
这是谷歌在9月最近发布的一种新的架构 TSMixer: An all-MLP architecture for time series forecasting ,TSMixer是一种先进的多元模型,利用线性模型特征,在长期预测基准上表现良好。据我们所知,TSMixer是第一个在长期预测基准上表现与最先进的单变量模型一样好的多变量模型,在长期预测基准上,表明交叉变量信息不太有益。”
研究人员将TSMixer与各种Transformer模型进行了比较(后者输给了TSMixer)。但是当引入一个令人尴尬的简单线性模型DLinear作为Dynamic Model Selection (DMS), 预测基线进行比较。结果表明,在大多数情况下,DLinear在9个广泛使用的基准测试中也优于现有的基于transformer的解决方案,并且通常有很大的优势,所以目前来看Transformer模型并不太适合时间序列的预测,或者说Transformer可能还没能找到适合时间序列预测的方式(就像以前没人想过VIT能够比CNN更好一样)
所以TSMixer是不是能够更好的进行预测,我们也不知道。但是学习TSMixer的架构和思路是对我们有非常大的帮助的。尤其是这是谷歌发布的模型,肯定值得我们深入研究。
为什么单变量模型胜过多变量模型
这是时间序列预测中最有趣的问题之一。理论上来说多元模型应该比单变量模型更有效,这是很自然的,因为它们能够利用交叉变量信息(更多变量→更深入的见解->更好的预测)。但是在许多常用的预测基准上,基于Transformer的模型可以被证明比简单的单变量时间线性模型要差得多。多变量模型似乎存在过拟合的问题,尤其是当目标时间序列与其他协变量不相关时(在表格数据的深度学习中看到了类似的情况——树胜过深度学习,因为深度学习模型往往受到不相关/无信息特征的影响)。
多元模型的这一弱点导致了两个有趣的问题
1、交叉变量信息真的能为时间序列预测提供好处吗?
2、当交叉变量信息不是有益的,多变量模型仍然可以表现得像单变量模型一样好吗?
当我们考虑到某些重要的预测用例需要处理非常混乱的高维数据时,第二点尤其重要。例如供应链风险预测,必须依靠经济和社会指标的数据来预测安全风险。我们必须进行大量的试验和错误来确定有用的指标(这意味着数据漂移的固有波动性是一个杀手)。对非信息性交叉变量具有鲁棒性的模型对波动性具有更强的鲁棒性——允许更稳定的部署。

当谈到Transformer时,时间序列预测还有另一个缺陷阻碍了他们。在Transformer中多头自我注意力从一件好事变成了一件坏事。
因为Transformer架构的主要工作能力来自于它的多头自关注机制,该机制具有在长序列(例如,文本中的单词或图像中的2D补丁)中提取配对元素之间的语义相关性的显著能力,并且该过程是排列不变的。但是对于时间序列分析,我们主要对一组连续点之间的时间动态建模感兴趣,其中顺序本身通常起着最关键的作用。”
那么,TSMixer如何适应这种情况呢?
TSMixer架构
作者将TSMixer的设计理念描述如下:
在我们的分析中表明,在时间模式的常见假设下,线性模型具有naïve解决方案,可以完美地恢复时间序列或误差的位置边界,这意味着它们是更有效地学习单变量时间序列静态时间模式的解决方案。相比之下,为注意力机制找到类似的解决方案并非易事,因为每个时间步的权重都是动态的。所以我们开发了一个新的架构,将Transformer的注意力层替换为线性层。得到的TSMixer模型类似于计算机视觉的MLP-Mixer方法,在多层感知器的不同方向上交替应用,我们分别称之为时间混合和特征混合。TSMixer体系结构有效地捕获时间模式和交叉变量信息
事实证明,“它们的时间阶跃依赖特征使时间线性模型成为在常见假设下学习时间模式的绝佳候选者。”因此,TSMixer的创建者决定通过两个很酷的步骤来增强线性模型
将时间线性模型与非线性(TMix-Only)叠加——非线性是深度学习模型可以作为通用函数逼近器的秘密,因此这可以更好地建模复杂关系。
引入交叉变量前馈层(TSMixer)——用于处理交叉变量信息。
TSMixer架构看起来像这样
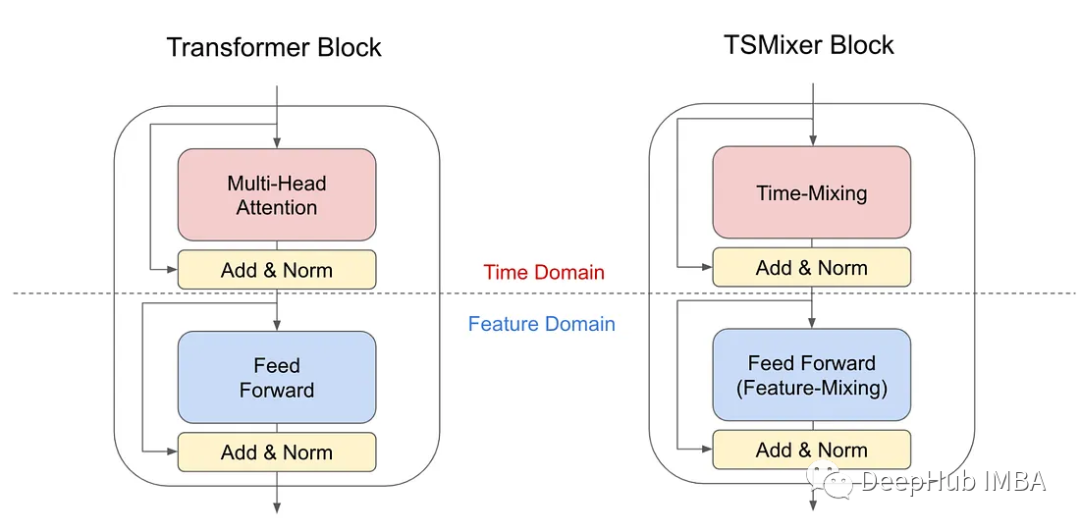
要更详细的展示如下:
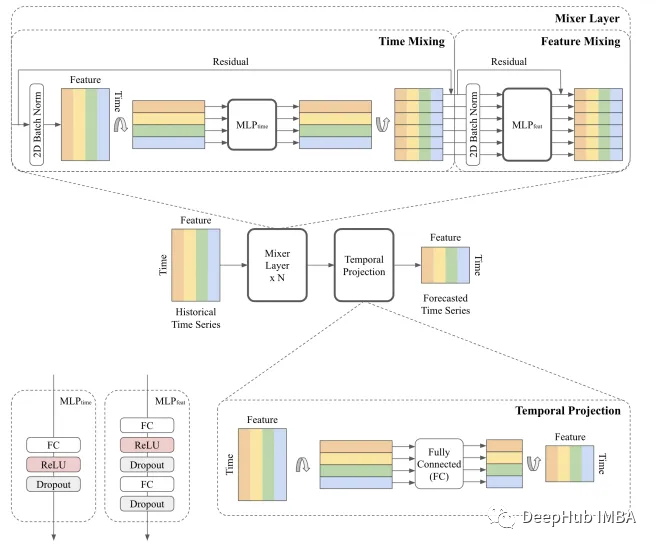
TSMixer用于多变量时间序列预测。输入的列表示不同的特征/变量,行表示时间步长。全连接操作是逐行操作。TSMixer包含交错时间混合和特征混合mlp来聚合信息。混合层数记为n,时间混合mlp在所有特征上共享,特征混合mlp在所有时间步长上共享。该设计允许TSMixer自动适应时间和交叉变量信息的使用,具有有限数量的参数,以获得更好的泛化。
时间混合MLP:时间混合MLP对时间序列中的时间模式进行建模。它们由一个完全连接的层组成,然后是一个激活函数和dropout。它们将输入转置以应用沿时域和特征共享的全连接层。我们采用单层MLP,其中一个简单的线性模型已经被证明是学习复杂时间模式的强大模型。
特征混合MLP:特征混合MLP按时间步共享,用于利用协变量信息。与基于transformer的模型类似,考虑两层mlp来学习复杂的特征转换。
时间投影:时间投影与Zeng et al.(2023)中的线性模型相同,是应用于时域的全连接层。它们不仅学习时间模式,还将时间序列从原始输入长度L映射到目标预测长度T。
残差连接:我们在每个时间混合层和特征混合层之间应用残差连接。这些连接允许模型更有效地学习更深层次的架构,并允许模型有效地忽略不必要的时间混合和特征混合操作。
归一化:归一化是改进深度学习模型训练的常用技术。虽然批归一化和层归一化之间的偏好取决于任务,但Nie等人(2023)证明了批归一化在常见时间序列数据集上的优势。与沿着特征维度应用的典型归一化相比,由于存在时间混合和特征混合操作,我们在时间和特征维度上应用二维归一化。
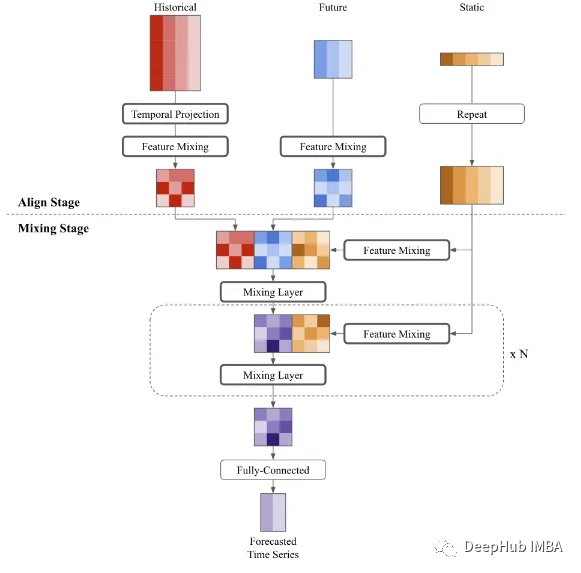
该体系结构相对简单,并且可以扩展到包含辅助信息以获得更深入的预测能力

下图是带有辅助信息的TSMixer。输入的列是特征,行是时间步长。首先对齐不同类型输入的序列长度以将它们连接起来。然后利用混合层对它们的时间模式和交叉变量信息进行联合建模。
结果展示
现在让我们来看看TSMixer的表现如何。研究人员在以下数据集上进行实验
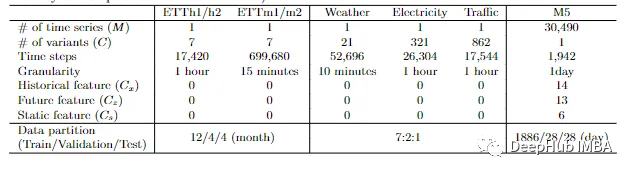
各数据集的统计情况。注意,电力和交通可以被视为多变量时间序列或多个单变量时间序列,因为所有变量在数据集中共享相同的物理含义(比如不同地点的用电量)。
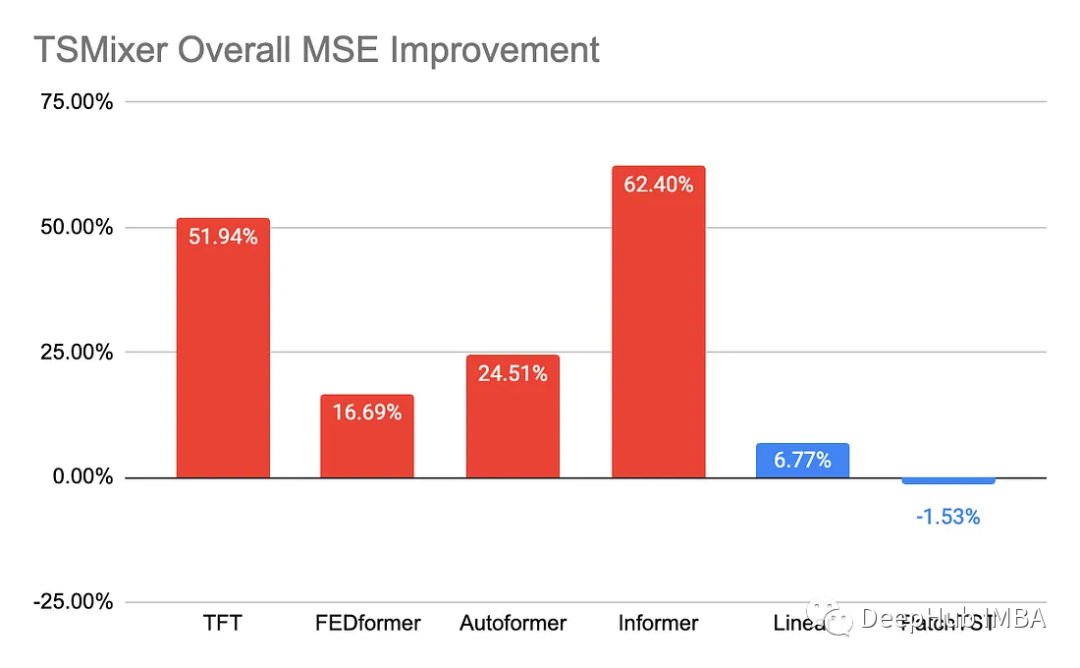
与其他基线相比,TSMixer的平均MSE改善。红条表示多变量方法,蓝条表示单变量方法。与其他多变量模型相比,TSMixer取得了显著的改进,并取得了与单变量模型相当的结果。
这是一些令人印象深刻的结果,但是我们必须再次在这里提出警告。在TSMixer中击Transformers 就等于是矬子里面拔大个儿。这里使用的线性模型是取自《Are Transformers Effective for Time Series Forecasting?》(我们意见着重介绍过)。这篇论文的作者称他们的模型“简单得令人尴尬”,这篇论文的重点是表明Transformers 在时间序列预测是垃圾,而不是说这个(“简单得令人尴尬”的模型)模型是好的。所以这些结果是否证明TSMixer并不坏还是应该持怀疑态度。
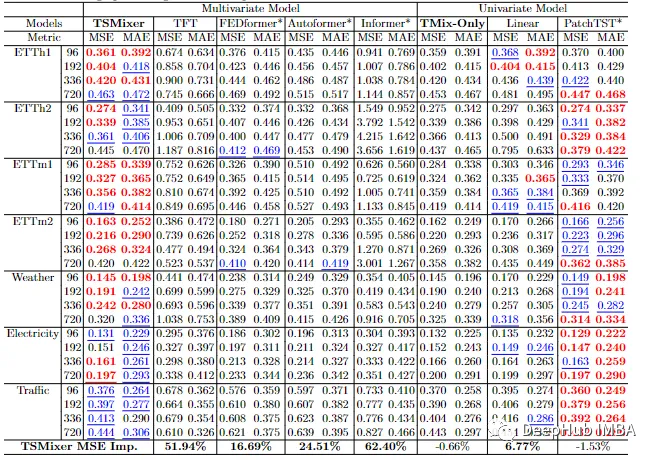
长期预测数据集的评价结果。有“*”标记的型号数目,数据来源于Nie et al.(2023)。每行中最好的数字以粗体显示,第二好的数字以粗体和下划线显示。我们在比较中跳过TMix-Only,因为它的性能与TSMixer相似。最后一行显示了TSMixer相对于其他方法的MSE改进的平均百分比。
总结
我认为它之所以被大肆宣传,是因为它是谷歌的论文,而大肆宣传的人并没有更详细地研究结果(就像国内的自媒体无良炒作是一样的)。
话虽如此,但是我们也不能否认TSMixer的一些创新,比如对多变量模型与单变量模型之间问题的研究,虽然它的解决方案不一定是最好的,但是会给这一研究领域带来巨大的好处。
我不是时间序列预测的专拣,如果你觉得我遗漏了什么请留言指出。
谷歌论文地址:
https://blog.research.google/2023/09/tsmixer-all-mlp-architecture-for-time.html?m=1
再次推荐 Are Transformers Effective for Time Series Forecasting?
https://arxiv.org/abs/2205.13504
作者:Devansh