【古诗生成AI实战】之五——加载模型进行古诗生成
这部分是项目中非常激动人心的一环,因为我们将看到我们的模型如何利用先前学习的知识来创造出新的古诗文本。这是一个重要的里程碑,因为训练好的模型是我们进行文本生成的基础。* 生成文本:从初始文本(例如“天”)开始,逐字生成新的文本,直到达到指定长度(如32个字符)。在这部分内容中,我们将探讨如何使用预训
机器学习可解释性一(LIME)
对于机器学习的用户而言,模型的可解释性是一种较为主观的性质,我们无法通过严谨的数学表达方法形式化定义可解释性。通常,我们可以认为机器学习的可解释性刻画了“人类对模型决策或预测结果的理解程度”,即用户可以更容易地理解解释性较高的模型做出的决策和预测。从哲学的角度来说,为了理解何为机器学习的可解释性,我
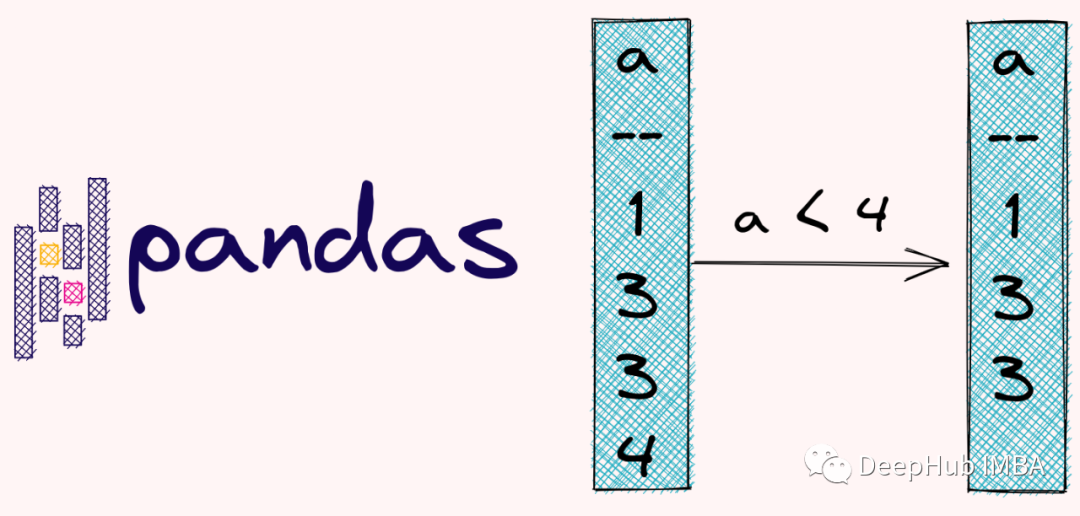
Pandas中选择和过滤数据的终极指南
本文将介绍使用pandas进行数据选择和过滤的基本技术和函数。无论是需要提取特定的行或列,还是需要应用条件过滤,pandas都可以满足需求。
[log_softmax]——深度学习中的一种激活函数
具体来说,在模型训练过程中,[log_softmax]可以被当作是损失函数的一部分,用于计算预测值与真实值之间的距离。在深度学习中,我们需要将神经网络的输出转化为预测结果,而由于输出值并非总是代表着概率,因此我们需要使用激活函数将其转化为概率值。总结来说,[log_softmax]是深度学习中非常重
人工智能 - 图像分类:发展历史、技术全解与实战
在本文中,我们深入探讨了图像分类技术的发展历程、核心技术、实际代码实现以及通过MNIST和CIFAR-10数据集的案例实战。文章不仅提供了技术细节和实际操作的指南,还展望了图像分类技术未来的发展趋势和挑战。
深入探讨机器学习中的过拟合现象及其解决方法
真正喜欢的人和事都值得我们去坚持。

使用Accelerate库在多GPU上进行LLM推理
本文将使用多个3090将llama2-7b的推理扩展在多个GPU上
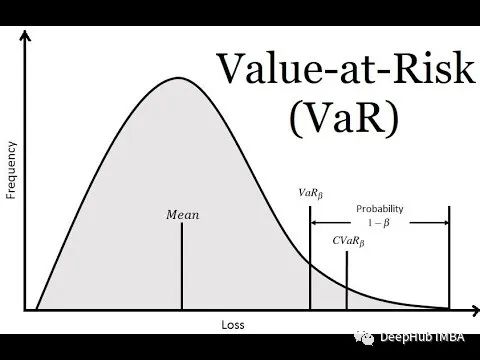
三种常用的风险价值(VaR)计算方法总结
风险价值(VaR)是金融领域广泛使用的风险度量,它量化了在特定时间范围内和给定置信度水平下投资或投资组合的潜在损失。
MNIST数据集ubyte格式数据解析
MNIST数据集格式解析
使用skforecast进行时间序列预测
在本文中,将介绍skforecast并演示了如何使用它在时间序列数据上生成预测。skforecast库的一个有价值的特性是它能够使用没有日期时间索引的数据进行训练和预测。
多模态技术综述
多模态机器学习是对计算机算法的研究,通过使用多模态数据集来学习和提高性能。多模式深度学习是一个机器学习子领域,旨在训练人工智能模型来处理和找到不同类型的数据(模式)之间的关系,通常是图像、视频、音频和文本。通过组合不同的模式,深度学习模型可以更普遍地理解其环境,因为一些线索只存在于某些模式中。想象一
详细介绍BFGS算法
在minimize函数中,我们指定了初始点theta0、使用BFGS算法求解(method='BFGS')、使用线性回归模型的梯度(jac=linear_regression_grad)以及一些其他的参数选项(options={'disp': True})。在minimize函数中,我们指定了初始点
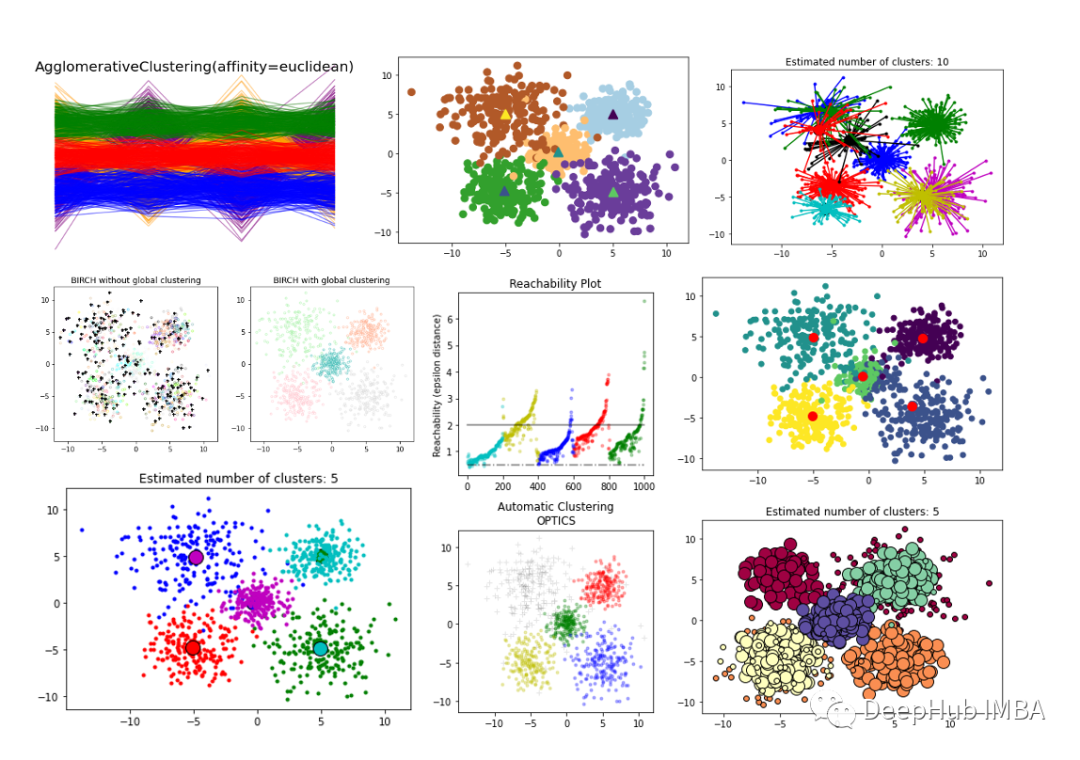
6个常用的聚类评价指标
评估聚类结果的有效性,即聚类评估或验证,对于聚类应用程序的成功至关重要。
Azure Machine Learning - Azure AI 搜索中的矢量搜索
矢量搜索是一种信息检索方法,它使用内容的数字表示形式来执行搜索方案。 由于内容是数字而不是纯文本,因此搜索引擎会匹配与查询最相似的矢量,而不需要匹配确切的字词。本文简要介绍了 Azure AI 搜索中的矢量支持。 其中还解释了与其他 Azure 服务的集成,以及与矢量搜索开发相关的术语和概念
人工智能中的文本分类:技术突破与实战指导
在本文中,我们全面探讨了文本分类技术的发展历程、基本原理、关键技术、深度学习的应用,以及从RNN到Transformer的技术演进。文章详细介绍了各种模型的原理和实战应用,旨在提供对文本分类技术深入理解的全面视角。
PCA主成成分分析例题详解
主成分分析是一种降维算法,它能将多个指标转换为少数几个主成分,这些主成分是原始变量的线性组合,且彼此之间互不相关,其能反映出原始数据的大部分信息。
不确定性系统建模
不确定度可分为扰动信号和动态扰动两类。这种差异的典型来源包括未建模(通常是高频)动力学、建模中被忽视的非线性、故意简化模型的影响,以及由于环境变化和磨损因素引起的系统参数变化。usys = ucover(Parray,Pnom,ord)返回一个标称值为Pnom的不确定模型usys,其行为范围包括LT
AutoGluon安装及示例
Autogluon的发明人是李沐(Mu Li)和他在亚利桑那州立大学的研究团队。Autogluon是一种**自动化机器学习工具**, 可以同时支持两种模式:**迁移学习模式**和**自动机器学习模式**。
基于python的点云处理库总结
该软件包提供了Pythonic的,文档齐全的界面,该界面公开了VTK强大的可视化后端,以促进对空间参考数据集的快速原型制作,分析和可视化集成。Open3D的依赖项较少,可在不同的平台上编译与布置。/* ************************************** 以下的已经不维护或者
如何解决ChatGPT网络错误的问题,让AI对话更丝滑~
在当今人工智能技术的飞速发展中,ChatGPT 作为一款大型语言模型备受瞩目。近期,其在各大社交媒体平台上的表现更是引来了一片关注之声。无论是与用户进行有趣的对话,还是帮助人们解决实际问题,ChatGPT 展现出了其强大的自然语言处理能力和智能应用潜力。很多小伙伴都跃跃欲试,争先恐后体验一把与「人工



