机器学习多分类器有哪些
多类支持向量机的另一种改进方法——二次共轭损失函数的支持向量机分类器(Quadratic Conjugate Loss Function Support Vector Machine Multi-Classifier,QCLF-SVM-MC)多类支持向量机分类器的一种改进方法——总损失函数的支持向量
深度学习模型组件系列二:最常用的特征提取器
深度学习模型组件的特折提取器
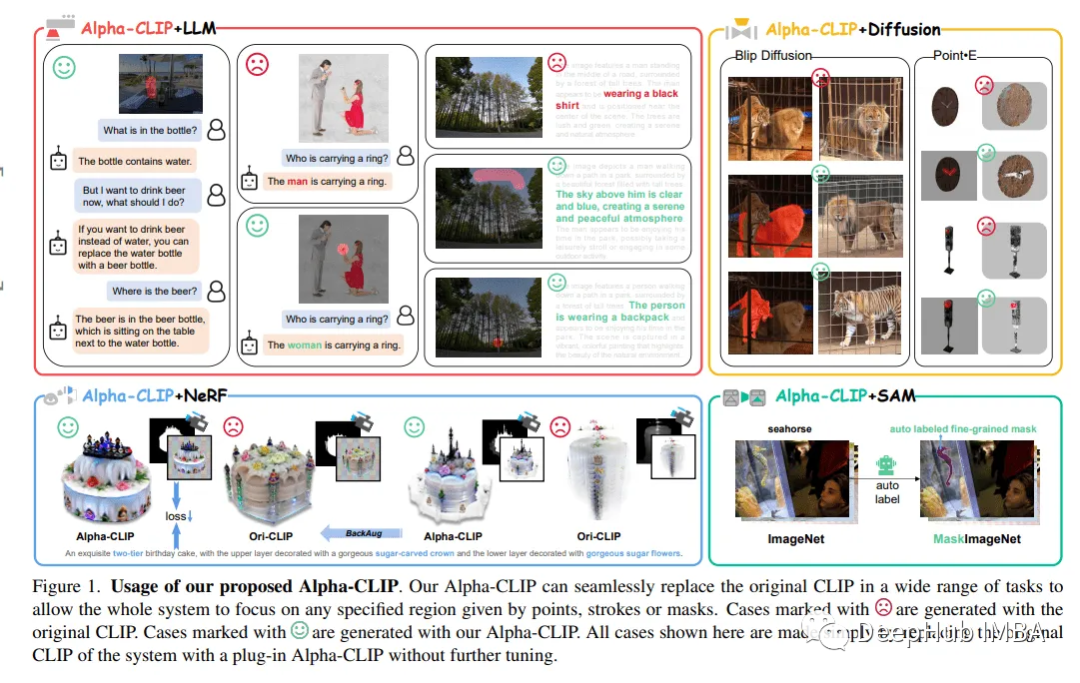
CLIP的升级版Alpha-CLIP:区域感知创新与精细控制
Alpha-CLIP不仅保留了CLIP的视觉识别能力,而且实现了对图像内容强调的精确控制,使其在各种下游任务中表现出色。
ID3 决策树的原理、构造及可视化(附完整源代码)
【2022.10】ID3 决策树的原理、构造及可视化(附完整源代码)
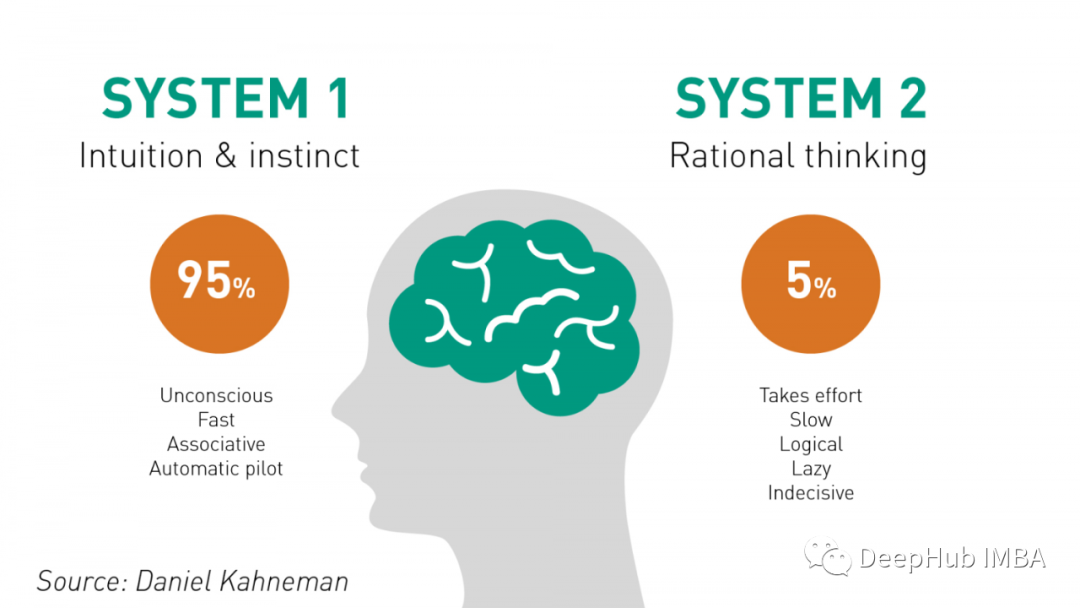
System 2 Attention:可以提高不同LLM问题的推理能力
S2A是LLM推理方法发展的一个重要里程碑。该方法与人类推理非常相似,避免了干扰。我们应该期待S2A在最近几个月成为推理研究的重要基线。
机器学习:ROC曲线
本篇博客从概念、原理、应用和与AUC值相关的知识点四个方面介绍了ROC曲线的基本知识,并给出了Python实现的示例。尽管ROC曲线不能完全衡量分类器的性能,但是它仍然是一个非常重要的评估指标,可以帮助我们选择更好的分类器模型,提高机器学习的效果和准确率。
【文本生成评价指标】 ROUGE原理及代码示例py
代码演示了如何使用 Python 中的 rouge 库来计算生成文本和参考文本之间的 ROUGE 指标,以评估文本生成算法的质量。
Matplotlib中的titles(标题)、labels(标签)和legends(图例)
本文讨论Python的Matplotlib绘图库中可用的不同标记选项。
语义分割之RandLANet深度解读
语义分割任务是计算机视觉里的一个比较基础的任务,其相比于物体检测任务主要有以下几个优点:输出的结果是稠密的,是针对于所有像素点的K分类问题,物体检测任务只输出前景类物体的信息忽略了背景点的信息在自动驾驶任务中可以实现可行驶区域的识别,大部分区域都是以背景的形式存在,而这些背景同样是非行驶区域可以输出
梯度消失与梯度爆炸产生、原理和解决方案
本文章总结了梯度消失与梯度爆炸产生、原理和解决方案。
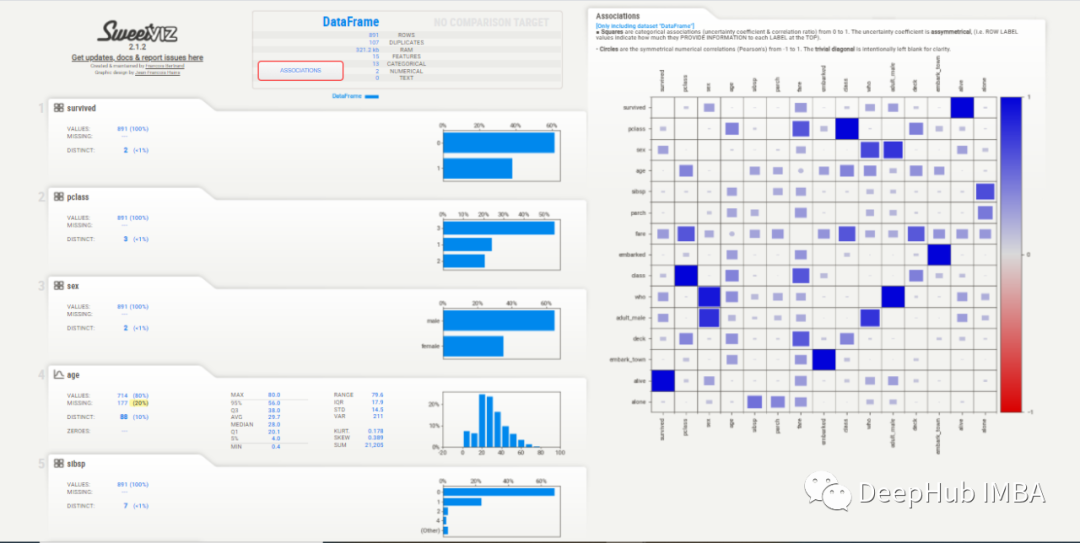
2023年5个自动化EDA库推荐
EDA或探索性数据分析是一项耗时的工作,但是由于EDA是不可避免的,所以Python出现了很多自动化库来减少执行分析所需的时间。
中科大2023春季【高级人工智能】试题回顾
记得不是很清楚了,但是可以大概回忆一下(0-o)题型还是填空+判断+简答+计算考了信息熵公式,搜索问题的五要素,hingeloss公式,SVM优化目标函数,约束求解问题的(X,D,C)的含义。无限集合有k个球,球的分布是什么样子的时候熵最大。迭代深度优先搜搜的时空复杂度。决策树通过什么防止过拟合。(
ADMM算法系列1:线性等式或不等式约束下可分离凸优化问题的ADMM扩展
推导过程也很简单就是在原始ADMM算法的基础上去掉常数项演变而来,它的收敛性证明便遵循了上面所阐述的收敛性路线图,即先找到它的变分不等式然后凑出收敛性证明的预测校正框架即可。在此基础上,可以设计一系列具体的基于ADMM的算法,这些算法在预测校正结构中具有可证明的收敛性。这里就和前文对应了,主要是想说
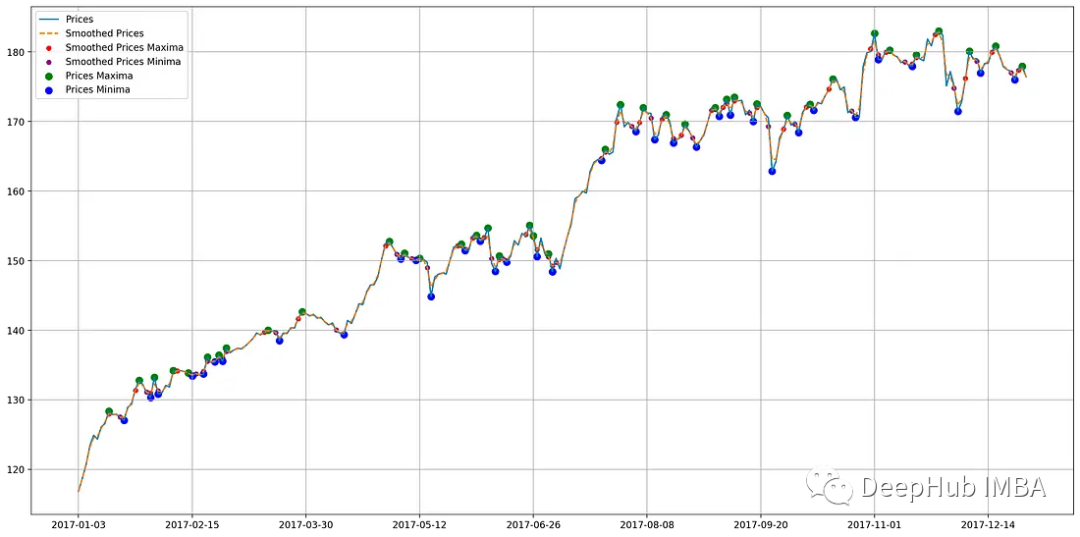
使用Python代码识别股票价格图表模式
在股票市场交易的动态环境中,技术和金融的融合催生了分析市场趋势和预测未来价格走势的先进方法。本文将使用Python进行股票模式识别。
机器学习|优化算法 | 评估方法|分类模型性能评价指标 | 正则化
机器学习|正则化|评估方法|分类模型性能评价指标|吴恩达学习笔记(哔哩哔哩视频and课堂PPT笔记梳理)
人工智能 - 人脸识别:发展历史、技术全解与实战
本文全面探讨了人脸识别技术的发展历程、关键方法及其应用任务目标,深入分析了从几何特征到深度学习的技术演进。

4个解决特定的任务的Pandas高效代码
在本文中,我将分享4个在一行代码中完成的Pandas操作。这些操作可以有效地解决特定的任务,并以一种好的方式给出结果。
【PyTorch】第六节:乳腺癌的预测(二分类问题)
上一个实验我们讲解了线性问题的求解步骤,本实验我们以乳腺癌的预测为实例,详细的阐述如何利用 PyTorch 求解一个非线性问题。
单位冲激函数与单位阶跃函数
本节主要介绍另外两个基本信号,在连续时间和离散时间情况下的单位阶跃和单位冲激函数,在信号与系统的分析中很重要。
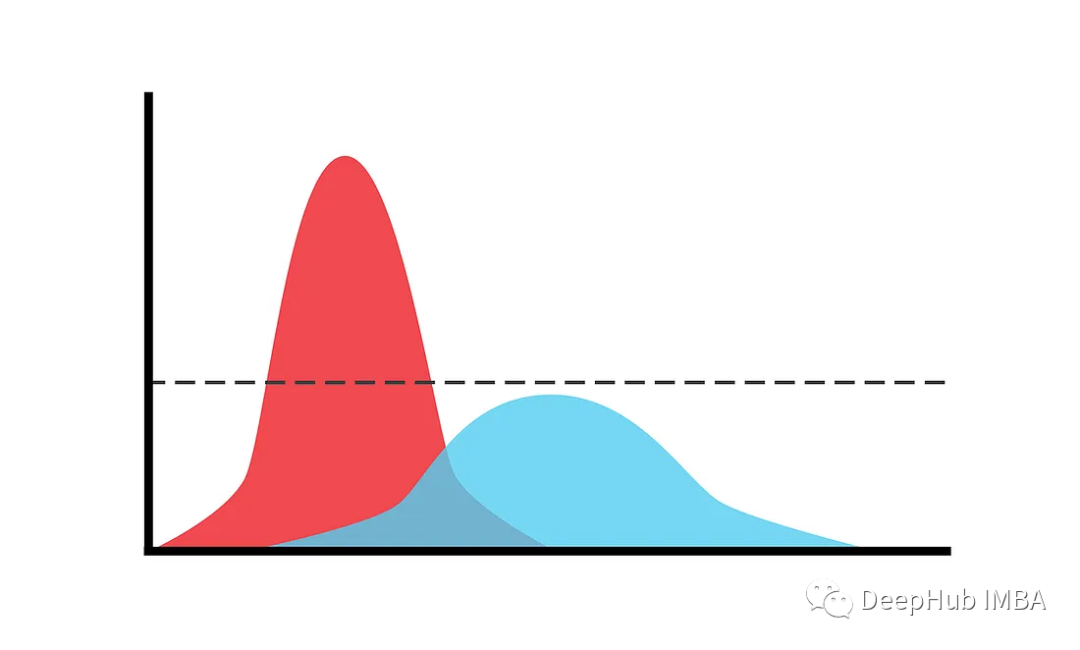
高斯混合模型:GMM和期望最大化算法的理论和代码实现
高斯混合模型(gmm)是将数据表示为高斯(正态)分布的混合的统计模型。这些模型可用于识别数据集中的组,并捕获数据分布的复杂、多模态结构。



