
在当前大语言模型(LLM)应用开发的背景下,一个关键问题是如何评估模型输出的准确性。我们需要确定哪些评估指标能够有效衡量提示(prompt)的效果,以及在多大程度上需要对提示进行优化。
为解决这一问题,我们将介绍一个基于双代理的RAG(检索增强生成)评估系统。该系统使用生成代理和反馈代理,基于预定义的测试集对输出进行评估。或者更简单的说,我们使用一个模型来评估另外一个模型的输出。
在本文中将详细介绍如何构建这样一个RAG评估系统,并展示基于四种提示工程技术的不同结果,包括ReAct、思维链(Chain of Thought)、自一致性(Self-Consistency)和角色提示(Role Prompting)。
以下是该项目的整体架构图:

数据收集与摄入
此部分在 ingestion.py 中实现
数据收集过程使用了三篇文章作为源数据。在加载和分割数据后,我们对文本进行嵌入,并将嵌入向量存储在FAISS中。FAISS(Facebook AI Similarity Search)是由Meta开发的开源库,用于高效进行密集向量的相似性搜索和聚类。
以下是实现代码:
urls= [
"https://medium.com/@fareedkhandev/prompt-engineering-complete-guide-2968776f0431",
"https://medium.com/@researchgraph/prompt-engineering-21112dbfc789",
"https://blog.fabrichq.ai/what-is-prompt-engineering-a-detailed-guide-with-examples-4d3cbbd53792"
]
loader=WebBaseLoader(urls)
# 文本分割器
text_splitter=RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=20
)
documents=loader.load_and_split(text_splitter)
# LLM
embedder_llm=OpenAIModel().embed_model()
# 对文档块进行嵌入
vectorstore=FAISS.from_documents(documents, embedder_llm)
vectorstore.save_local("faiss_embed")
print("===== 数据摄入完成 ===== ")
创建测试集
此部分在 create_test_set.py 中实现
测试集的构建使用了Giskard工具。Giskard是一个开源工具,专为测试和改进机器学习模型而设计。它使用户能够创建、运行和自动化测试,以评估模型的性能、公平性和稳健性。
实现代码如下:
fromlangchain_community.document_loadersimportWebBaseLoader
fromlangchain.text_splitterimportRecursiveCharacterTextSplitter
# 用于构建测试集
fromgiskard.ragimportKnowledgeBase, generate_testset
# 数据框
importpandasaspd
fromLLM.modelsimportOpenAIModel
if__name__=='__main__':
urls= [
"https://medium.com/@fareedkhandev/prompt-engineering-complete-guide-2968776f0431",
"https://medium.com/@researchgraph/prompt-engineering-21112dbfc789",
"https://blog.fabrichq.ai/what-is-prompt-engineering-a-detailed-guide-with-examples-4d3cbbd53792"
]
loader=WebBaseLoader(urls)
# 文本分割器
text_splitter=RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=20
)
documents=loader.load_and_split(text_splitter)
df=pd.DataFrame([doc.page_contentfordocindocuments], columns=["text"])
print(df.head(10))
## 将数据框添加到giskard KnowledgeBase
knowledge_base=KnowledgeBase(df)
# 生成测试集
test_set=generate_testset(
knowledge_base,
num_questions=10,
agent_description="A chatbot answering question about prompt engineering"
)
test_set.save("test-set.jsonl")
由于文本太多,生成的样例就不显示了
答案检索
此部分在 generation.py 中实现
本文的第一个流程是生成流程。我们从FAISS检索数据。实现代码如下:
generate_llm=OpenAIModel().generate_model()
embedder_llm=OpenAIModel().embed_model()
vectorstore=FAISS.load_local("faiss_embed", embedder_llm, allow_dangerous_deserialization=True)
retrieval_qa_chat_prompt= (retrieval)
prompt=ChatPromptTemplate.from_messages(
[
("system", retrieval_qa_chat_prompt),
("human", "{input}"),
]
)
combine_docs_chain=create_stuff_documents_chain(generate_llm, prompt)
retrival_chain=create_retrieval_chain(
retriever=vectorstore.as_retriever(),
combine_docs_chain=combine_docs_chain
)
评估
此部分在 evaluation.py 中实现
评估过程中向LLM提供三个输入:问题、AI答案(第一个LLM的输出)和实际答案(从测试集中检索)。实现代码如下:
defRAG_eval(question, AI_answer, Actual_answer, prompt):
evaluation_prompt_template=PromptTemplate(
input_variables=[
"question", "AI_answer", "Actual_answer"
],
template=prompt
)
generate_llm=OpenAIModel().generate_model()
optimization_chain=evaluation_prompt_template|generate_llm|StrOutputParser()
result_optimization=optimization_chain.invoke(
{"question": question, "AI_answer": AI_answer, "Actual_answer": Actual_answer})
returnresult_optimization
链接整合
此部分在 main.py 中实现
主文件遍历测试数据,使用问题作为第一个LLM的输入。然后将第一个LLM的输出用作第二个LLM的输入。实现代码如下:
foritemindata:
question= {"input": item['question']}
# 生成回答
result=retrival_chain.invoke(input=question)
AI_answer=result['answer']
# 获取实际答案
Actual_answer=item['reference_answer']
# 将所有内容提供给第二个LLM
Evaluation=RAG_eval(
question=question,
AI_answer=AI_answer,
Actual_answer=Actual_answer,
prompt=evaluation_self_consistency_prompting
)
print(f"AI_answer:{AI_answer}")
print(Evaluation)
实验结果
评估组件采用了四种不同的提示工程技术:
- 思维链(Chain of Thought)
- ReAct
- 角色提示(Role Prompting)
- 自一致性(Self-Consistency)
以下是基于这四种不同提示技术的评估代理对测试集第一个问题的输出示例:
问题: What is the purpose of incorporating knowledge in prompt engineering?
实际答案: Incorporating knowledge or information in prompt engineering enhances the model’s prediction accuracy. By providing relevant knowledge or information related to the task at hand, the model can leverage this additional context to make more accurate predictions. This technique enables the model to tap into external resources or pre-existing knowledge to improve its understanding and generate more informed responses
AI答案:Incorporating knowledge in prompt engineering enhances the quality of responses by guiding AI models to provide not just answers, but also relevant context and insights. This leads to more informative and meaningful interactions, improving user experience and understanding.
使用思维链输出的评估结果:The student’s answer correctly identifies that incorporating knowledge enhances the quality of responses and improves user experience. However, it lacks emphasis on the model’s prediction accuracy and the importance of leveraging external resources or pre-existing knowledge, which are key components of the actual answer. This omission affects the completeness and correctness of the response.
使用ReAct输出的评估结果:The student’s answer correctly identifies that incorporating knowledge enhances the quality of responses and improves user experience. However, it lacks emphasis on the specific aspect of prediction accuracy and the importance of leveraging external resources or pre-existing knowledge, which are key components of the actual answer. This omission affects the completeness of the response, leading to a lower evaluation percentage.
使用角色提示输出的评估结果:The student’s response accurately captures the essence of incorporating knowledge in prompt engineering by emphasizing the enhancement of response quality and user experience. However, it lacks specific mention of prediction accuracy and the model’s ability to leverage external resources, which are key aspects of the actual response.
使用自一致性输出的评估结果:The student’s answer captures the essence of enhancing the quality of responses through knowledge incorporation, but it lacks specific mention of prediction accuracy and the model’s ability to leverage external resources. The initial evaluation was slightly optimistic, but upon reevaluation, it became clear that the answer did not fully align with the actual answer’s emphasis on prediction accuracy and context utilization
实验结果分析
下图展示了四种提示工程技术的准确性比较。每种技术由图中的一条独立线条表示,X轴上的10个数据点对应测试数据的索引值,Y轴表示准确性值。
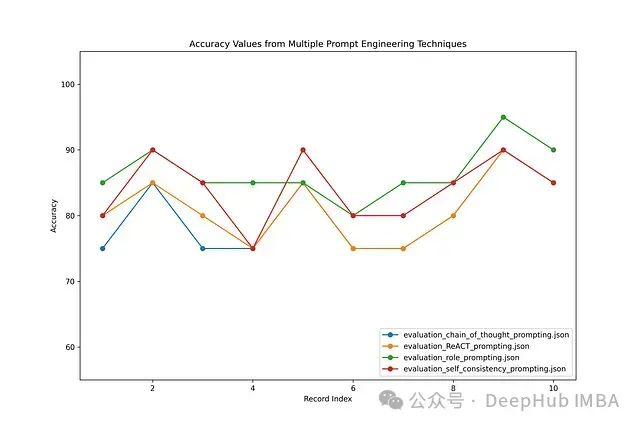
在评估过程中,准确性达到85%及以上的响应视为真正准确(True),低于85%则视为不准确(False)。下面的条形图展示了基于每种提示工程技术的评估结果中True和False的计数。
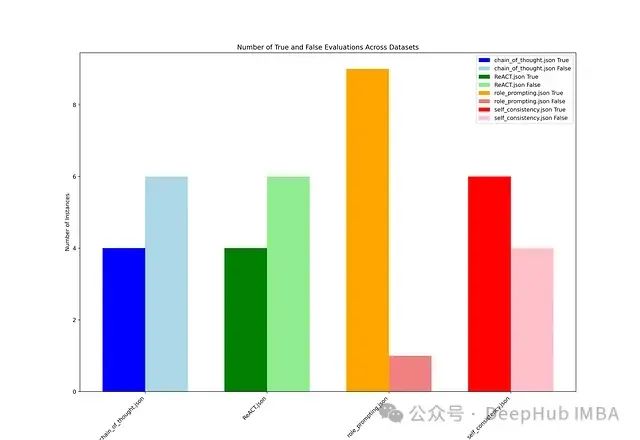
实验结果显示,ReAct和思维链(Chain of Thought)的性能几乎相似,而自一致性(Self-Consistency)则表现出完全相反的行为。角色提示(Role Prompting)在所有方法中表现最不稳定。
一些发现
- 评估代理的所有响应虽然在内容上相近,都提到了类似的缺失元素,但反馈之间的差异主要体现在具体措辞和强调点上,这些细微差别可能会对最终的评分过程产生影响。
- 角色提示和自一致性技术倾向于强调结果的积极方面,而ReAct和思维链则更多地使用特定措辞来突出回答中的缺失部分。
总结
本文展示了如何构建一个基于双代理的RAG(检索增强生成)评估系统,该系统使用两个大语言模型(LLM):一个用于生成响应,另一个用于提供反馈。通过采用四种不同的提示工程技术——思维链、ReAct、角色提示和自一致性,我们能够全面评估AI生成响应的准确性和质量。
实验结果表明:
- ReAct和思维链技术在性能上表现相似,这可能是因为它们都强调了结构化思考过程。
- 自一致性技术经常产生与其他方法相反的结果,这突显了在评估过程中考虑多个角度的重要性。
- 角色提示技术被证明是最不可靠的,这可能是由于其在不同上下文中的不一致性。
本文代码:
https://github.com/harrisonsrp/RAG_Evaluation
作者:Homayoun S.