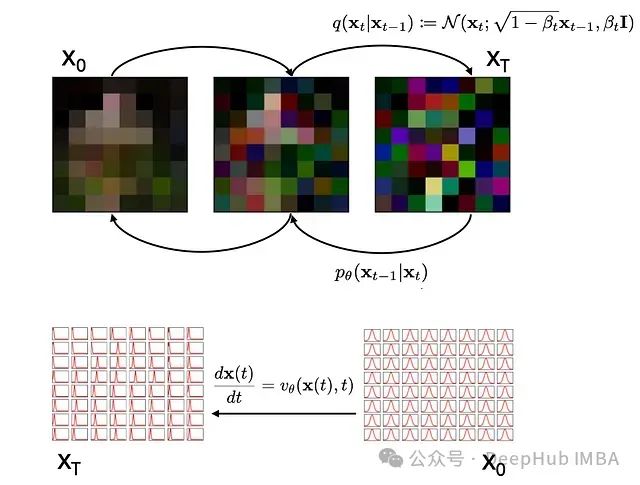
比扩散策略更高效的生成模型:流匹配的理论基础与Pytorch代码实现
扩散模型(Diffusion Models)和流匹配(Flow Matching)是用于生成高质量、连贯性强的高分辨率数据,,扩散实际上是流匹配的特例,流匹配作为一种更具普适性的方法

从零实现基于扩散模型的文本到视频生成系统:技术详解与Pytorch代码实现
本文详细介绍了基于扩散模型构建的文本到视频生成系统,展示了在MSRV-TT和Shutterstock视频标注数据集上训练的模型输出结果。以下是模型在不同提示词下的生成示例。
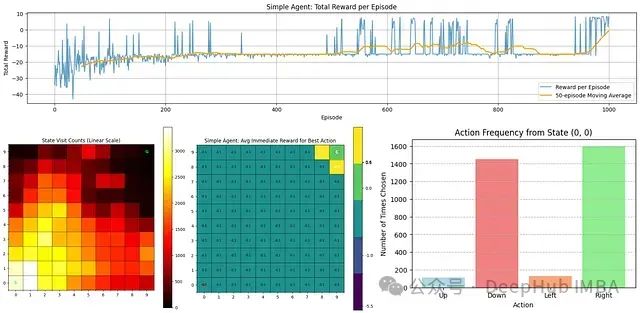
18个常用的强化学习算法整理:从基础方法到高级模型的理论技术与代码实现
本文系统讲解从基本强化学习方法到高级技术(如PPO、A3C、PlaNet等)的实现原理与编码过程,旨在通过理论结合代码的方式,构建对强化学习算法的全面理解。
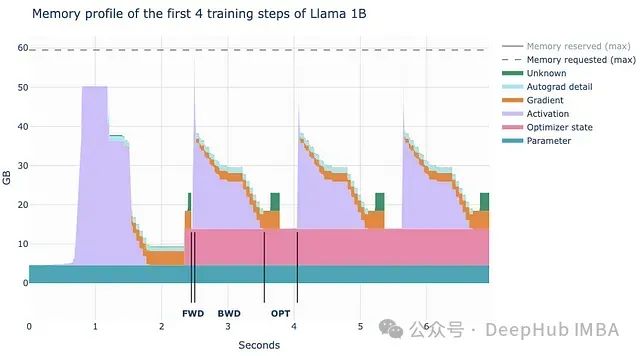
PyTorch CUDA内存管理优化:深度理解GPU资源分配与缓存机制
本文将深入剖析PyTorch如何优化GPU内存使用,以及如何通过定制其内部系统机制来充分发挥GPU集群的性能潜力。
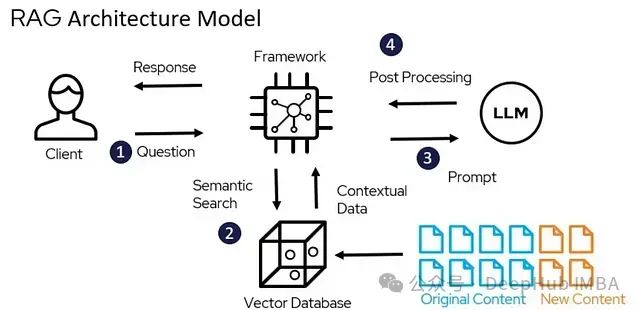
LangChain RAG入门教程:构建基于私有文档的智能问答助手
本文详述了如何通过检索增强生成(RAG)技术构建一个能够利用特定文档集合回答问题的AI系统。
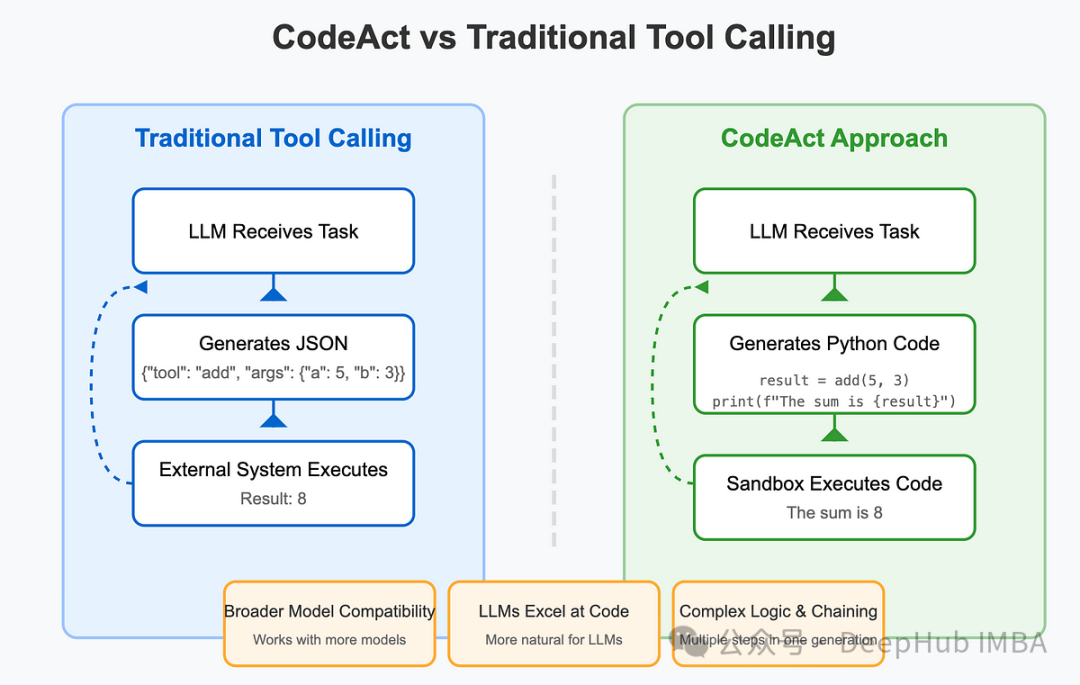
基于LlamaIndex实现CodeAct Agent:代码执行工作流的技术架构与原理
本文将详细阐述如何利用LlamaIndex框架从底层构建CodeAct Agent,深入剖析其内部工作机制,以及如何在预构建解决方案的基础上进行定制化扩展。

基于Transformer架构的时间序列数据去噪技术研究
本文将详细探讨一种基于Transformer架构的时间序列去噪模型的构建过程及其应用价值。

英伟达新一代GPU架构(50系列显卡)PyTorch兼容性解决方案
本文记录了在RTX 5070 Ti上运行PyTorch时遇到的CUDA兼容性问题,并详细分析了问题根源及其解决方案,以期为遇到类似情况的开发者提供参考。

FlashTokenizer: 基于C++的高性能分词引擎,速度可以提升8-15倍
FlashTokenizer是一款面向高性能计算的CPU分词引擎,专门针对BERT等Transformer架构的大型语言模型进行了底层优化。该引擎基于高效C++实现,采用了多项性能优化技术,确保在维持词元切分准确性的同时,大幅提升处理速度。
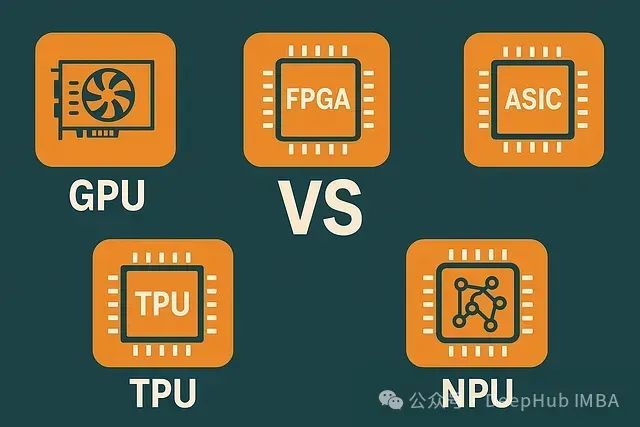
计算加速技术比较分析:GPU、FPGA、ASIC、TPU与NPU的技术特性、应用场景及产业生态
本文将深入剖析五类主要计算加速器——GPU、FPGA、ASIC、TPU和NPU,从技术架构、性能特点、应用领域到产业生态进行系统化比较,并分析在不同应用场景下各类加速器的适用性。
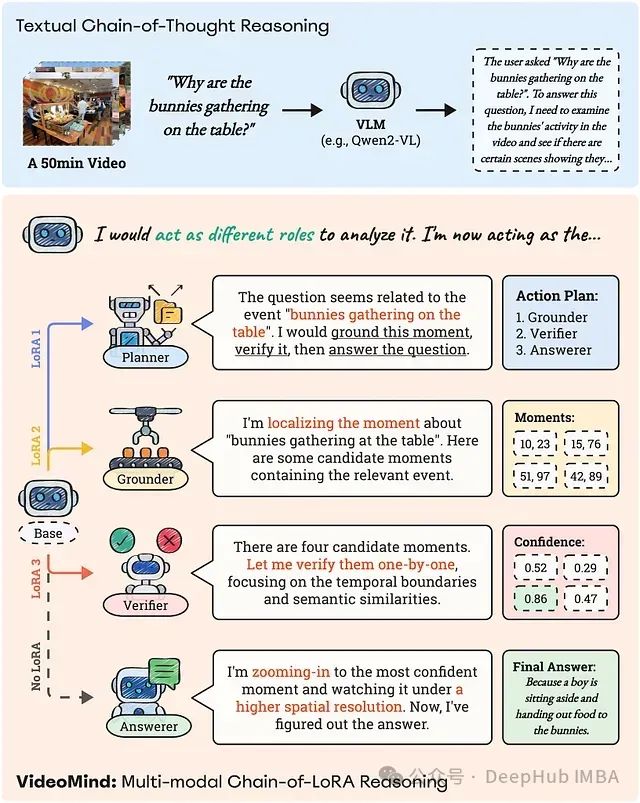
VideoMind:Chain-of-LoRA突破时间盲区让AI真正看懂长视频
**VideoMind** 是一种专为应对长视频中时间定位理解挑战而设计的新型视频语言代理。它不仅“观看”视频,还“分析”视频,采用一种结合了专门角色和名为 **Chain-of-LoRA** 的创新技术的策略。
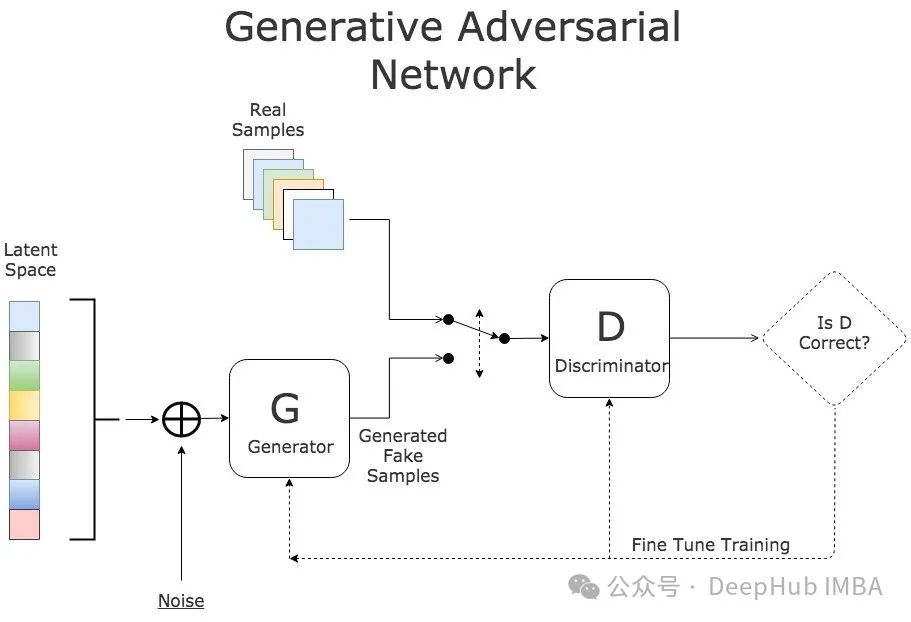
9个主流GAN损失函数的数学原理和Pytorch代码实现:从经典模型到现代变体
本研究首先介绍经典GAN损失函数的理论基础,随后使用PyTorch实现包括原始GAN、最小二乘GAN(LS-GAN)、Wasserstein GAN(WGAN)及带梯度惩罚的WGAN(WGAN-GP)在内的多种损失函数。
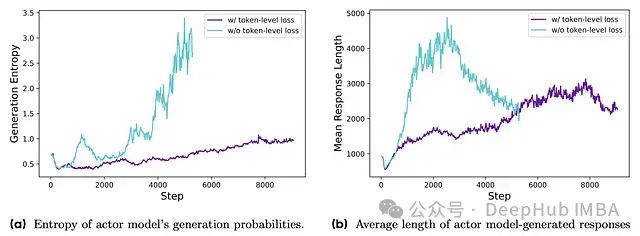
DAPO: 面向开源大语言模型的解耦裁剪与动态采样策略优化系统
字节跳动提出的解耦裁剪和动态采样策略优化(DAPO)算法,完整开源了一套最先进的大规模RL系统,该系统基于Qwen2.5-32B基础模型在AIME 2024测试中取得了50分的优异成绩。
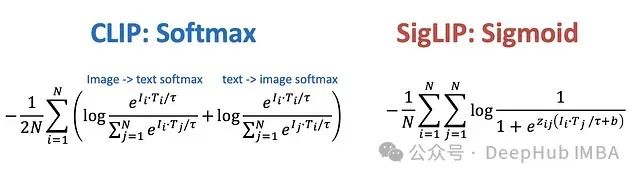
多模态AI核心技术:CLIP与SigLIP技术原理与应用进展
OpenAI提出的CLIP和Google研发的SigLIP模型重新定义了计算机视觉与自然语言处理的交互范式,
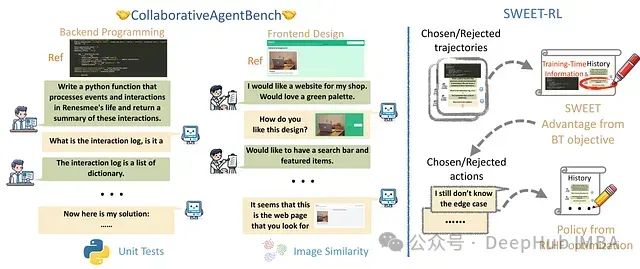
SWEET-RL:基于训练时信息的多轮LLM代理强化学习框架
本文将深入分析SWEET-RL如何改进AI代理在复杂协作任务中的训练方法。
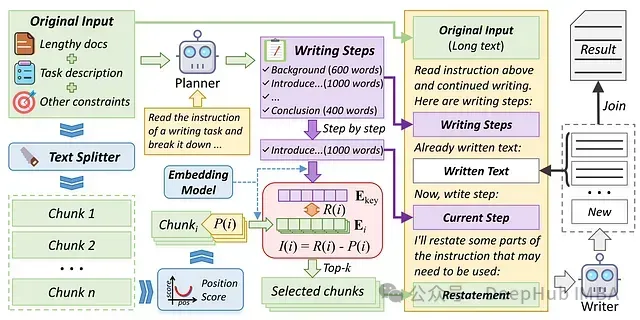
RAL-Writer Agent:基于检索与复述机制,让长文创作不再丢失关键信息
RAL-Writer Agent是一种专业的人工智能写作辅助技术,旨在解决生成高质量、内容丰富的长篇文章时所面临的技术挑战,确保全文保持连贯性和相关性。

SANA-Sprint:基于连续时间一致性蒸馏的单步扩散模型,0.1秒即可生成图像
Nvidia 提出的 SANA-Sprint 是一种**混合蒸馏框架**,它整合了**连续时间一致性模型 (sCM)** 和 **潜在对抗扩散蒸馏 (LADD)**,

广义优势估计(GAE):端策略优化PPO中偏差与方差平衡的关键技术
GAE的理论基础建立在资格迹(eligibility traces)和时序差分λ(TD-λ)之上,是近端策略优化(PPO)算法的重要基础理论
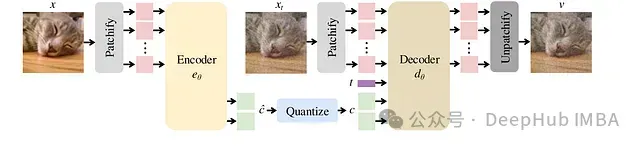
FlowMo: 模式搜索+扩散模型提升图像Token化性能
这个研究提出了FlowMo,一种基于Transformer的扩散自编码器,在多种比特率条件下实现了图像Token化的最新技术水平
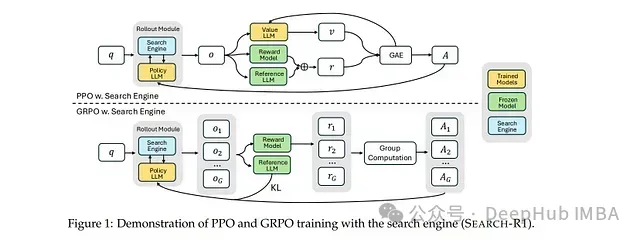
SEARCH-R1: 基于强化学习的大型语言模型多轮搜索与推理框架
该模型的核心创新在于**完全依靠强化学习机制(无需人工标注的交互轨迹)**来学习最优的搜索查询策略及基于检索知识的推理方法,从而显著提升问答任务的性能表现。



