LLM:模型微调经验
样本数量一般1万左右的高质量样本即可达到良好效果。对于简单任务,100-300条数据足够;中等难度任务需1000条以上;高难度任务需3000条甚至更多,可能达到10万条。样本质量样本质量优先于数量,高质量样本更有效。需要重点关注样本的多样性和答案质量。继续预训练当领域任务数据与预训练数据集差异较大时
【开源免费的 AI智能识别分析产品(通用识别、大模型加速器、文档格式转换、票据识别、图像智能处理、卡证识别)】
Textin.com 是一个集文本处理、分析、转换于一体的在线平台。它支持多种语言的文本处理,提供了诸如文本清洗、关键词提取、情感分析、文本翻译等功能。无论是数据分析师、市场研究人员,还是内容创作者,Textin.com 都能满足他们在文本处理方面的需求。文本清洗功能描述:去除文本中的噪声数据,如多
深度学习模型中的池化层
池化层(Pooling Layer)是卷积神经网络(CNN)中常用的一种操作,用于减少特征图的空间尺寸(即高度和宽度),从而减小模型的计算量和参数数量,同时保持重要的特征信息。池化层的主要作用包括降维、防止过拟合、提高计算效率以及增强特征的平移不变性。
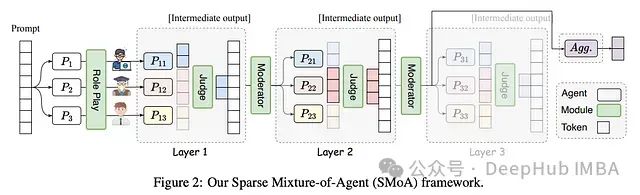
SMoA: 基于稀疏混合架构的大语言模型协同优化框架
通过引入稀疏化和角色多样性,SMoA为大语言模型多代理系统的发展开辟了新的方向。
通义千问AI PPT初体验:一句话、万字文档、长文本一键生成PPT!
通义千问AI PPT初体验:一句话、万字文档、长文本一键生成PPT!
Audio Spectrogram Transformer (AST)工作介绍
Audio Spectrogram Transformer (AST),是一种基于 Transformer 模型的音频分类方法。AST 利用了 Transformer 模型在捕获全局特征方面的优势,将音频信号转换为频谱图进行处理。本文是对 AST 及其相关研究工作的详细介绍。
【人工智能】掌握深度学习中的时间序列预测:深入解析RNN与LSTM的工作原理与应用
深度学习中的循环神经网络(RNN)和长短时记忆网络(LSTM)在处理时间序列数据方面具有重要作用。它们能够通过记忆前序信息,捕捉序列数据中的长期依赖性,广泛应用于金融市场预测、自然语言处理、语音识别等领域。本文将深入探讨RNN和LSTM的架构及其对序列数据进行预测的原理与优势,使用数学公式描述其内部
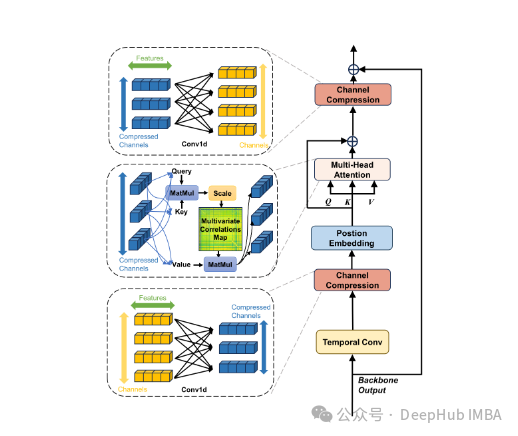
TSMamba:基于Mamba架构的高效时间序列预测基础模型
TSMamba通过其创新的架构设计和训练策略,成功解决了传统时间序列预测模型面临的多个关键问题。
序列到序列学习(Seq2seq)
(3)在选候选句子的时候,长句子往往预测的概率会更小一点,为了平衡选择的概率,有机会能尝到有机会能选到长一点的句子,通常是取一个log再取l的阿尔法次饭分之1去调整长句子的概率。这个向量空间是通过训练数据学习到的,向量的维度通常远小于词汇表的大小,生成的向量是密集的,维度通常远小于。(3)编码器通过
【深度学习实战】构建AI模型,实现手写数字自动识别
近年来,人工智能(AI)大模型在计算机科学领域引起了广泛的兴趣和关注。这些模型以其庞大的参数规模和卓越的性能,在各种领域展现了巨大的潜力。本文介绍如何构建一个AI模型,实现一个简单的手写数字识别任务。手写数字识别是一种利用计算机自动辨认人手写在纸张上的阿拉伯数字的技术。 这一技术属于光学字符识别
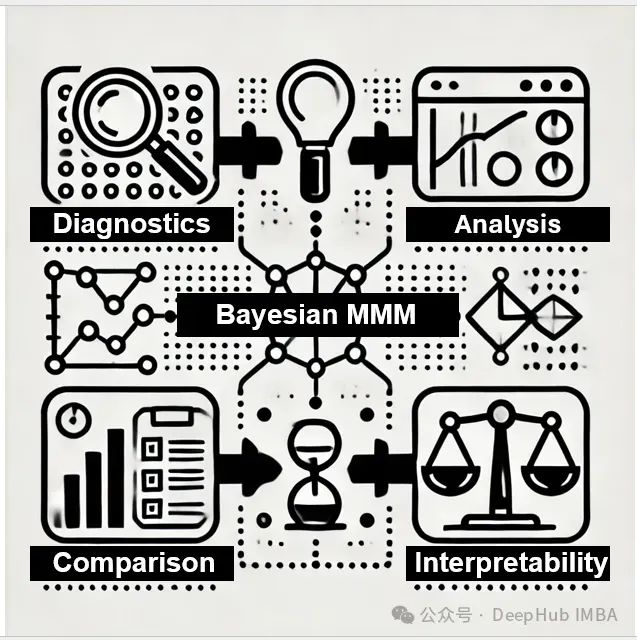
基于MCMC的贝叶斯营销组合模型评估方法论: 系统化诊断、校准及选择的理论框架
贝叶斯营销组合建模(Bayesian Marketing Mix Modeling,MMM)作为一种先进的营销效果评估方法,其核心在于通过贝叶斯框架对营销投资的影响进行量化分析。

深度学习工程实践:PyTorch Lightning与Ignite框架的技术特性对比分析
在深度学习框架的选择上,PyTorch Lightning和Ignite代表了两种不同的技术路线。本文将从技术实现的角度,深入分析这两个框架在实际应用中的差异,为开发者提供客观的技术参考。
海康威视 Vision Master 深度学习模块
Vision Master 深度学习模块
ConvGRU原理与开源代码
ConvGRU(卷积门控循环单元)是一种结合了卷积神经网络(CNN)和门控循环单元(GRU)的深度学习模型。与ConvLSTM类似,ConvGRU也主要用于处理时空数据,特别适用于需要考虑空间特征和时间依赖关系的任务,如视频分析、气象预测和交通流量预测等。
大模型-基于大模型的数据标注
法来自于这篇论文:Can Generalist Foundation Models Outcompete Special-Purpose Tuning?
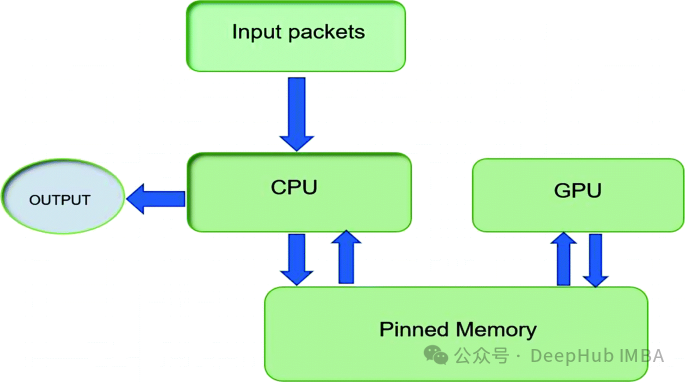
通过pin_memory 优化 PyTorch 数据加载和传输:工作原理、使用场景与性能分析
本文将深入探讨何时以及为何启用这一设置,帮助你优化 PyTorch 中的内存管理和数据吞吐量。
【AI论文精读5】知识图谱与LLM结合的路线图-P2
该论文提出了一个将大型语言模型(LLMs)与知识图谱(KGs)相结合的路线图。这是我对论文第2部分的解读。
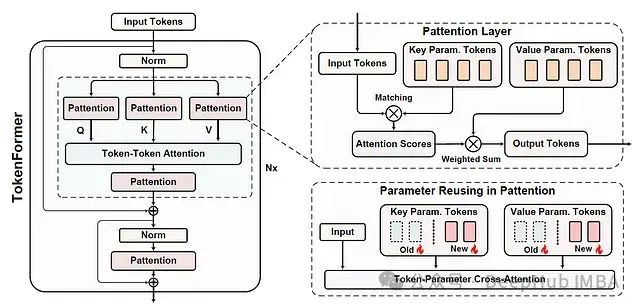
Tokenformer:基于参数标记化的高效可扩展Transformer架构
本文是对发表于arXiv的论文 "TOKENFORMER: RETHINKING TRANSFORMER SCALING WITH TOKENIZED MODEL PARAMETERS" 的深入解读与扩展分析。
【动物识别系统】Python+卷积神经网络算法+人工智能+深度学习+机器学习+计算机课设项目+Django网页界面
动物识别系统。本项目以Python作为主要编程语言,并基于TensorFlow搭建ResNet50卷积神经网络算法模型,通过收集4种常见的动物图像数据集(猫、狗、鸡、马)然后进行模型训练,得到一个识别精度较高的模型文件,然后保存为本地格式的H5格式文件。再基于Django开发Web网页端操作界面,实
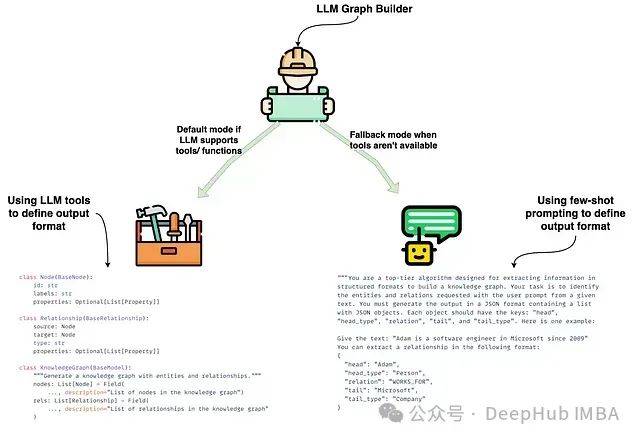
基于LLM Graph Transformer的知识图谱构建技术研究:LangChain框架下转换机制实践
本文是LangChain的一个代码贡献者编写的文章,将对这些内容进行详细介绍,文章最后还包含了作者提供的源代码



