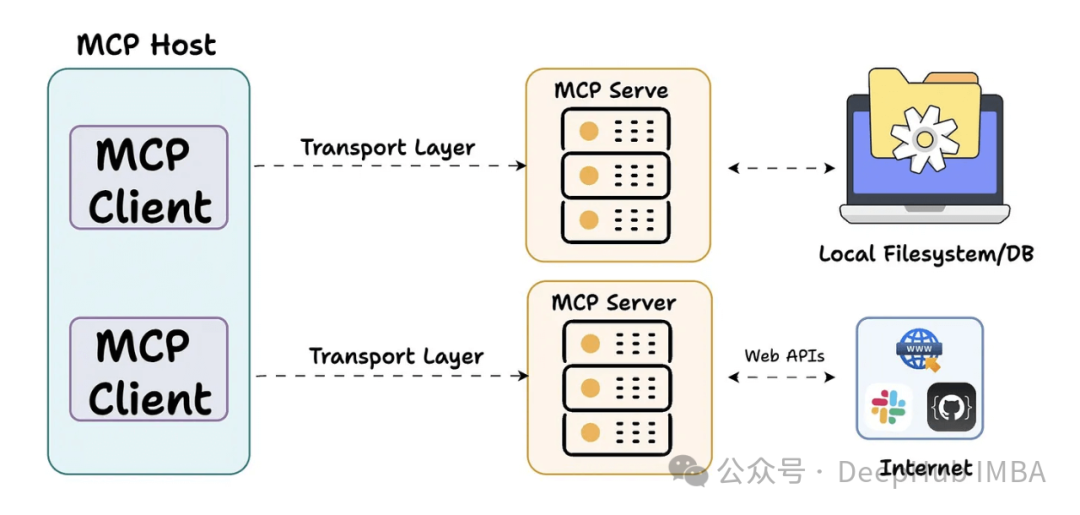
2025年GitHub平台上的十大开源MCP服务器汇总分析
本文深入分析GitHub平台上十个具有代表性的MCP服务器项目,这些技术方案正在重塑AI系统与外部环境的集成方式。
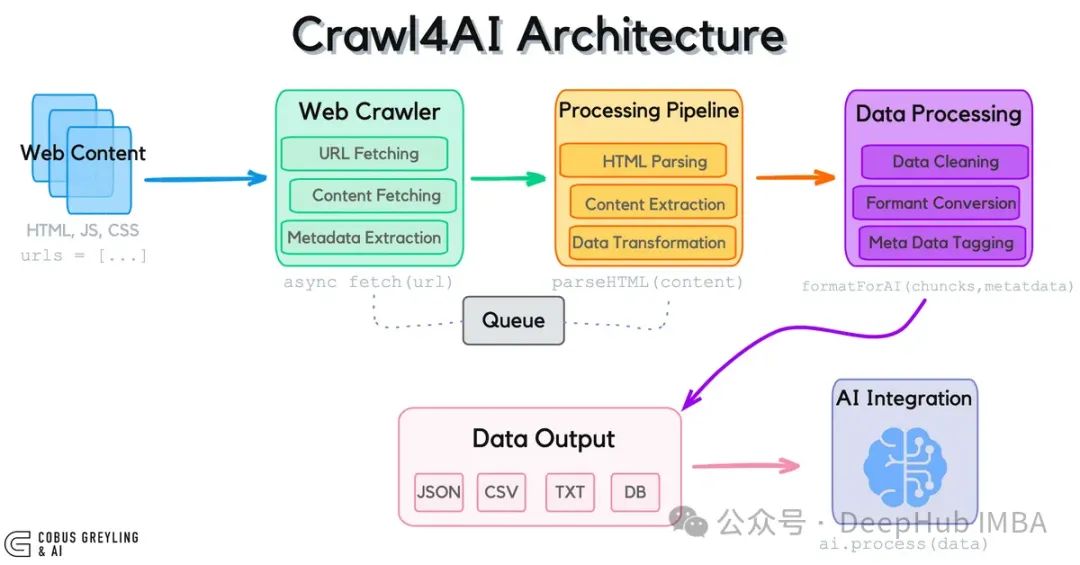
Crawl4AI:为大语言模型打造的开源网页数据采集工具
Crawl4AI作为专为大语言模型设计的开源网页数据采集工具,通过突破传统API限制,实现了对实时网页数据的高效获取与结构化处理。
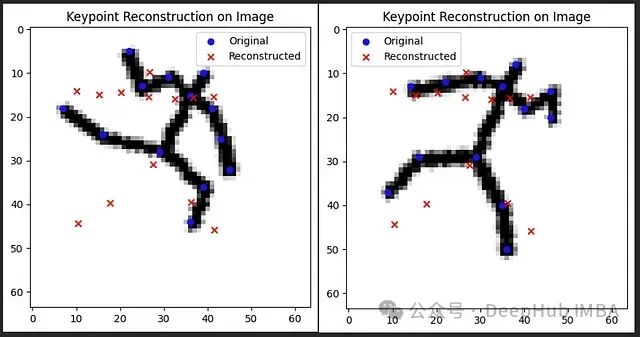
用离散标记重塑人体姿态:VQ-VAE实现关键点组合关系编码
本文构建了一个姿态重建模型,实现了上述概念。
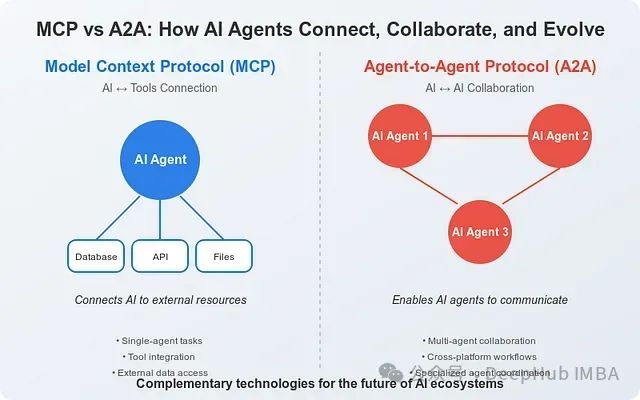
MCP与A2A协议比较:人工智能系统互联与协作的技术基础架构
本文综合分析基于Anthropic和Google的官方技术文档以及截至2025年4月的行业研究资料。



