人工智能福利站,初识人工智能,机器学习,第五课
在强化学习中,价值函数(Value Function)和策略函数(Policy Function)是两个核心概念,用于描述智能体在环境中的行为决策过程。价值函数:价值函数用于评估在给定策略下,智能体在不同状态或状态动作对上的价值。它表示的是从当前状态出发,智能体能够获取到的未来奖励的总和或期望值。a
Elasticsearch的机器学习与AI整合
1.背景介绍Elasticsearch是一个分布式、实时的搜索和分析引擎,它可以处理大量数据并提供快速、准确的搜索结果。在大数据时代,Elasticsearch在搜索、分析和机器学习等领域发挥了广泛的应用。本文将从以下几个方面进行阐述:背景介绍核心概念与联系核心算法原理和具体操作步骤以及数学模型公式
数据预处理和特征工程在AI大模型中的重要性
1.背景介绍在AI领域,数据预处理和特征工程是构建高性能模型的关键环节。在本文中,我们将深入探讨数据预处理和特征工程在AI大模型中的重要性,并揭示一些最佳实践、技巧和技术洞察。1. 背景介绍AI大模型通常需要处理大量、复杂的数据,以实现高性能和准确度。数据预处理和特征工程是将原始数据转换为模型可以理
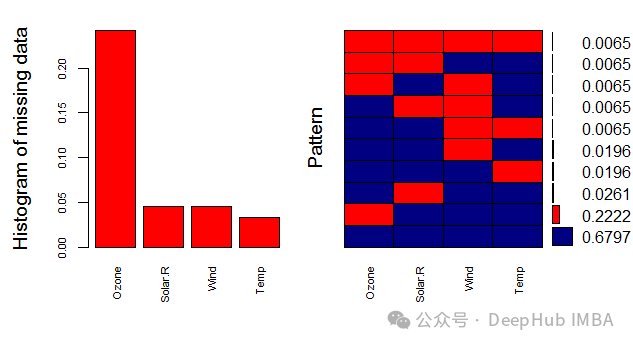
使用MICE进行缺失值的填充处理
MICE(Multiple Imputation by Chained Equations)是一种常用的填充缺失数据的技术。它通过将待填充的数据集中的每个缺失值视为一个待估计的参数,然后使用其他观察到的变量进行预测。

使用PyOD进行异常值检测
异常值检测各个领域的关键任务之一。PyOD是Python Outlier Detection的缩写,可以简化多变量数据集中识别异常值的过程。在本文中,我们将介绍PyOD包,并通过实际给出详细的代码示例
【机器学习】1、AI鲜为人知的秘密:机器学习与深度学习概论
讲解人工智能、机器学习、深度学习三者的概念和定义,并解释一些基本术语
人工智能与机器学习的学习效率:未来技术趋势分析
1.背景介绍随着数据的爆炸增长和计算能力的持续提升,人工智能(AI)和机器学习(ML)技术在各个领域的应用也不断扩大。然而,面对复杂的数据和任务,传统的机器学习方法已经无法满足需求。因此,提高机器学习的学习效率成为了一个重要的研究方向。在这篇文章中,我们将从以下几个方面进行探讨:背景介绍核心概念与联
AI:123-基于机器学习的行人行为分析与异常检测
人工智能(AI)在各个领域都展现出强大的潜力,其中之一是在城市智能监控系统中应用机器学习技术进行行人行为分析与异常检测。通过深度学习和计算机视觉的结合,我们能够更精准地理解和预测行人的行为,从而提高城市安全性。本文将深入探讨这一方向,并提供相应的代码实例。
人工智能、机器学习与深度学习之间的关系
在我们深入研究机器学习和深度学习之前,让我们快速浏览一下它们所属的分支:人工智能(AI)。简而言之,人工智能是一个将计算机科学与大量数据相结合以帮助解决问题的领域。人工智能有许多不同的用例。图像识别,图像分类,自然语言处理,语音识别,面部识别等。人工智能主要有两种类型:弱人工智能和强人工智能。弱人工

2024年应该关注的十大人工智能创新
今年是大年初一,我们将探讨2024年可能出现的十大人工智能创新,拥抱这些即将到来的人工智能创新,可以为一个充满激动和变革的未来做好准备。
2024-01-06-AI 大模型全栈工程师 - 机器学习基础
2024-01-06 阴 杭州 晴本节简介:a. 数学模型&算法名词相关概念;b. 学会数学建模相关知识;c. 学会自我思考,提升认知,不要只会模仿;a. 模型是一个函数(一种逻辑实现)a.1 接受一定范围内的参数;a.2 预测输出;b. 模型训练是什么?b.1 我们有一系列的入参
【人工智能】人工智能 – 引领未来科技的潮流
通过制定合理的政策和规范,我们可以确保人工智能技术在促进社会发展的同时,保护每个人的权益,共创一个更加美好的未来。自1956年人工智能这一概念提出以来,这一领域经历了多次起伏,但近年来由于计算能力的大幅提升和数据量的爆炸性增长,人工智能技术取得了飞速发展。从智能助手到自动驾驶汽车,从机器人工程师到智
AI股票崩盘预测模型(企业建模_论文科研)ML model for stock crash prediction
在美国,FICO 评分,通常称为信用评分,是一个三位数的数字,用于评估一个人在获得信用卡或贷方贷款时偿还信用的可能性。这种大量抛出证券的现象也称为卖盘大量涌现。用户输入股票名字,软件自动输出股票信用分数,散户和机构就可以购买信用分数高的股票,避开信用分数低的股票,进而减少投资风险。我方模型可以部署到
AI智能问答系统(2):技术架构
(4)CPU后端CPU后端 'cpu'是性能最低但最简单的后端,所有运算均在普通的JavaScript中实现,这使它们的可并行性较差,这些运算还会阻塞界面线程。CPU后端对于测试或在 WebGL不可用的设备上非常有用。
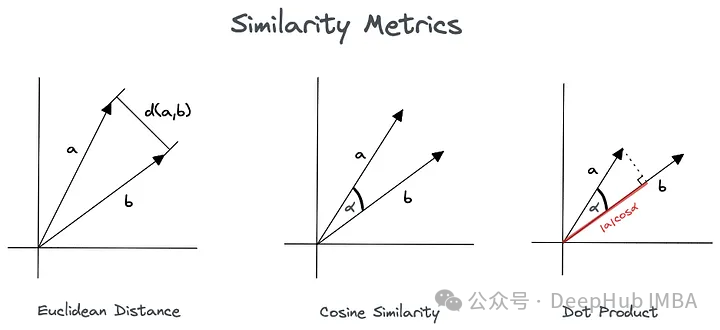
NLP中的嵌入和距离度量
本文将深入研究嵌入、矢量数据库和各种距离度量的概念,并提供示例和演示代码。
LightGBM模型详解
1.背景 LightGBM 是微软开发的 boosting 集成模型,和 XGBoost 一样是对 GBDT 的优化和高效实现,原理有一些相似之处,但它很多方面比 XGBoost 有着更为优秀的表现。官方给出的这个工具库模型的优势如下:更快的训练效率低内存使用更高的准确率支持并行化学习可处理大规模

PyTorch的10个基本张量操作
本文将介绍一些Pytorch的基本张量操作。
SHAP(一):具有 Shapley 值的可解释 AI 简介
这是用 Shapley 值解释机器学习模型的介绍。沙普利值是合作博弈论中广泛使用的方法,具有理想的特性。本教程旨在帮助您深入了解如何计算和解释基于 Shapley 的机器学习模型解释。我们将采取实用的实践方法,使用“shap”Python 包来逐步解释更复杂的模型。这是一个动态文档,作为“shap”
人类大脑与机器学习的对话:认知过程在人工智能中的应用
1.背景介绍人工智能(Artificial Intelligence, AI)是一门研究如何让机器具有智能行为的科学。智能可以被定义为能够处理复杂问题、学习新知识以及适应新环境的能力。人类大脑是一个复杂的神经网络,它能够进行许多高级认知任务,如学习、记忆、推理、决策等。因此,研究人类大脑如何工作,并
AI:122-基于深度学习的电影场景生成与特效应用
随着人工智能技术的不断发展,深度学习作为其中的重要分支在各个领域展现出了强大的应用潜力。电影制作是一个富有创造性和技术挑战的领域,近年来,基于深度学习的电影场景生成与特效应用正逐渐成为行业的热点之一。本文将深入探讨深度学习在电影制作中的应用,特别是在电影场景生成和特效方面的创新。



