
系列文章目录
- 手把手带你玩转Spark机器学习-专栏介绍
- 手把手带你玩转Spark机器学习-问题汇总
- 手把手带你玩转Spark机器学习-Spark的安装及使用
- 手把手带你玩转Spark机器学习-使用Spark进行数据处理和数据转换
- 手把手带你玩转Spark机器学习-使用Spark构建分类模型
- 手把手带你玩转Spark机器学习-使用Spark构建回归模型
- 手把手带你玩转Spark机器学习-使用Spark构建聚类模型
- 手把手带你玩转Spark机器学习-使用Spark进行数据降维
- 手把手带你玩转Spark机器学习-使用Spark进行文本处理
文章目录
前言
近年来,数据的不断增长和自然语言处理的日益普及催生了大量的大数据分析和 NLP 工具。最近出现了许多用于各种编程语言的库,并在 NLP 和大数据分析中派上了用场。
Spark是此类大数据工具之一——一种用于大规模数据处理的框架,可用于包括 Python 在内的许多编程语言。PySpark是一个维护良好的用于 Spark 的 Python 包,它允许执行探索性数据分析并为大数据构建机器学习管道。
大量的数据也与 NLP 领域相关,Spark NLP库将大数据和 NLP 两个世界结合在一起。Spark NLP 为各种 NLP 任务提供了广泛的功能,并且可以使用 Spark 快速高效地处理它们。Spark NLP 库为多种语言提供了许多不同的管道和模型,并附带了一个开源实现和详细的文档。
在本篇博客中,我们将跟大家分享NLP任务,即主题建模在大数据中的应用。主题建模是一种用于数据建模的统计方法,有助于发现文档集合中存在的基础主题。尽管 Spark NLP 是用于各种 NLP 任务的出色库,但它们没有提供主题建模管道。因此,我想介绍如何使用 PySpark 和 Spark NLP 实现主题建模。
文章中涉及到的code可到本人github处下载:SparkML
一、第三方库安装
本文需要用到SparkNLP,在进行实验前先安装好SparkNLP:
pip install spark-nlp

如上图所示,我们默认安装最新版本的spark-nlp。
二、获取公开数据集
我们将使用来自Kaggle的开源数据——亚马逊乐器评论数据集。数据不大,但对于本教程来说已经足够了。
1.读取数据
from pyspark.sql import functions as F
path ='Musical_instruments_reviews.csv'
data = spark.read.csv(path, header=True)
2.查看数据列
data.columns

数据中有很多信息,但我们主要对主题建模的评论文本进行实验。我们将使用 PySpark 读取数据,并进行一些数据预处理操作(例如:选择我们感兴趣的列并删除数据中的空评论)。
text_col ='reviewText'
review_text = data.select(text_col).filter(F.col(text_col).isNotNull())

如上图所示,本文我们用来主题建模的数据就是上面一行行的文本。
三、Spark NLP Pipeline
获取到数据后,我们就可以来构建NLP管道了。前面我们安装了Spark NLP。Spark NLP具有很多的NLP功能,现在我们可以使用它进行文本预处理及主题建模了。
从概念上讲,Spark和其他机器学习库类似,都是由两个重要的组件构成:Estimators和Transformers,他们被定义为Annotators【注释器】。这些注解器构成了我们的Pipeline。
大多数Spark NLP的注释器仅支持特定的注释格式,即他们仅以以下形式接受和输出数据:
[annotatorType, begin, end, result, metadata, embeddings]
例如,对于 Spark NLP 中的 Tokenizer,句子“Hello, this is an example sentence”的输出如下所示:
[[token, 0, 4, Hello, [sentence -> 0], [], []],
[token, 5, 5, , [sentence -> 0], [], []],
[token, 7, 10, this, [sentence -> 0], [], []],
[token, 12, 13, is, [sentence -> 0], [], []],
[token, 15, 16, an, [sentence -> 0], [], []],
[token, 18, 24, example, [sentence -> 0], [], []],
[token, 26, 33, sentence, [sentence -> 0], [], []]]
因此,要使用诸如 Normalizer 或 Tokenizer 之类的 Spark NLP 功能,我们必须将我们的数据转换为 Spark NLP 可以理解的注释格式。
DocumentAssembler 会处理这个问题。它从原始文本数据创建注释,允许其他 Spark NLP 注释器在此数据上进一步使用。
要使用 DocumentAssembler,你必须为转换提供输入列,为转换后的数据提供输出列。运行 NLP pipeline后,这些列将保存到新创建的 PySpark data frame中。
from sparknlp.base import DocumentAssembler
documentAssembler = DocumentAssembler() \
.setInputCol(text_col) \
.setOutputCol('document')
正如我们之前可能已经注意到的,注释格式保存了有关注释器类型的信息,这与注释器不同。
DocumentAssembler 创建特定注释器类型的注释数据:DOCUMENT。重要的是注释器不仅输出特定类型的数据,而且还必须接受允许类型的数据。使用 DocumentAssembler,这很容易,因为输入数据只是我们拥有的原始数据。但是,对于其他注释器,这并不是那么简单。
作为我们 NLP pipeline的第一步,我们希望对我们的数据进行标记——将句子拆分为单词。为此,我们将使用 Spark NLP Tokenizer,它使用开放标准进行数据标记化。我们将再次为此注释器仅设置输入和输出列,但 Spark NLP 文档提供了有关每个注释器可用的其他功能的信息。
from sparknlp.annotator import Tokenizer
tokenizer = Tokenizer() \
.setInputCols(['document']) \
.setOutputCol('tokenized')
在这里,会看到我们将来自 DocumentAssembler 的数据输出到新列。在 Spark NLP for Tokenizer 的文档中,您可以看到该注释器仅接受注释器类型 DOCUMENT 的输入数据,并输出 TOKEN 类型的数据。因此,需要注意在 Spark NLP 管道中注释器输入输出的正确类型。这种行为有时会限制你在pipeline中选择下一个注释器的自由,因为所需的注释器可能需要与你有的完全不同的注释器类型。这会让你寻找解决方法。
接下来,我们进入规范化步骤,在这里我们清理数据并执行小写。此步骤由 Normalizer 完成:
from sparknlp.annotator import Normalizer
normalizer = Normalizer() \
.setInputCols(['tokenized']) \
.setOutputCol('normalized') \
.setLowercase(True)
现在我们来进行词形还原——将数据中的所有单词都带入它的引理(基本形式)。 Lemmatizer 注释器负责在 Spark NLP 库中执行词形还原。它允许使用您自己的词形还原字典,但是,我们将使用 LemmatizerModel 提供的预训练模型进行词形还原:
from sparknlp.annotator import LemmatizerModel
lemmatizer = LemmatizerModel.pretrained() \
.setInputCols(['normalized']) \
.setOutputCol('lemmatized')
我们也想过滤掉停用词,因为我们对有意义的词感兴趣来描述我们的主题。这可以通过 StopWordsCleaner 来完成,它会从数据中删除一组选定的单词。为了提供 StopWordsCleaner 的停用词列表,我们从 nltk 包中导入它们:
from nltk.corpus import stopwords
eng_stopwords = stopwords.words('english')
然后我们将此列表提供给 StopWordsCleaner:
from sparknlp.annotator import StopWordsCleaner
stopwords_cleaner = StopWordsCleaner() \
.setInputCols(['lemmatized']) \
.setOutputCol('no_stop_lemmatized') \
.setStopWords(eng_stopwords)
我们完成了主题建模的基本预处理步骤。但是,我想介绍几个额外的步骤,这些步骤可以使我们的主题建模任务受益。除了单词(unigrams)之外,我还建议探索 n-grams。将 n-gram 用于主题建模任务可以帮助主题模型更好地细化主题,并且我们可以更容易地理解提取的主题,因为 n-gram 提供了更多上下文。
要将 n-gram 合并到我们的 NLP pipeline中,我们可以使用 Spark NLP NGramGenerator 从标记生成 n-gram。但是,我们希望将 n-gram 限制为仅有意义的词,例如“乐器”(Adj + 名词),而不是“音乐”(Prep + Adj)。为了避免在 n-gram 中出现不相关的词性 (POS) 标签组合,我们使用 POSTagger 在数据中使用 POS 标签来标记。我们将使用 Spark NLP 中可用的一种 POS 标记模型。
from sparknlp.annotator import PerceptronModel
pos_tagger = PerceptronModel.pretrained('pos_anc') \
.setInputCols(['document','lemmatized']) \
.setOutputCol('pos')
过滤掉没有意义的 n-grams 以后可以使用 Chunker 来完成,该 Chunker 根据提供的 POS 标签模式对数据进行分块。我们将可能的 n-gram 限制为名词短语,但不限制 n-gram 中的 n(n=1 除外,因为我们已经有了 unigram)。
要将处理后的数据用于主题建模分析,我们需要将其从 Spark NLP 的注释格式转换为“人类可读”格式。为此,Spark NLP 提供 Finisher:
from sparknlp.base import Finisher
finisher = Finisher() \
.setInputCols(['unigrams','ngrams'])
到目前为止,我们正在定义 NLP pipeline的组件。现在我们准备创建实际的pipeline。为此,我们将使用内置的 PySpark 功能:
from pyspark.ml import Pipeline
pipeline = Pipeline() \
.setStages([documentAssembler,
tokenizer,
normalizer,
lemmatizer,
stopwords_cleaner,
pos_tagger,
ngrammer,
finisher])
在这一步,我们应该注意 NLP 组件的顺序,并匹配它们所需的输入注释类型。定义管道后,我们可以拟合所有estimators并转换所有 transformers和 estimated模型的数据:
processed_review = pipeline.fit(review_text).transform(review_text)
在我们的pipeline中,我们分别处理 unigrams 和 n-grams,现在我们将它们组合成一个单词列表以用于每个评论。
from pyspark.sql.functions import concat
processed_review = processed_review.withColumn('final',
concat(F.col('finished_unigrams'),
F.col('finished_ngrams')))
处理的数据如下所示: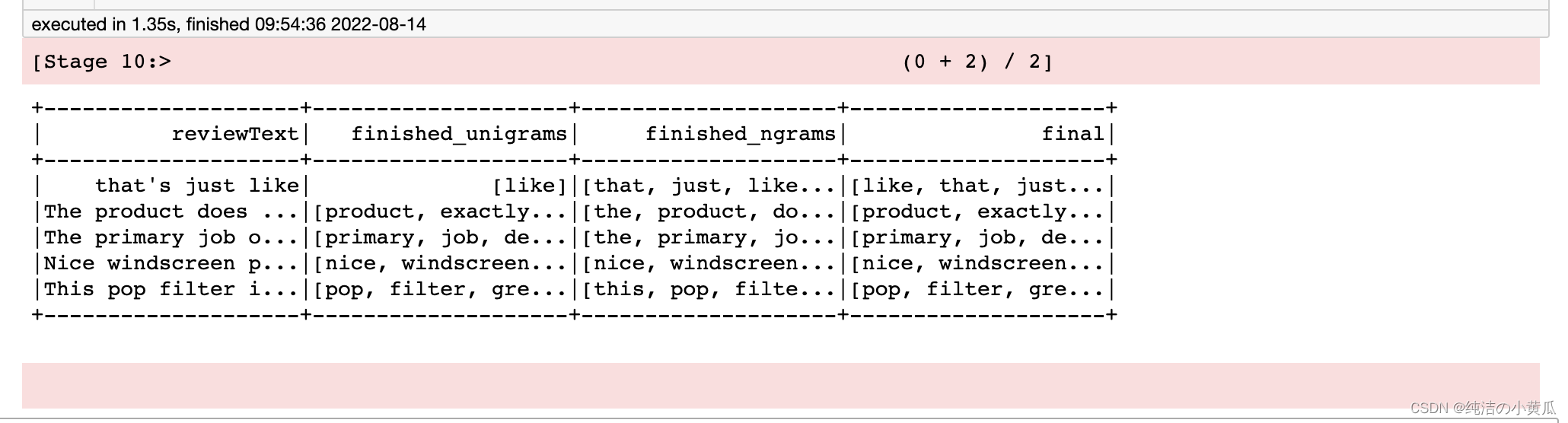
四、使用Spark 对文本进行向量化
在进入主题建模之前,我们需要将文本数据转换为数字数据。 Spark NLP 没有主题建模和非上下文向量化的功能。因此我们可以用Spark NLP来完成文本数字化的过程。
对于主题建模任务,我们将使用 TF-IDF 来确定哪些词对我们的哪些评论很重要。首先,我们将使用 CountVectorizer 计算 TF(文档中每个词的频率)。我们在拟合时导出数据的词汇表,并在转换步骤中获得计数。
from pyspark.ml.feature import CountVectorizer
tfizer = CountVectorizer(inputCol='final', outputCol='tf_features')
tf_model = tfizer.fit(processed_review)
tf_result = tf_model.transform(processed_review)
然后,我们继续使用 IDF(一个词出现的文档的逆频率),这有助于解释在所有评论中出现频率很高的词。这样,这些词将不会在主题建模步骤中表征主题。我们使用 PySpark 的 IDF 估计器基于 TF 结果计算 TF-IDF:
from pyspark.ml.feature import IDF
idfizer = IDF(inputCol='tf_features',
outputCol='tf_idf_features')
idf_model = idfizer.fit(tf_result)
tfidf_result = idf_model.transform(tf_result)
五、使用Spark 进行主题建模
我们将使用最流行的主题建模算法——LDA。它是一种生成模型,它假设文档由主题分布表示,而主题又由单词分布表示。给定词汇的 TF-IDF 分数,LDA 可以识别数据中预定义的主题数量。
PySpark 实现了 LDA 算法。要训练 LDA,我们需要定义主题数和算法迭代次数。
from pyspark.ml.clustering import LDA
num_topics =6
max_iter =10
lda = LDA(k=num_topics,
maxIter=max_iter,
featuresCol='tf_idf_features')
lda_model = lda.fit(tfidf_result)
主题模型训练完成后,我们希望得到描述派生主题的词。为此,我们将编写将单词 id(主题模型的主题的实际输出)转换为单词的 UDF:
vocab = tf_model.vocabulary
defget_words(token_list):return[vocab[token_id]for token_id in token_list]
udf_to_words = F.udf(get_words, T.ArrayType(T.StringType()))
现在,我们可以使用 LDA 模型函数 describeTopics 为每个建模主题输出单词。我们将只显示每个主题的 7 个最相关的词。
num_top_words =7
topics = lda_model
.describeTopics(num_top_words).withColumn('topicWords', udf_to_words(F.col('termIndices')))
topics.select('topic','topicWords').show(truncate=100)

正如你所看到的,有些主题更通用,并且与其他主题共享单词,但有些主题非常有针对性。尝试主题建模的主题数量总是很好,因为你永远不知道什么最适合你的数据。你可能会注意到 n-gram 对主题的贡献不大。在六个主题的热门词中,我们只有一个 n-gram(“shoulder rest”)。
总结
以上就是今天要讲的内容,本文跟大家分享NLP任务,即主题建模在大数据中的应用。同时我们详细的介绍了Spark NLP的使用方法,构建pipeline的方式及文本处理的一些通用流程。
版权归原作者 纯洁の小黄瓜 所有, 如有侵权,请联系我们删除。